作者 |
FaceChain
投稿
責編 | 夏萌
在人工智慧領域,AIGC 技術透過深度學習和大量數據的訓練,已能夠生成高度逼真的影像、視訊和音訊等內容,從而極大地豐富了數位媒體的多樣性。影像生成、語音合成等技術取得了巨大的進展,基於此說話人臉生成任務成為了一個備受關註的研究領域。

由bing.create生成
說話人臉生成旨在透過輸入文本或語音資訊,自動生成與之對應的人臉影像,並使其呈現出說話時的動態表情和口型變化。這一任務不僅具有極高的實用價值,如在電影制作、虛擬角色設計、遊戲開發等領域中的套用,同時也對人工智慧領域的技術發展提出了新的挑戰和機遇。
隨著 AIGC 技術的不斷進步,說話人臉生成任務也取得了顯著的成果。透過結合深度學習演算法、電腦視覺技術和語音處理技術,研究人員能夠構建出更加精準、高效的人臉生成模型。這些模型不僅能夠根據輸入的文本或語音資訊生成靜態的人臉影像,還能夠實作動態的口型變化和表情生成,使得生成的人臉影像更加生動、自然。
然而,盡管說話人臉生成任務已經取得了顯著的進展,但仍然存在一些挑戰和問題。例如:
如何確保生成的人臉影像在保持真實性的同時,又具有足夠的多樣性和個人化;
如何進一步提高生成模型的效率和穩定性;
如何更好地結合語音和文本資訊來生成更加精準的人臉影像等。
因此,未來的研究工作將致力於解決這些問題,並推動說話人臉生成任務在更多領域的套用和發展。 我們有理由相信,說話人臉生成任務將為我們帶來更加豐富多彩的數位世界和更加智慧的人機互動體驗。
音訊驅動的多樣化動態說話人臉生成任務
本文提出了一個新的說話人臉生成任務,即直接從音訊中想象出符合音訊特征的多樣化動態說話人臉,而常規的該任務需要給定一張參考人臉。具體來說,該任務涉及到兩個核心的挑戰,首先如何從音訊中解耦出說話人的身份(性別、年齡等語意資訊以及臉型等結構資訊)、說話內容以及說話人傳遞的情緒,其次是如何根據這些資訊生成多樣化的符合條件的視訊,同時保持視訊內的一致性。
為了解決上述問題,我們首先挖掘了三個人臉相關要素之間的聯系,設計了一個漸進式音訊解耦模組,以此降低解耦難度,並且提高了各個解耦因子的準確性。對於第二個挑戰,我們基於 Latent DIffusion Models (LDMs) 提出了一個可控一致幀生成模組,因此繼承了 LDMs 的多樣化生成能力,並設計了相應模組將音訊中的資訊準確的表達在生成的動態人臉上,緩解了 LDMs 可控性差的局限。充分的定量和定性實驗證明了 FaceChain-ImagineID 可以有效且靈活地實作提出的新任務。
動機
當人們沒有面對面交流時,當聽到對方的聲音時,往往會腦補出相應的畫面,對方是一個怎麽樣的人,在說什麽話,說話的情緒怎麽樣,我們將這個現實場景抽象為 Listening and Imagining。
為了實作這個新的任務,直接使用現有技術有以下兩個問題:一個是如何從復雜的音訊中解耦出人臉相關的各個因子。我們首先分析了音訊和人臉之間的天然聯系:
明顯的下巴和突出的眉脊通常伴隨著低沈的聲音;
女性和兒童的音調通常更高;
說話內容和局部的嘴唇運動有關系;
說話情緒和人臉的全域運動有關系。
目前的研究要麽只關註了說話內容和情緒,要麽只關註了身份資訊,並沒有方法能夠準確地從音訊中解耦以上三個特征。另一個僅僅用一個網路既能實作視訊間的多樣化,又能保證視訊內的一致性。
