計畫簡介
V-Express是由南京大學和騰訊AI實驗室共同開發的一項技術,旨在透過一系列漸進式的控制訊號衰減操作,實作由單張圖片生成講話頭像視訊。這個計畫解決了在肖像視訊生成中控制訊號強度不均的問題,尤其是在使用較弱的音訊訊號時。V-Express透過逐步使弱條件有效控制生成過程,能夠同時考慮姿態、輸入影像和音訊,有效生成由音訊控制的肖像視訊。這種方法為同時有效使用各種強度的條件提供了一種潛在解決方案。
掃碼加入AI交流群
獲得更多技術支持和交流
(請註明自己的職業)

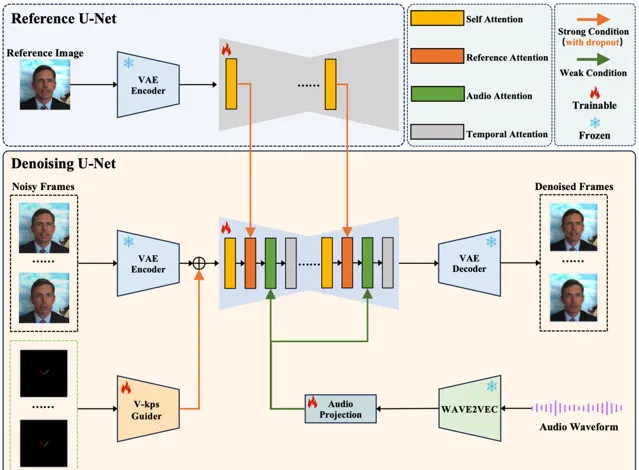
底層技術
在肖像視訊生成領域,使用單張圖片生成肖像視訊的做法越來越普遍。常見的方法包括利用生成模型增強介面卡以實作可控生成。
然而,控制訊號的強度可能不同,包括文本、音訊、影像參考、姿態、深度圖等。在這些中,較弱的條件經常因為較強條件的幹擾而難以發揮效果,這在平衡這些條件中構成了挑戰。
在關於肖像視訊生成的工作中,發現音訊訊號特別弱,常常被姿態和原始影像這些較強的訊號所掩蓋。然而,直接使用弱訊號進行訓練往往導致收斂困難。為了解決這個問題,提出了一種名為V-Express的簡單方法,透過一系列逐步的弱化操作來平衡不同的控制訊號。該方法逐漸使弱條件能夠有效控制,從而實作同時考慮姿態、輸入影像和音訊的生成能力。
使用
重要提醒~
在講話面孔生成任務中,當目標視訊中的人物與參考人物不同時,面部的重新導向將是非常重要的部份。選擇與參考面孔姿勢更相似的目標視訊將能夠獲得更好的結果。
執行演示(第一步,可選)
如果你有目標講話視訊,你可以按照下面的指令碼從視訊中提取音訊和面部V-kps序列。你也可以跳過這一步,直接執行第二步中的指令碼,嘗試提供的範例。
python scripts/extract_kps_sequence_and_audio.py \ --video_path "./test_samples/short_case/AOC/gt.mp4" \ --kps_sequence_save_path "./test_samples/short_case/AOC/kps.pth" \ --audio_save_path "./test_samples/short_case/AOC/aud.mp3"
建議裁剪一個清晰的正方形面部影像,如下面的範例所示,並確保分辨率不低於512x512。下圖中的綠色到紅色框是推薦的裁剪範圍。

執行演示(第二步,核心)
·場景1 (A的照片和A的講話視訊)
如果你有A的一張照片和另一個場景中A的講話視訊,那麽你應該執行以下指令碼。模型能夠生成與給定視訊一致的講話視訊。你可以在計畫頁面上看到更多範例。
python inference.py \ --reference_image_path "./test_samples/short_case/AOC/ref.jpg" \ --audio_path "./test_samples/short_case/AOC/aud.mp3" \ --kps_path "./test_samples/short_case/AOC/kps.pth" \ --output_path "./output/short_case/talk_AOC_no_retarget.mp4" \ --retarget_strategy "no_retarget" \ --num_inference_steps 25
·場景2 (A的照片和任意講話音訊)
如果你只有一張照片和任意的講話音訊。使用以下指令碼,模型可以為固定的面孔生成生動的嘴部動作。
python inference.py \ --reference_image_path "./test_samples/short_case/tys/ref.jpg" \ --audio_path "./test_samples/short_case/tys/aud.mp3" \ --output_path "./output/short_case/talk_tys_fix_face.mp4" \ --retarget_strategy "fix_face" \ --num_inference_steps 25
·場景3 (A的照片和B的講話視訊)
使用下面的指令碼,模型能生成生動的嘴部動作,並伴有輕微的面部動作。
python inference.py \ --reference_image_path "./test_samples/short_case/tys/ref.jpg" \ --audio_path "./test_samples/short_case/tys/aud.mp3" \ --kps_path "./test_samples/short_case/tys/kps.pth" \ --output_path "./output/short_case/talk_tys_offset_retarget.mp4" \ --retarget_strategy "offset_retarget" \ --num_inference_steps 25
使用下面的指令碼,模型可以生成一個視訊,其動作與目標視訊相同,且角色的唇動與目標音訊匹配。
python inference.py \ --reference_image_path "./test_samples/short_case/tys/ref.jpg" \ --audio_path "./test_samples/short_case/tys/aud.mp3" \ --kps_path "./test_samples/short_case/tys/kps.pth" \ --output_path "./output/short_case/talk_tys_naive_retarget.mp4" \ --retarget_strategy "naive_retarget" \ --num_inference_steps 25
·更多參數
對於不同型別的輸入條件,如參考影像和目標音訊,提供了參數來調整這些條件資訊在模型預測中的作用。將這兩個參數稱為 reference_attention_weight 和 audio_attention_weight。
可以使用以下指令碼套用不同的參數以達到不同的效果。透過實驗,建議 reference_attention_weight 取值在 0.9-1.0 之間,而 audio_attention_weight 取值在 1.0-3.0 之間。
在下面的視訊中展示了不同參數產生的不同效果。你可以根據自己的需要相應地調整參數。
安裝
# install requirementspip install diffusers==0.24.0pip install imageio-ffmpeg==0.4.9pip install insightface==0.7.3pip install omegaconf==2.2.3pip install onnxruntime==1.16.3pip install safetensors==0.4.2pip install torch==2.0.1pip install torchaudio==2.0.2pip install torchvision==0.15.2pip install transformers==4.30.2pip install einops==0.4.1pip install tqdm==4.66.1pip install xformers==0.0.22pip install av==11.0.0# download the codesgit clone https://github.com/tencent-ailab/V-Express# download the modelscd V-Expressgit lfs installgit clone https://huggingface.co/tk93/V-Expressmv V-Express/model_ckpts model_ckpts# then you can use the scripts
模型下載
你可以從https://huggingface.co/tk93/V-Express 下載模型。已經在模型卡中包含了所有所需的模型。你也可以從原始倉庫單獨下載模型。
· stabilityai/sd-vae-ft-mse
· runwayml/stable-diffusion-v1-5。這裏只需要unet的模型配置檔。
· facebook/wav2vec2-base-960h
· insightface/buffalo_l
計畫連結
https://github.com/tencent-ailab/V-Express
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點











