原文連結:https://weibo.com/ttarticle/p/show?id=2309634584820058489336
在docker/k8s時代,經常聽到CRI, OCI,containerd和各種shim等名詞,看完本篇博文,您會有個徹底的理解。
典型的K8S Runtime架構
從最常見的Docker說起,kubelet和Docker的整合方案圖如下:
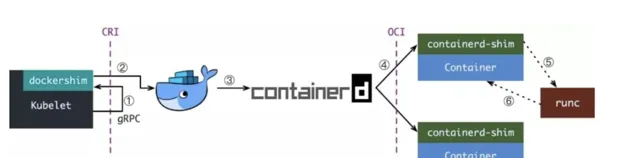
Kubelet 透過 CRI 介面(gRPC)呼叫 dockershim,請求建立一個容器。CRI 即容器執行時介面(Container Runtime Interface),這一步中,Kubelet 可以視作一個簡單的 CRI Client,而 dockershim 就是接收請求的 Server。目前 dockershim 的程式碼其實是內嵌在 Kubelet 中的,所以接收呼叫的湊巧就是 Kubelet 行程;
dockershim 收到請求後,轉化成 Docker Daemon 能聽懂的請求,發到 Docker Daemon 上請求建立一個容器。
Docker Daemon 早在 1.12 版本中就已經將針對容器的操作移到另一個守護行程——containerd 中了,因此 Docker Daemon 仍然不能幫我們建立容器,而是要請求 containerd 建立一個容器;
containerd 收到請求後,並不會自己直接去操作容器,而是建立一個叫做 containerd-shim 的行程,讓 containerd-shim 去操作容器。這是因為容器行程需要一個父行程來做諸如收集狀態,維持 stdin 等 fd 開啟等工作。而假如這個父行程就是 containerd,那每次 containerd 掛掉或升級,整個宿主機上所有的容器都得結束了。而引入了 containerd-shim 就規避了這個問題(containerd 和 shim 並不是父子行程關系);
我們知道建立容器需要做一些設定 namespaces 和 cgroups,掛載 root filesystem 等等操作,而這些事該怎麽做已經有了公開的規範了,那就是 OCI(Open Container Initiative,開放容器標準)。它的一個參考實作叫做 runC。於是,containerd-shim 在這一步需要呼叫 runC 這個命令列工具,來啟動容器;
runC 啟動完容器後本身會直接結束,containerd-shim 則會成為容器行程的父行程,負責收集容器行程的狀態,上報給 containerd,並在容器中 pid 為 1 的行程結束後接管容器中的子行程進行清理,確保不會出現僵屍行程。
這個過程乍一看像是在搞我們:Docker Daemon 和 dockershim 看上去就是兩個不幹活躺在中間劃水的啊,Kubelet 為啥不直接呼叫 containerd 呢?
當然可以,先看下現在的架構為什麽如此繁雜。
容器歷史小敘
早期的k8s runtime架構,遠沒這麽復雜,kubelet建立容器,直接呼叫docker daemon,docker daemon自己呼叫libcontainer就把容器執行起來。
但往往,事情不會如此簡單,一系列政治鬥爭開始了,先是大佬們認為執行時標準不能被 Docker 一家公司控制,於是就攛掇著搞了開放容器標準 OCI。Docker 則把 libcontainer 封裝了一下,變成 runC 捐獻出來作為 OCI 的參考實作。
再接下來就是 rkt(coreos推出的,類似docker) 想從 Docker 那邊分一杯羹,希望 Kubernetes 原生支持 rkt 作為執行時,而且 PR 還真的合進去了。維護過一塊業務同時接兩個需求方的讀者老爺應該都知道類似的事情有多坑,Kubernetes 中負責維護 kubelet 的小組 sig-node 也是被狠狠坑了一把。
大家一看這麽搞可不行,今天能有 rkt,明天就能有更多幺蛾子出來,這麽搞下去我們小組也不用幹活了,整天搞相容性的 bug 就夠嗆。於是乎,Kubernetes 1.5 推出了 CRI 機制,即容器執行時介面(Container Runtime Interface),Kubernetes 告訴大家,你們想做 Runtime 可以啊,我們也資瓷歡迎,實作這個介面就成,成功反客為主。
