文 | 王啟隆
出品 | 【 】編輯部
隨著諸如 ChatGPT 之類的生成式 AI 工具的迅速普及,越來越多人開始猜測蘋果公司在 AI 時代的未來動向 : 是端出 iOS 版的對話式人工智慧? 還是革新智慧語音助手 Siri?
昨晚, ,CEO 提姆·庫克宣布,此次釋出將是 iPad 歷史上的重要裏程碑。在蘋果的一系列宣傳中,除了「最薄 iPad」,最引人矚目的便是蘋果推出的最新 M4 芯片 :它搭載蘋果最強大的神經引擎,每秒執行 38 萬億次操作,比 A11 Bionic 的首代神經引擎快 60 倍,被譽為「 極端強大的 AI 芯片 」,只需 M2 一半的功耗即可提供相同效能,且在 AI 處理能力上超越當前任何 PC 神經處理單元。

庫克曾經如此評價過 AI:它們會嵌入到我們制造的每一個產品中。現在看看蘋果在 AI 領域的一系列動作,特別是 Ferret、HUGS、MM1、ReALM 等論文的釋出,我們會發現蘋果的戰略方向仍是「軟硬體的結合」, 在資源有限的行動裝置上高效部署大型語言模型,是實作 AI 技術大眾化套用的關鍵 。
WWDC 還有一整月才會亮相,本文將簡單回顧蘋果這半年的各種動向作為前瞻,讓我們一起看看蘋果將怎麽逐步構建一個以 AI 為驅動的全新生態系。
Siri——改造它還是「生二胎」?
2023 年 5 月,提姆·庫克(Tim Cook)在蘋果的 財報電話會議上 表示,人工智慧有「 許多問題需要解決 」,重要的是「 在開發方法上要 深思熟慮 」,並計劃 繼續 在深思熟慮的基礎上將 AI 融入到產品中 。
實際上早在 2019 年 ,蘋果就組建了專註於對話 式 AI 的團隊, AI 部門主管約翰·詹南德裏亞( John Giannandrea )在 公司內部領導著 大 語言模型的研發,他的工作 直接向蘋 果 CEO 提姆·庫克匯報。 但直到 OpenAI 釋出 ChatGPT 之前,這個團隊一直沒傳出過什麽訊息,可謂是起了個大早、趕了個晚集。
時間回到 2023 年, 彭博社專職報道蘋果科技新聞的記者馬克·古爾曼(Mark Gurman)透露, AI 研發在蘋果內部被賦予高度優先級 ,公司設計了一套名為「 Ajax 」的大型語言模型框架。當時的新聞表示 Ajax 相較於 ChatGPT 3.5 在能力上有所超越,且已基於超過 2000 億參數進行訓練( 雖然從今天的角度來看已經不怎麽樣了 )。事實是,OpenAI 隨後釋出的 GPT-4 模型就已超越 Ajax 泄露出的紙面數據。
這段時期的蘋果對於如何面向消費者推出生成式 AI 產品尚無清 晰策略。
2023 年 9 月,外媒 The Information 首次曝光了蘋果 AI 研發的種種細節:
蘋果在對話式人工智慧的研究上 每日投入數百萬美元 ,因為訓練語言模型需龐大硬體支持。
核心團隊只有 16 人 。
核心目標之一是 讓 Siri 能夠執行多步驟任務 。

團隊核心成員也相繼曝光
:
John Giannandre ,前文提及的這位領導者其實是蘋果公司的機器學習和 AI 戰略高級副總裁。
Daphne Luong ,蘋果特意從谷歌挖來的 AI 高管。
Arthur Van Hoff ,他曾從事 Java 程式語言的早期開發工作,傳聞中 Java 名字中的那個「v」就來自於他。
Ruoming Pang ,2021 年加入蘋果,擅長神經網路研究。
蘋果在生成式 AI 領域的探索,有望最終融入 Siri 語音助手。
負責 2014 年改進 Siri 的前蘋果工程師 John Burkey 曾如此批評這款語音助手:Siri 「基於笨拙的程式碼構建」,其「累贅的設計」使得工程師很難添加新功能,即使是最基本的功能更新也需要數周時間。比如,Siri 的資料庫包含接近二十多種語言的大量短語列表,形成一個「大雪球」。因此,Burkey 認為, Siri 最終無法成為像 ChatGPT 那樣的人工智慧助手 。