人的想象力是無窮的,同一段音訊我們可以想象出很多符合條件的說話人視訊,而視訊內又是連貫。其中一個方式是將 LDMs 和 SadTalker 等主流說話人生成進行結合,另一個是借助 text-to-video 框架,但是前者涉及到兩個獨立的模型,往往不能達到最優的效果,而後者很難實作完全的可控,並且這些方法都沒有考慮音訊資訊。所以,一個新的框架來適配這個任務顯得尤為重要。
方法
1.兩個模組的主圖如下
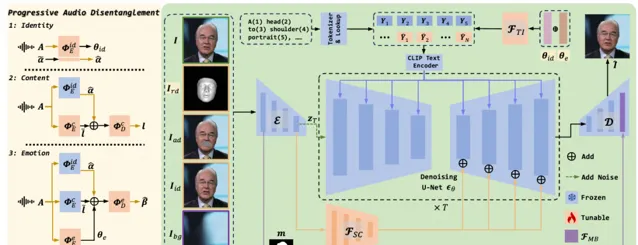
2.漸進式音訊解耦模組
該模組使用 3DMM 作為先驗,並采用漸進式的方式逐步解耦每一個因子。我們設定身份,內容,以及情緒作為解耦順序,其內部的邏輯在於身份相對獨立,內容僅僅和嘴巴運動相關,情緒和全域面部運動相關,遵循了簡單到復雜,局部到整體的邏輯。具體的,我們先從身份編碼器中編碼身份語意,並預測人臉結構相關的形狀系數。接下來,我們將身份編碼凍結,引入可訓練的內容編解碼器,其中融合了第一階段輸出的形狀系數,預測得到表情無關的僅僅和嘴巴運動相關的系數。最後,將身份和內容編碼器凍結,引入新的可訓練的情緒編解碼器,其中融合了前面兩個階段輸出的身份和內容特征,預測完整的表情系數,同時提供解耦的情緒表征。
3.可控一致幀生成模組
為了滿足多樣化的生成,LDMs 是一個很好的結構。但是作為交換,它在可控生成方面相對較弱。想要不引入兩個離線模組來實作多樣且一致的說話人臉生成,我們需要解決兩個問題,一個是在不犧牲多樣化生成的基礎上,即凍結 LDMs,怎麽保證生成的視訊內容和給定的條件對齊,第二個是怎麽實作幀間的平滑過度,實作高度的時序平滑。針對第一個問題,我們設計了以下三個模組:
a.Textual Inversion Adapter
該模組負責將語音中推理得到的身份和情緒語意特征,它的核心是 inversion 技術,其將輸入的語意特征對映到 CLIP 域的 word tokens,兩者合並後輸入到 CLIP 文本編碼器得到最終的表征,該表證透過 cross attention 的方式註入到UNet主網路。
b.Spatial Conditional Adapter
該模組負責將顯式的空間條件註入到主網路,它的核心借鑒了 T2I-Adapter。首先 3D Mesh 包含了音訊對齊的人臉結構資訊,即臉型,嘴唇運動以及表情風格,另外隨機采樣一張同源的參考圖片提供人臉的外觀以及背景,上述兩個條件對常規方法已經足夠了,但是對於凍結的 LDMs,很難學習很復雜的運動。因此我們進一步引入了嘴巴區域掩蓋的相鄰幀來提供運動資訊,從而降低了形變的學習難度,掩蓋嘴巴的目的是防止網路走捷徑。
c.Masked-guided Blending Adapter
該模組負責保證生成視訊的背景一致性,它主要作用在 VAE 中。具體的,我們將 VAE decoder 的人臉區域特征和 VAE encoder 的背景區域特征進行融合,由膨脹的 mask 作為引導。我們只在 512 分辨率上進行該操作,此時上線了最優的背景一致以及融合邊緣的和諧。
以上闡述了設計的可控一致幀生成模組包含了變化的以及不變的生成能力,我們進一步的將其和自回歸長視訊生成機制 Autoregressive Inference 進行結合。如下演算法圖所示,對於第一幀生成,我們將可控一致幀生成模組為變化的模式,即只接收從音訊中推理得到的身份語意和身份結構。對於接下來的幀,我們切換為不變的模式,進一步的將參考人臉、相鄰幀以及背景圖融入進來,從而實作一致的長視訊生成。其中參考人臉固定為第一幀,背景圖也是從第一幀中提取的。