不過 CRI 本身只是 Kubernetes 推的一個標準,當時的 Kubernetes 尚未達到如今這般武林盟主的地位,容器執行時當然不能說我跟 Kubernetes 綁死了只提供 CRI 介面,於是就有了 shim(墊片)這個說法,一個 shim 的職責就是作為 Adapter 將各種容器執行時本身的介面適配到 Kubernetes 的 CRI 介面上。
接下來就是 Docker 要搞 Swarm 進軍 PaaS 市場,於是做了個架構切分,把容器操作都移動到一個單獨的 Daemon 行程 containerd 中去,讓 Docker Daemon 專門負責上層的封裝編排。可惜 Swarm 在 Kubernetes 面前實在是不夠打,慘敗之後 Docker 公司就把 containerd 計畫捐給 CNCF 縮回去安心搞 Docker 企業版了。
最後就是我們在上一張圖裏看到的這一坨東西了,盡管現在已經有 CRI-O,containerd-plugin 這樣更精簡輕量的 Runtime 架構,dockershim 這一套作為經受了最多生產環境考驗的方案,迄今為止仍是 Kubernetes 預設的 Runtime 實作。
OCI, CRI
OCI(開放容器標準),規定了2點:
容器映像要長啥樣,即 ImageSpec。裏面的大致規定就是你這個東西需要是一個壓縮了的資料夾,資料夾裏以 xxx 結構放 xxx 檔;
容器要需要能接收哪些指令,這些指令的行為是什麽,即 RuntimeSpec。這裏面的大致內容就是「容器」要能夠執行 「create」,「start」,「stop」,「delete」 這些命令,並且行為要規範。
runC 為啥叫參考實作呢,就是它能按照標準將符合標準的容器映像執行起來,標準的好處就是方便搞創新,反正只要我符合標準,生態圈裏的其它工具都能和我一起愉快地工作(……當然 OCI 這個標準本身制定得不怎麽樣,真正工程上還是要做一些 adapter 的),那我的映像就可以用任意的工具去構建,我的「容器」就不一定非要用 namespace 和 cgroups 來做隔離。這就讓各種虛擬化容器可以更好地參與到遊戲當中,我們暫且不表。
而 CRI 更簡單,單純是一組 gRPC 介面,掃一眼 kubelet/apis/cri/services.go 就能歸納出幾套核心介面:
一套針對容器操作的介面,包括建立,啟停容器等等;
一套針對映像操作的介面,包括拉取映像刪除映像等;
一套針對 PodSandbox(容器沙箱環境)的操作介面,我們之後再說。
現在我們可以找到很多符合 OCI 標準或相容了 CRI 介面的計畫,而這些計畫就大體構成了整個 Kuberentes 的 Runtime 生態:
OCI Compatible:runC,Kata(以及它的前身 runV 和 Clear Containers),gVisor。其它比較偏門的還有 Rust 寫的 railcar
CRI Compatible:Docker(借助 dockershim),containerd(借助 CRI-containerd),CRI-O,Frakti,etc
OCI, CRI 確實不是一個好名字,在這篇文章的語境中更準確的說法:cri-runtime 和 oci-runtime。透過這個粗略的分類,我們其實可以總結出整個 Runtime 架構萬變不離其宗的三層抽象:
Orchestration API -> Container API(cri-runtime) -> Kernel API(oci-runtime)
根據這個思路,我們就很容易理解下面這兩種東西:
各種更為精簡的 cri-runtime(反正就是要幹掉 Docker)
各種「強隔離」容器方案
Containerd和CRI-O
上一節看到現在的 Runtime 實在是有點復雜了,而復雜是萬惡之源(其實本質上就是想幹掉 Docker),於是就有了直接拿 containerd 做 oci-runtime 的方案。當然,除了 Kubernetes 之外,containerd 還要接諸如 Swarm 等排程系統,因此它不會去直接實作 CRI,這個適配工作當然就要交給一個 shim 了。
containerd 1.0 中,對 CRI 的適配透過一個單獨的行程 CRI-containerd 來完成:

containerd 1.1 中做的又更漂亮一點,砍掉了 CRI-containerd 這個行程,直接把適配邏輯作為外掛程式放進了 containerd 主行程中:

但在 containerd 做這些事情前,社群就已經有了一個更為專註的 cri-runtime:CRI-O,它非常純粹,就是相容 CRI 和 OCI,做一個 Kubernetes 專用的執行時:
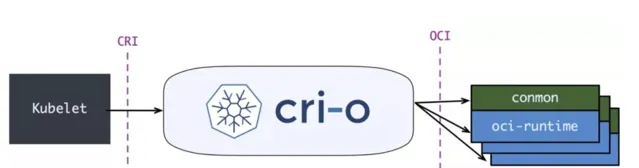
其中 conmon 就對應 containerd-shim,大體意圖是一樣的。
CRI-O 和(直接呼叫)containerd 的方案比起預設的 dockershim 確實簡潔很多,但沒啥生產環境的驗證案例,我所知道的僅僅是 containerd 在 GKE 上是 beta 狀態。因此假如你對 Docker 沒有特殊的政治恨意,大可不必把 dockershim 這套換掉。
強隔離容器:Kata,gVisor,Firecracker
一直以來,K8S都難以實作真正的多租戶。
理想來說,平台的各個租戶(tenant)之間應該無法感受到彼此的存在,表現得就像每個租戶獨占這整個平台一樣。具體來說,我不能看到其它租戶的資源,我的資源跑滿了不能影響其它租戶的資源使用,我也無法從網路或內核上攻擊其它租戶。
Kubernetes 當然做不到,其中最大的兩個原因是:
kube-apiserver 是整個集群中的單例,並且沒有多租戶概念
預設的 oci-runtime 是 runC,而 runC 啟動的容器是共享內核的
對於第二個問題,一個典型的解決方案就是提供一個新的 OCI 實作,用 VM 來跑容器,實作內核上的硬隔離。runV 和 Clear Containers 都是這個思路。因為這兩個計畫做得事情是很類似,後來就合並成了一個計畫 Kata Container。Kata 的一張圖很好地解釋了基於虛擬機器的容器與基於 namespaces 和 cgroups 的容器間的區別:
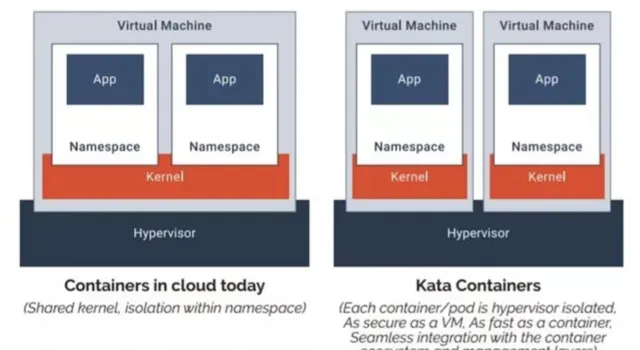
嗯,一個 VM 裏跑一個容器,聽上去隔離性很不錯,但不是說虛擬機器又笨重又不好管理才切換到容器的嗎,怎麽又要走回去了?
Kata 告訴你,虛擬機器沒那麽邪惡,只是以前沒玩好:
不好管理是因為沒有遵循「不可變基礎設施」,大家都去虛擬機器上這摸摸那碰碰,這台裝 Java 8 那台裝 Java 6,Admin 是要 angry 的。Kata 則支持 OCI 映像,完全可以用上 Dockerfile + 映像,讓不好管理成為了過去時;
笨重是因為之前要虛擬化整個系統,現在我們只著眼於虛擬化套用,那就可以裁剪掉很多功能,把 VM 做得很輕量,因此即便用虛擬機器來做容器,Kata 還是可以將容器啟動時間壓縮得非常短,啟動後在記憶體上和 IO 上的 overhead 也盡可能去最佳化。
不過話說回來,Kubernetes 上的排程單位是 Pod,是容器組啊,Kata 這樣一個虛擬機器裏一個容器,同一個 Pod 間的容器還怎麽做 namespace 的共享?
這就要說回我們前面講到的 CRI 中針對 PodSandbox(容器沙箱環境)的操作介面了。第一節中,我們刻意簡化了場景,只考慮建立一個容器,而沒有討論建立一個 Pod。大家都知道,真正啟動 Pod 裏定義的容器之前,kubelet 會先啟動一個 infra 容器,並執行 /pause 讓 infra 容器的主行程永遠掛起。這個容器存在的目的就是維持住整個 Pod 的各種 namespace,真正的業務容器只要加入 infra 容器的 network 等 namespace 就能實作對應 namespace 的共享。而 infra 容器創造的這個共享環境則被抽象為 PodSandbox。每次 kubelet 在建立 Pod 時,就會先呼叫 CRI 的 RunPodSandbox 介面啟動一個沙箱環境,再呼叫 CreateContainer 在沙箱中建立容器。
這裏就已經說出答案了,對於 Kata Container 而言,只要在 RunPodSandbox 呼叫中建立一個 VM,之後再往 VM 中添加容器就可以了。最後執行 Pod 的樣子就是這樣的:
說完了 Kata,其實 gVisor 和 Firecracker 都不言自明了,大體上都是類似的,只是:
gVisor 並不會去建立一個完整的 VM,而是實作了一個叫 「Sentry」 的使用者態行程來處理容器的 syscall,而攔截 syscall 並重新導向到 Sentry 的過程則由 KVM 或 ptrace 實作。
Firecracker 稱自己為 microVM,即輕量級虛擬機器,它本身還是基於 KVM 的,不過 KVM 通常使用 QEMU 來虛擬化除 CPU 和記憶體外的資源,比如 IO 裝置,網路裝置。Firecracker 則使用 rust 實作了最精簡的裝置虛擬化,為的就是壓榨虛擬化的開銷,越輕量越好。
往期推薦

點亮,伺服器三年不宕機