John Burkey
蘋果公司的研究人員一直在研究「 無需使用喚醒詞即可使用 Siri 」的方法,也就是讓語音助手「憑直覺」判斷機主是否正在與其交談,而不是聆聽「嘿 Siri」或「Siri」。2023 年 10 月份,蘋果的研究人員發表了一篇論文研究喚醒詞的這個問題:

論文地址: https://arxiv.org/pdf/2310.16990
這篇論文旨在讓 Siri 設法弄清你什麽時候在問一個後續問題,什麽時候在問一個新問題。它利用 LLM 來更好地理解所謂「 模棱兩可的詢問 」,無論你怎麽說,它都能猜出你的意思。
文中寫道:「 在不清楚對話者的意圖時, 智慧對話代理可能需要「 主動出擊 」,透過主動 提出好問題來減少不確定性,從而更有效地解決問題。 」
除了 Siri 的問題,蘋果本身還需要解決另一項大麻煩。2023 年年底,Keivan Alizadeh 等人釋出了一篇論文,針對現代自然語言處理領域核心的大型語言模型(LLMs)進行了研究。他們要解決的問題是當今的一大挑戰: 怎麽把動輒千億參數的這些 AI 大模型塞到小小的 iPhone 裏面?

論文地址: https://arxiv.org/pdf/2312.11514
他們的研究透過細致設計的系統策略,著力於最小化在模型推斷階段從快閃記憶體到裝置有限 DRAM 資源的數據遷移負擔。核心在於構建一個與快閃記憶體特性和操作機制緊密配合的推理成本模型,籍此雙管齊下最佳化數據處理流程:一方面,減少數據在快閃記憶體與 DRAM 間往返的總量;另一方面,最佳化數據讀取模式,傾向於更大規模和更高連貫性的數據塊讀取操作。
研究團隊創新性地推出了兩項關鍵技術: 「視窗化」策略 ,這種方法聰明地復用近期推理中已啟用的數據,減少不必要的重復載入;以及 「行列捆綁」技術 ,透過智慧組織數據的儲存布局,使得每次從快閃記憶體提取的數據塊更為龐大且讀取連續,尤其適合快閃記憶體介質的讀取特性。在蘋果自家 M1 Max CPU 平台上實施這些技術,與常規的數據載入方案對比,推理效率實作了顯著的 4 至 5 倍躍升;而轉移到 GPU 環境,這一效率提升更是激增到 20 至 25 倍,成效斐然。
未來展望中,這些最佳化技術的實裝,或將很快賦能諸如 iPhone、iPad 以及其他行動裝置,使復雜的 AI 助手和聊天機器人在這些平台上的執行變得絲滑無阻。如今看來,M4 芯片的釋出或許就是蘋果端側 AI 的最後一塊墊腳石。
除此之外, 蘋果欲將生 成式 AI 引入行動裝置,可能還需要解決私密問題。從 Siri 的歷史可以看出, 蘋果素來對私密保護持審慎態度,這種決策雖使 Siri 在功能性上略遜於 Alexa、Google 助手等競品,卻彰顯了其對使用者私密的重視。
「 百模大戰 」時期的蘋果:封閉,還是開源?
2023 年 10 月份,蘋果悄然釋出了 Ferret 開源多模態大型語言模型 。這篇論文相當不得了,同時包含了「蘋果」「開源」以及「全華班」幾大元素——沒錯,論文的作者全是華人。

