整理 | 王啟隆
出品 | CSDN
「 幻覺 」( Hallucination ),現在已經是大語言模型領域無人不知、無人不曉的熱詞。我們在和 ChatGPT 等聊天機器人對話的時候, 有時 會遇到生成式人工智慧根據提示詞生造出一些事實的情況。通俗點說,就是現在的 AI 都有機率「說胡話」,聊著聊著就和你侃大山,答非所問。

張飛哭暈在廁所
最近,一篇關於幻覺問題的論文就在 Hacker News 上引起了激烈討論,很多開發者聊著聊著就聊到了哲學問題上:

而這篇論文的標題也非常具有沖擊性——【 幻覺不可避免:大型語言模型的內在局限性 】( Hallucination is Inevitable: An Innate Limitation of Large Language Models ),作者是隸屬於新加坡國立大學計算學院的 Ziwei Xu, Sanjay Jain 和 Mohan Kankanhalli。這篇論文試圖證明大語言模型( LLMs )中的幻覺無法完全消除,即使采用現有的幻覺緩解方法也無法完全解決。
論文連結:https://arxiv.org/abs/2401.11817v1

如今,大模型廠商各顯神通, 幻覺緩解手段也是層出不窮; 而 對於嚴重依賴於模型輸出的決策場景,如醫療診斷、法律咨詢等領域,開發者會采取更為保守的方法,限制模型在高風險情境下的自主生成行為,或者在必要時直接拒絕回答不確定的問題。
但是,如果幻覺真的無法避免,那我們以後豈不是要盼著機率過日子?接下來,讓我們一起解讀這篇論文,看看幻覺背後隱藏的真相究竟是什麽。
到底什麽是幻覺?
盡管現有研究從數據、訓練及推理等角度揭示了大模型產生幻覺的多種原因,但關於徹底消除幻覺的可能性尚無定論。這一核心問題對於理解大模型能力的潛在極限至關重要,而由於無法窮盡所有可能輸入進行測試,僅憑經驗方法難以解答。
於是,論文作者著手正式定義幻覺,並論證了 在大模型中完全消除幻覺實際上是不可能的 。他們構建了一個形式化的框架,其中幻覺被界定為大模型與真實世界可計算函式間的不一致。透過結合學習理論成果,作者展示大模型無法學習全部可計算函式,因而必定會出現幻覺。
考慮到實際世界的復雜性遠超形式化世界,此結論同樣適用於現實生活中的大模型。此外,針對受時間復雜度限制的現實大模型,文章提出了易於誘發幻覺的任務例項,並透過實驗證據加以支撐。最後,基於形式化框架,作者探討了現有緩解幻覺策略的內在機制及其對大模型安全有效部署的實際影響。
幻覺的基本概念與定義
幻覺在心理學和神經科學中通常指的是個體在沒有外部刺激的情況下感知到不存在的事物。在大語言模型的背景下,幻覺被定義為模型生成的與事實不符或毫無意義的資訊。這種現象在模型的輸出中表現為虛假但聽起來合理的陳述,引發了對安全性和倫理的擔憂。
幻覺在大型語言模型中的具體表現
在大模型中,幻覺的表現可以歸類為 內在幻覺 和 外在幻覺 。
內在幻覺發生在模型的輸出與提供的輸入相矛盾時,例如與提示資訊不符。
外在幻覺則發生在模型的輸出無法透過輸入中的資訊進行驗證。
此外,幻覺還可以透過使用者指令的不一致性來分類,包括指令性、上下文性和邏輯性不一致。這些幻覺可能源於數據收集、訓練和推理過程中的多種問題,如啟發式數據收集、固有偏差、不完美的表示學習、錯誤的解碼、暴露偏差和參數知識偏差。
用數學定義現實世界!
在探究大模型的幻覺傾向時,研究者們首先 形式化 定義了整個世界 ,其中幻覺被定義為電腦可實作的大模型與可計算的真實函式之間的不一致性。實驗的目的是驗證大 模型是否能夠學習所有可計算的函式,從而總是產生與真實函式一致的輸出,即是否能完全避免幻覺。
一言以蔽之,就是 用數學來解釋幻覺 。實驗中,研究者們利用學習理論的結果,證明了 大模型無法學習所有可計算的函式,因此總會產生幻覺 。
定義 1(字母表和字串) : 字母表A 是一個包含 N 個標記的 有限集合A ={a0, a1, ..., aN-1}。 字串 是透過 n 次連線標記得到的序列 w0, w1...wn-1。
定義 2(大模型) :設 S 為 字母表A 上所有有限長度字串的 可計算集合b ,(s0, s1, ...)為其元素的一一對應列舉。 大模型h 被記為一個函式,能在有限時間內使用 預測令牌h(s) 完成 輸入字串s∈S 。 函式h 透過一系列輸入-完成對的訓練樣本程式性地獲得。
