整理 | 鄭麗媛
出品 | CSDN(ID:CSDNnews)
在這場曠日持久的百模大戰中,不僅各家大模型在極致內卷,大模型排行榜的評測標準也在不斷叠代。
目前,Hugging Face 的開源大模型排行榜(Open LLM Leaderboard)是大模型領域最具權威性的榜單,它收錄了全球上百個開源大模型——本周三, Hugging Face 宣布推出新版開源大模型排行榜 (Open LLM Leaderboard):「成績已趨於平穩,那就讓排行榜再次陡峭起來吧!」
在這個更具挑戰性的排行榜中,昨日 Hugging Face 的聯合創始人兼執行長 Clem 在 X 上宣布: 阿裏最新開源的 Qwen2-72B 指令微調版 (Qwen2-72B-Instruct) ,力壓科技巨頭 Meta 的 Llama-3 和法國著名大模型平台 Mistralai 的 Mixtral, 成為新版開源模型排行榜第一名 。
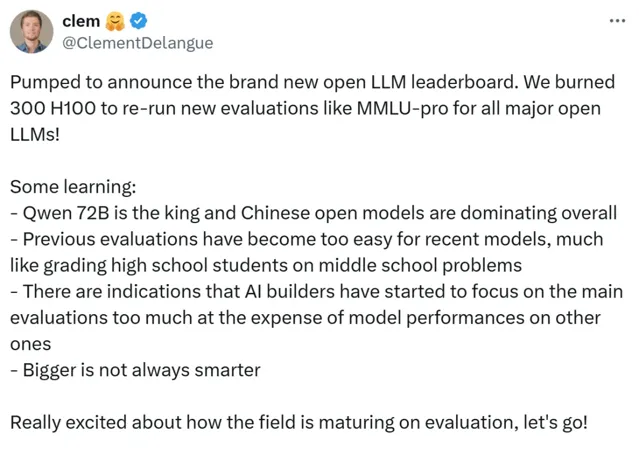
很高興宣布全新的開源大模型排行榜。 我們燒掉了 300 個 H100,重新對所有主流開源 LLM 進行了新的評估 ,如 MMLU-pro!
我們發現:
- Qwen 72B 仍是王者,中國的開源模型在整體上占主導地位 ;
- 以前的評估對最近的模型來說太容易了,就像用初中問題給高中生打分一樣;
- 有跡象表明,AI 構建者開始過於關註主要評估,而忽略了模型在其他評估上的表現;
- 更大並不一定更聰明。
「徹底改變評估方式」,推出開源大模型排行榜 v2!
開源大模型排行榜誕生之前,Hugging Face 的 RLHF 團隊經歷了很艱難的一段時間:想要重現和比較幾個已釋出模型的結果,但發現這幾乎是一項不可能完成的任務——很多論文和行銷文中對模型的評分,都是在沒有任何可重現程式碼的情況下給出的,難以復現。
因此,RLHF 團隊決定以完全相同的設定(相同的問題、相同的提問順序等)對參考模型進行評估,以收集完全可重復和可比較的結果——這就是 Hugging Face 開源大模型排行榜的誕生過程。
據 Hugging Face 統計, 在過去 10 個月中超過 200 萬人存取過這個榜單,每月有近 30 萬人以不同方式在使用它 ,主要是為了:
(1)尋找最先進的開源模型。因為排行榜提供了可復現的分數,可以把市場宣傳與實際表現區分開來。
(2)評估自己的工作。無論是預訓練還是微調,用公開的方法與現有的最佳模型進行比較,以此贏得公眾的認可。
但近一年時間下來,Hugging Face 發現隨著模型效能不斷提高,原來那套評測基準有點不夠用了。首先 這套基準已被過度使用,對許多模型來說沒有太大難度 ,其次有 部份模型就是用這套基準數據或與其非常相似的數據上訓練出來的,評測結果可能不公平 ,最後 有一些評測基準還存在錯誤需要糾正 。
基於以上原因,Hugging Face 決定「徹底改變評估方式」,推出開源大模型排行榜 v2!