論文地址: https://arxiv.org/pdf/2310.07704
開源地址: https://github.com/apple/ml-ferret
這篇論文介紹的多模態模型 Ferret 能夠理解和處理影像中任意形狀或粒度級別的空間參照,並 準確地對開放詞匯描述進行定位 。其核心創新在於它采用了一種新穎且強大的混合區域表示方法,這種方法將離散座標與連續特征結合起來,共同表征影像中的某個區域。這不僅融合了傳統上分開處理的參照(referring)和定位(grounding)任務,還在 LLM 的框架內實作了兩者的統一。
為了提取不同區域的連續特征,蘋果提出了一種空間感知的視覺采樣器。這種采樣器擅長處理不同形狀間變化的稀疏性,使得 Ferret 能夠接受多樣化的區域輸入形式,包括點、邊界框以及自由形態的形狀。這一設計顯著 增強了模型處理復雜視覺資訊的能力 。
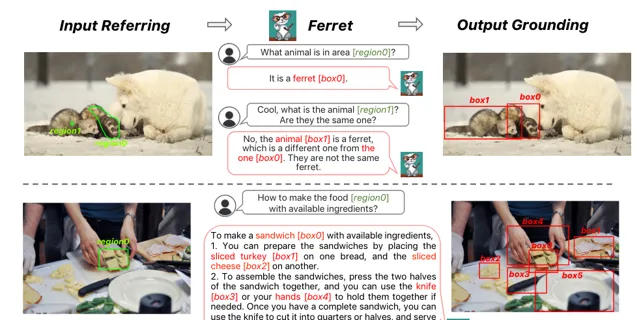
為了強化 Ferret 的這些特有能力,研究團隊還精心構建了 GRIT 數據集,這是一個全面的參照與定位指令微調數據集,包含 110 萬個樣本,這些樣本富含層次化的空間知識,並特別加入了 9.5 萬個困難負例數據來增強模型的穩健性。GRIT 數據集的設計旨在透過豐富的訓練例項,促進模型在理解和生成基於空間關系的多模態指令方面的表現。
實驗結果顯示,Ferret 不僅在經典的參照和定位任務上取得了卓越的效能,在基於區域的以及需要精確定位的多模態對話任務上,其表現更是 遠超當時的其他多模態大語言模型 。
評估還揭示了 Ferret 在描述影像細節方面的顯著提升,以及在減少臭名昭著的「 幻覺 」(hallucination)現象上的明顯改善。這意味著 Ferret 不僅能更準確地理解和生成與影像內容相關的語言描述,還能在描述過程中減少不準確或不存在資訊的引入,從而提高了生成內容的真實性和可靠性。
盡管 Ferret 公布材料含程式碼與權重(僅供科研,無商用授權),導致初時並未引發廣泛關註,但隨著開源 Mistral 模型近期炙手可熱, 小型裝置上本地 LLMs 的套用潛能日益受到矚目 。 蘋果宣布在 iPhone 上實作 LLM 部署的重大突破後,討論熱度也是隨之驟增。
當時引起了 Hacker News 三百多條的評論
2023 年底伴隨而來的一項研究報告還揭示了蘋果最新的 HUGS(Human Gaussian Splats)技術,旨在 從單鏡頭短視訊中創制軔態 3D 虛擬形象,提供更為沈浸的視覺體驗 。論文一作 Muhammed Kocabas 還曾放言:「 我們的方法可以從一段單鏡頭短視訊(50 - 100 幀)中自動區分靜態場景與全動畫虛擬形象,整個過程僅需 30 分鐘。 」