定義 3(P 驗證的大模型) :設 P 為一個可計算演算法,當函式具有特定內容(例如全可計算性或多項式時間復雜度)時返回「真」,則 P 驗證的大模型 是按定義 2 所述的大模型,可以在有限步驟內被 P 證明具有該特定內容。
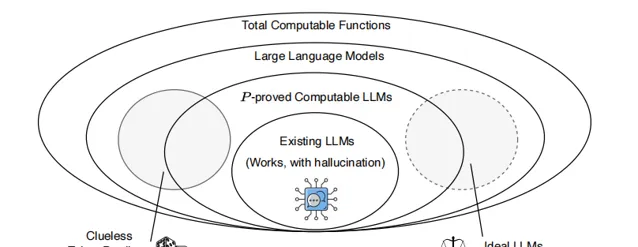
根據定義 3,P 可證明的大模型構成了所有大模型的一個真子集。作者將大模型視為全體可計算函式的一個子集。與一般的全體可計算函式不同,大模型可以根據其輸出結果的合理性程度劃分為一個連續譜。在「nonsensical」(無意義)一端是一個無感知的標記預測器,它會產生對輸入字串s的無意義補全;而在「ideal」(理想)一端,則是一個無幻覺函式,能夠將任何結構良好的輸入字串補充為合理且真實的文本。「ideal」一端以虛線表示,因為 它表明任何大模型都無法達到這樣的理想狀態,因此不在大模型集合之內。
在這兩者之間是現實世界的大模型:它們的輸出大多數時候是可以理解的,但偶爾會發生「幻覺」,生成非事實性的陳述。這種譜系關系以及大模型與全體可計算函式 之間的聯系在上圖中得以展現。
在形式化世界中,幻覺被定義為大模型輸出與 ideal 正確結果之間的不匹配。在這個世界裏,存在一個可計算的真值函式 f,它對所有輸入字串 s∈S 都能產生唯一正確的補全 f(s)。
形式化世界的定義如下:
定義 4(形式化世界 f) :對於給定的 真值函式f ,其 形式化世界Gf ={(s, f(s)) | s ∈ S} 是一個集合,其中對於任意輸入 字串s ,f(s) 是唯一的正確補全結果。
訓練樣本 T 則是一組從形式化世界中獲得的輸入-輸出配對。
定義 5(訓練樣本 T) : 訓練樣本T 是一個集合 {(s0, y0),(s1, y1), ..., (si, yi), ... | si ∈ S, i ∈ N, yi = f(si)}。這個集合代表了 真值函式f 對輸入字串如何回應或完成的概括。
當訓練好的大模型 h 未能完全復制真值函式 f 的輸出時,我們稱該模型相對於 f 發生了幻覺。
定義 6(幻覺) :若存在 s∈S 使得 h(s) ≠ f(s),則模型相對於 真值函式f 出現幻覺。
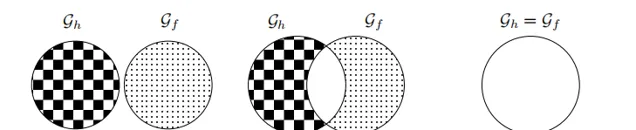
基於此定義,幻覺不再與真實世界中的正確性或真實性直接相關,而是指大模型 Gh 所構建的形式世界與其對應的真值函式 Gf 形式世界之間的不一致性。Gh 和 Gf 之間可能存在以下三種關系:
完全幻覺:Gh ∩ Gf = ∅,即大模型在所有 s∈S 上均發生幻覺。
部份幻覺: Gh ∩ Gf ≠ ∅且Gh ≠ Gf,即大模型在部份 s∈S 上發生幻覺。
無幻覺: Gh = Gf,表示大模型是針對 f 而言無幻覺的理想模型。
緊接著開始訓練大模型。
定義 7(基本問題) :對於任何給定的 真實值函式f ,是否可以透過使用 訓練樣本集T 來訓練一個 大模型h ,使其滿足對於所有 s∈S,都有 h(s) = f(s)?
定義 8(大模型的訓練與部署) : 大模型h 透過以下可計算實作的步驟進行訓練和部署。
輸入: 一系列無限或者大量且連續流入的 訓練樣本流T ,表示為 T = ((s0, f(s0)), (s1, f(s1)), ...),其中每個樣本對由 字串si 和其對應的 真值函式f(si) 組成。
輸出: 經過訓練後的 大模型h[i] ,期望該模型在某次叠代 i∈N 時能夠近似或等同於 f。
訓練過程:將大模型初始化為參數隨機分布的模型,記為 h[0]。設定 叠代計數器i 為 0。
訓練與驗證叠代:(a) 如果達到停止準則(即模型已準備好),則結束當前叠代。(b) 從 訓練樣本流T 中取出一對 樣本數據(si, f(si)) 。(c) 根據至今為止的所有樣本 {(sj , f(sj )) | j ≤ i} 更新 大模型h[i] 至 h[i+1]。(d) 讓 叠代計數器i 遞增,即 i ← i + 1,並返回繼續訓練。
部署階段:將最終訓練得到的 模型h[i] 作為 最終模型h 進行部署,並結束整個訓練程式。