Qwen2-72B 第一名的位置仍然不變
根據 Hugging Face 博文介紹,新版開源大模型排行榜具有無汙染、高品質數據集的新基準,使用可靠的度量標準並測量有趣的模型功能。為此,Hugging Face 決定用以下 6 個基準來涵蓋測評任務:MMLU-Pro、GPQA、MUSR、MATH、IFEval 和 BBH。
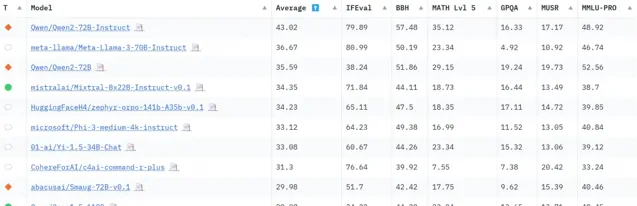
從新版開源大模型排行榜來看, 盡管每個大模型的綜合評分都因新評測基準有不同程度的降低,但 Qwen2-72B 第一名的位置仍然不變 。
可以看到,Qwen2-72B-Instruct 這六項基準的平均分最高,其中 MATH 和 BBH 這兩項評分第一:
MATH 是一份從多個來源收集的中高級競賽題匯總,且 Hugging Face 只保留了最難的問題,用 Latex 來處理方程式,用 Asymptote 來處理數位,要求輸出必須符合非常特定的統一格式。在數學方面,得益於大規模且高品質的數據, Qwen2-72B-Instruct 的數學解題能力大幅提高 ,盡管測評難度提升也達到了 35.12 分, 相較於 Qwen1.5-110B 提高了 12 分, 比知名開源模型 Llama3-70B 也高出了將近 12 分 。
BBH 是 BigBench 數據集中 23 個挑戰性任務的一個子集,這些任務包括:1)使用客觀指標;2)難度大,因為語言模型的效能最初沒有超過人類基準;3)包含足夠多的樣本以具有統計意義。它們包含多步驟算術和演算法推理(理解布爾運算式、幾何圖形的 SVG 等)、語言理解(諷刺檢測、名稱消歧等)和一些世界知識。整體而言, BBH 上的表現與人類偏好密切相關——Qwen2-72B-Instruct 在方面達到了 57.48 的高分 。
另外, 在 GPQA 和 MMLU-Pro 這兩項上,Qwen2-72B 也奪得第一,平均分位於總榜第三 :
MMLU-Pro 是 MMLU 數據集的改進版,品質更高、難度更大。過去 MMLU 一直是多選知識的參考數據集,但最近研究表明該數據集既存在雜訊(有些問題無法回答),又過於簡單(由於模型能力的發展和汙染的增加)。為此,Hugging Face 推出的 MMLU-Pro 為模型提供了 10 個選項(而不是原來的 4 個),要求對更多問題進行推理,並經過專家稽核以減少雜訊。 Qwen2-72B 成為榜單中唯一一個 MMLU-Pro 評分超過 50 分的模型 。
GPQA 是一個難度極高的知識數據集,其中問題由該領域的專家(生物學、物理學、化學等方面的博士級專家)設計,且經過多輪驗證以確保難度和事實性,對於普通人來說很難回答。從模型普遍較低的整體得分來看,新版 GPQA 評測存在較高難度, Qwen2-72B 的 19.24 分目前已是最高分 。
值得一提的是,除了 Qwen2-72B,榜單前列還有我們許多熟悉的中國模型: 零一萬物的 Yi-1.5-34B-Chat 處在第 7 名 ,Qwen1.5-110B 和 Qwen1.5-110B-Chat 也分別位於榜單第 10 名和第 11 名——正如 Hugging Face 聯合創始人兼執行長 Clem 所說:「 中國的開源模型在整體上占主導地位。 」
參考連結:
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
https://huggingface.co/spaces/open-llm-leaderboard/blog
由 CSDN 和 Boolan 聯合主辦的「2024 全球軟體研發技術大會(SDCon)」將於 7 月 4 -5 日在北京威斯汀酒店舉行。
由 MIT 電腦與 AI 實驗室(CSAIL)副主任、ACM Fellow Daniel Jackson 和 世界著名軟體架構大師、雲原生和微服務領域技術先驅 Chris Richardson 領銜,華為、BAT、微軟、字節跳動、京東等技術專家將齊聚一堂,共同探討軟體開發的最前沿趨勢與技術實踐。
大會官網: http://sdcon.com.cn/ (可點選 閱讀原文 直達)