論文地址: https://arxiv.org/pdf/2311.17910
HUGS 借助高效的 3D 高斯斑點渲染技術,同步展現主體與背景。人體模型依托 SMPL(統計形體模型),HUGS 憑借高斯形變捕獲衣物、發型等細微之處。一新型神 經變形模組借力線性混合蒙皮技術,使高斯動態表現更為真實,避免了擺姿調整中的視覺扭曲。
相比早期虛擬形象生成手段,HUGS 在訓練和渲染速度上快至 100 倍 ,僅需 30 分鐘即可在標準遊戲 GPU 上最佳化出逼真的效果。在 3D 重建品質方面,HUGS 也超越了諸如 Vid2Avatar 和 NeuMan 等最先進技術。
此項創新讓使用者僅憑一段含人物與場景的視訊,即可將各式數位角色或「虛擬形象」置入新情境,以每秒 60 幀的速率重新整理,呈現流暢逼真的效果。
蘋果的一系列 AI 技術釋出——尤其是開源多模態模型的舉動,直接給許多業內人士送上了一份驚喜。專註於醫療領域開源 AI 的歐洲非營利組織負責人 Bart de Witte 當時在 X 平台上贊揚蘋果:「不知怎的,我錯過了這個訊息。蘋果在 10 月份加入了開源 AI 行列。 Ferret 的問世,彰顯了蘋果致力於有影響力的 AI 研究的決心,並鞏固了其在多模態 AI 領域的領頭羊地位……我對將來本地大型語言模型(LLLMs)作為 iOS 新設計一部份執行於 iPhone 上充滿期待。 」
德國 AI 音樂藝術家及顧問 Tristan Behrens 在 Linkedin 上寫道:「聖誕節提前到來,但你知道嗎?蘋果(沒錯,就是蘋果!)最近釋出了一個包含程式碼和權重的多模態大型語言模型。」
科技博主 Ben Dickson 曾就這一驚喜發表意見:「2023 年最讓你驚訝的 AI 發展是什麽?對我來說,是蘋果釋出了開源 LLM(雖然是非商業授權的)。」他指出,蘋果歷來堅持封閉系統、保密、嚴格的保密協定,甚至對微小創新也會嚴格申請專利。
他接著說:「但回過頭看, 蘋果 (像 Meta 一樣)釋出開源 LLM 模型是有道理的。要與像 ChatGPT 這樣的模型競爭,要麽你得有台超級電腦,要麽得有強大的合作夥伴。 雖然蘋果資源豐富,但其基礎設施並不適合支持大規模 LLMs 。另一個選擇是依賴像微軟或谷歌(兩大競爭對手)這樣的雲服務提供商,或者像 Meta 那樣開始釋出自己的開源模型。」
回顧完 2023 年的「舊聞」,再來看目前蘋果對於戰略合作的最新動向:2024 年 3 月彭博社曾報道,蘋果正與谷歌探討 在 iOS 18 中整合 Gemini AI 引擎的可能性 。蘋果意在獲取谷歌大型語言模型的授權,但具體條款與品牌命名尚未敲定。
此外,蘋果還正開發基於裝置的 AI 新功能,同時尋求擁有強大硬體基礎的合作夥伴以支持雲端生成式 AI 套用,如根據提示生成影像和編寫文章,但目前並無開發 ChatGPT 風格聊天機器人的計劃。
除谷歌外,蘋果今年亦 與 OpenAI 接洽,探討如何在 iOS 18 中運用 OpenAI 技術 。在中國市場,蘋果同樣於三月份引起過一波熱議,也就是先前傳聞的和百度的合作:

到了今年四月份,蘋果尋求與照片分享服務網站 Photobucket 達成協定, 利用其超過 130 億份影像和視訊資料訓練 AI 模型 ,並已從 Shutterstock 購得數百萬張圖片授權。
蘋果的生成式 AI 藍圖徐徐鋪開,一切皆待下個月的 WWDC24 大會正式揭曉。當前, 幾乎每家大型科技企業均有 AI 產品籌備中。 除 OpenAI 的 ChatGPT 以外,國際知名的谷歌、微軟、亞馬遜等大廠都蓄勢待發:
谷歌 :推出了 Bard 和 Gemini。已將生成式 AI 融入搜尋產品與套用,而 Bard 還與 Google Flights、地圖、Drive 等服務整合。
微軟 :前腳 與 OpenAI 合作, 。將 ChatGPT 融 入自家 Bing 搜尋引擎,並擁有 Copilot AI 套用。
亞馬遜 :努力透過生成式 AI 改進國外火爆的 Alexa 語音助手。
Meta :釋出了開源模型 LLaMA 造福世界,坐擁 AI 教父楊立昆,準備今年下半年再釋出 LLaMA-3 的最強版本。此外,還將生成式 A I 融入多款套用,如 WhatsApp 和 Messenger 和 Instagram。
透明到底不妥協
如果說去年的蘋果還讓人有些難以捉摸,那今年全面專攻 AI 的蘋果可謂是大顯身手了。2 月份, 在「 造車 」與「 AI 」兩條截然不同的賽道上,蘋果毅然決定取消搞了十多年的電動車計畫 ,引得樂視創始人 賈躍亭 點評:
同一時間段釋出的 VisionPro 亦是爭議滿滿,但由於本文主講 AI,便不再深入,等待六月份蘋果的進一步更新。
很快來到 3 月,蘋果並沒有閑著,而是紮出了一記利槍: 。30 多位研究員,且和前文提到的 Ferret 大模型一樣,華人含量極高。