如上圖所示, 插圖(a) 展示了現實世界的語料庫,它包含了 (b)形式化世界 中 真值函式f 及其 訓練樣本T 的所有內容。在 (c)部份,展示了根據定義 8 訓練 大模型h 的過程,該過程透過使用訓練樣本不斷更新模型,直到達到停止準則為止。最後,在 (d)部份,經過訓練的大模型被部署,並針對未見過的 字串s 生成輸出結果。幻覺的定義是透過比較大模型生成的 答案h(s) 與 真實值f(s) 來實作 的。
實驗結果表明, 無論模型架構、學習演算法、提示技術或訓練數據如何,大模型在形式化世界中總是不可避免地會產生幻覺 。由於形式化世界是真實世界的一部份,這一結果也適用於真實世界中的大模型。此外,實證研究表明, 即使是最先進的大模型,在某些真實世界問題中也傾向於產生幻覺 ,這驗證了理論結果的有效性。
無法徹底解決的幻覺,應該如何緩解?
目前,減輕大模型幻覺的方法主要依據兩大原則: 提升大模型的能力,並透過訓練樣本或歸納偏置向大模型提供更多有關真實世界的知識 。例如,可以透過增大模型參數和訓練數據量來增強大模型的復雜性,或者采用基於檢索的技術、提示策略以及新的解碼方法來減少幻覺現象。然而,這些措施都有其局限性,比如在大模型無法捕捉到真實世界函式時,單純增加參數和數據是無效的。
盡管有多種嘗試減輕幻覺的手段,但已有研究指出,在形式化世界中,大模型不可避免地會產生幻覺,這意味著在現實世界中也無法完全根除幻覺。因此,未來的研究路徑可能包括更深入探索幻覺的本質特征、如何控制和降低幻覺的程度,以及研發能夠檢測並糾正幻覺的外部知識庫與推理工具。此外,對大模型安全邊界的探究對於確保大模型的持續健康發展至關重要。

圖源:AIGC
在實際套用中,大模型在關鍵決策支持方面存在一定的局限性。由於大模型在處理某些問題時會產生幻覺,即生成看似合理但實際上並不準確或無意義的資訊,這種現象在關鍵決策過程中可能導致嚴重後果。例如,在醫療診斷、金融風險評估或法律咨詢等領域過度依賴大模型的輸出,可能會導致錯誤的判斷和決策。
大模型的幻覺現象還可能對社會倫理產生潛在影響。由於大模型生成的內容可能包含偏見、誤導資訊或不準確的事實,這些輸出可能會誤導公眾,影響社會觀念和行為。例如,在生成新聞摘要或歷史事件描述時,大模型可能會無意間傳播錯誤資訊,從而扭曲人們對事件的理解和記憶。此外,在創作文學作品或藝術創意時,大模型可能會生成獨特但非真實的素材,盡管在某些情況下這被視為創新,但也可能引發關於版權、原創性和真實性的爭議。
然而, 這篇論文揭示出幻覺問題是大模型內在固有的,無法完全消 除 。因此,未來的研究將更多地關註如何減輕幻覺現象的影響,並探討如何在確保安全和可靠性的前提下充分利用大模型的優勢。
4 月 25 ~ 26 日,由 CSDN 和高端 IT 咨詢和教育平台 Boolan 聯合主辦的「 全球機器學習技術大會 」將在上海環球港凱悅酒店舉行,特邀近 50 位技術領袖和行業套用專家,與 1000+ 來自電商、金融、汽車、智慧制造、通訊、工業互聯網、醫療、教育等眾多行業的精英參會聽眾,共同探討人工智慧領域的前沿發展和行業最佳實踐。 歡迎所有開發者朋友存取官網 http://ml-summit.org、點選「閱讀原文」或掃碼進一步了解詳情。