實驗
1.與 SOTA 相比
我們和 SOTA 方法進行定性和定量比較。具體的,首先和最近的 audio-to-face 方法 CMP,如下圖所示,我們的結果有更準確的幾何結構,包括臉型,嘴唇運動,情緒風格,以及更真實的紋理。
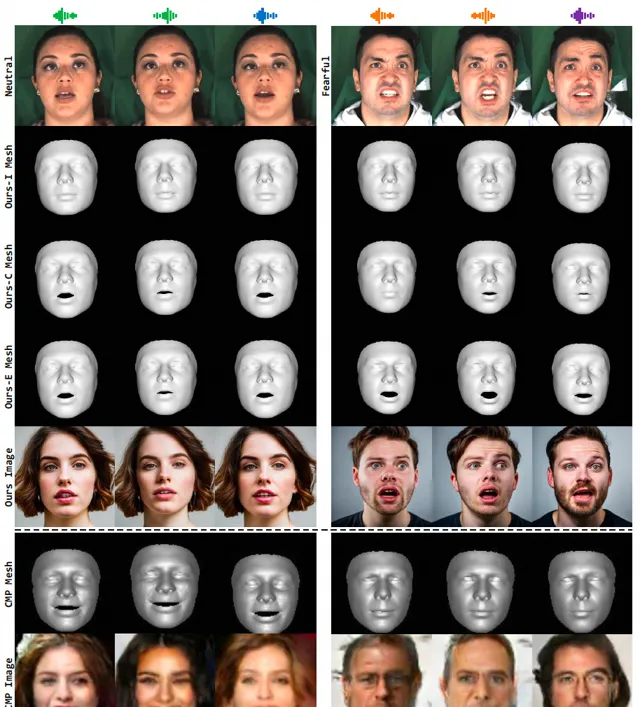
其次和主流的說話人生成方法 Wav2Lip,PC-AVS,EAMM,以及 SadTalker,我們的方法也表達出了更準確的表情、更好的音畫一致性以及更高的視訊品質。

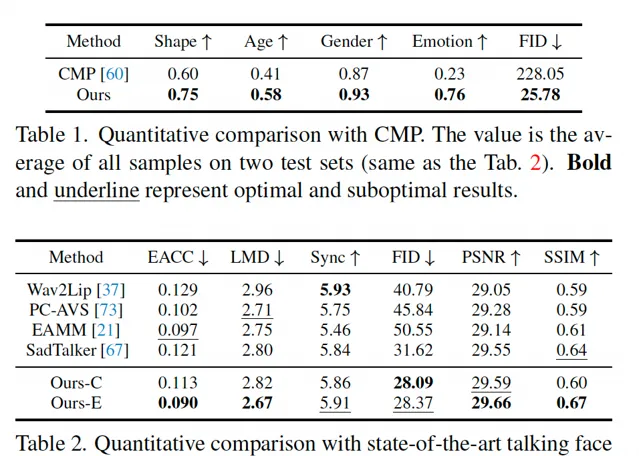
對應的定量實驗見下表:
2.分析性實驗
如下圖所示,為了驗證人臉各個元素的解耦性,我們采樣了兩張人臉,並且將兩者對應的說話內容,身份語意以及情緒風格進行交換,可以看到我們的方法可以改變期望改變的因子而保持其他的因子不變。

進一步的,我們做了定性實驗來證明身份解耦的合理性。我們隨機采樣了四個音訊,其中涵蓋不同的性別和年齡,並且根據身份語意檢索數據集中最相近的幾個視訊,如下圖所示,檢索得到的視訊和查詢的視訊有接近的性別和年齡。為了驗證情緒解耦的效果,我們視覺化了情緒語意的 t-sne 圖,可以看到不同的情緒之間遠離,而同一個情緒聚集在特定區域。


論文

論文:FaceChain-ImagineID: Freely Crafting High-Fidelity Diverse Talking Faces from Disentangled Audio, https://arxiv.org/abs/2403.01901
相應程式碼後期會開源到FaceChain開源計畫