論文地址: https://arxiv.org/pdf/2311.17910
MM1 繼承了 Ferret 的理念,在論文中直接指出當前眾多 AI 公司在 AI 模型的學習方法上有著「不透明性」的痛點。大多數的模型對於他們所使用的演算法設計選擇的過程幾乎沒怎麽進行公開,而今年爆火的 多模態預訓練 更是如此。為了在多模態這條賽道跑下去,蘋果釋出了這篇論文,完整記載了模型的構建過程。
當時還引起了輝達研究科學家 Jim Fan 的吐槽:
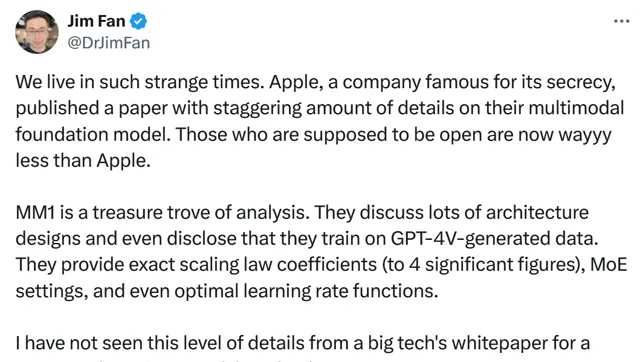
我們正處在一個如此奇特的時代。
蘋果,一家以保密著稱的公司,竟然發表了一篇關於其多模態基礎模型的論文,其中包含了令人震驚的詳盡細節。 那些本應更加開放的公司,如今在這方面反而遠不如蘋果透明。 MM1(假設這是蘋果模型的代號)是一座分析的寶庫。他們討論了許多架構設計方面的問題,甚至透露他們使用了 GPT-4V 生成的數據進行訓練。他們提供了精確到四位有效數位的縮放定律系數、MoE(專家混合網路)設定,乃至最優學習率函式等資訊。
我已經很久很久沒有在大型科技公司的白皮書中看到過如此詳盡的內容了。 蘋果真的回來了!(Apple's so back!)
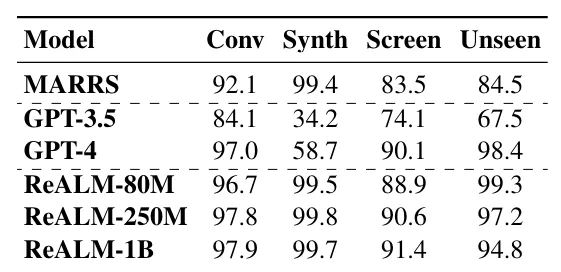
三月底,蘋果再發力作,推出 ReALM 框架 ,附帶四款神秘的超小參數模型,效能直逼 GPT-4。

論文地址: https://arxiv.org/pdf/2311.17910
ReALM 對抗了曾經「參數量即王道」的普遍認知,在不依賴於模型規模的持續膨脹下,透過演算法和架構創新達到與當前頂尖模型如 GPT-4 相當的效能。其中,參數最「大」的 30 億參數 LLM 在標準對話數據集中達到了 97.9% 的準確率,在合成數據集上則達到了 99.8% 的準確率;在涉及螢幕上的實體參照解析任務上,3B LLM 達到了 93.0% 的準確率;在未知領域,如警報系統的測試中,該模型依然保持了 97.8% 的準確率,與 GPT-4 的表現相近。
ReALM 對 Siri 最顯著的強化在於上下文理解的升級,它可以掌握諸如「再次播放那首歌」或「給她打電話」等參考資訊 ,甚至預測使用者的需求和偏好,根據過去的行為和上下文理解建議或啟動操作。
2011 年推出 Siri 時,蘋果曾一度走在語音助手創新的前沿,適應著全球使用者的需求。時間一點點推進,Siri 逐漸變成大家所調侃的「人工智障」,其未來形態也成為了本次 WWDC 2024 被關註的焦點。
庫克曾在今年二月的股東大會上曾用一個詞形容蘋果的 AI 計劃:「 break new ground 」——開辟新天地。 最晚進場的蘋果,這次是姍姍來遲 還是伺機待發? 此刻,你心中或許已經有了答案。











