什麽是數據平台
標準的解釋是這樣的
Wikipedia
A data platform usually refers to a software platform used for collecting and managing data, and acting as a data delivery point for application and reporting software.
數據平台是指將各類數據進行整合、儲存、處理和分析的技術平台,旨在基於數據為業務提供各類服務、產生業務價值。數據平台可以從不同的資料來源中獲取數據,並將數據進行清洗、融合和轉換,最終提供給分析師、決策者和套用開發者等各類使用者使用。
大數據平台,是數據平台在大數據時代的概念衍生,其功能寬度和包含的要素要勝於傳統的數據平台,是能處理海量數據儲存、計算,支持離線批次處理分析、互動式查詢、流數據即時計算等多類負載場景的技術堆疊,通常包括數據采集、數據儲存、數據計算、排程運維、數據治理和數據套用等主要核心功能。
非官方的解釋,我有一個更簡明的定義:
「數據平台是盡可能高效地利用儲存和計算資源(用最少資源),處理和分析海量且多樣數據的技術底座」
數據平台的價值
介紹數據平台價值的文字很多,通常會提到數據平台可以儲存海量資訊,處理、分析並轉化這些數據為分析洞察等等。不過結合筆者在過去十幾年的數據分析和使用平台的經驗,還是講三點有特別價值的點。
大數據平台是創新的孵化器
以智慧汽車和工業互聯網場景為例,據車百智庫2024年的行業分析報告,一輛L4自動駕駛的智慧網聯汽車,每日透過車內外傳感器采集的行駛數據、環境數據和行為數據等,已達到10TB的量級,是傳統汽車的5-10倍。根據最新預計,在路上行駛的智慧汽車每年上傳到雲端的數據超過70000PB。在20年前,也就是2000年前後,互聯網最蓬勃發展時期全球互聯網的數據總量是1000PB。也就是如今僅智慧汽車機器產生的數據就是20年前整個互聯網數據的70倍。如今進入大數據時代,我們越來越清晰的看到, 數據規模的幾何倍增長衍生產生的數據價值,以及需要更創新更智慧分析數據的方式。
舉3個過去10年已經成為現實的數據創新的例子:
城市交通管理:
許多城市利用數據平台來最佳化交通流量,透過分析來自交通訊號、車輛傳感器、公共交通系統的數據,數據平台能夠預測交通擁堵並調整訊號燈周期,甚至引導駕駛者選擇最佳路線。這種智慧交通系統的創新減少了擁堵,提高了城市交通執行效率
電商如亞馬遜的動態定價策略:
亞馬遜的數據平台能夠實分時析市場需求、庫存水平、競爭對手定價等資訊,以此來調整產品價格。這種動態定價策略幫助亞馬遜最大化利潤,同時保持市場競爭力。數據平台在這裏起到了創新策略的試驗場和實施者的角色。
內容和電商平台的動態推薦系統:
數據平台收集了使用者的觀看歷史、評分、搜尋習慣等數據,並利用復雜的演算法為使用者推薦電影和電視劇。這種個人化體驗不僅提高了使用者滿意度,也增加了使用者黏性。抖音、小紅書、電商如阿裏、京東、海外如Netflix的平台都有類似的推薦設定。透過不斷叠代更新,使得推薦系統越來越精準。
還有更多的案例,這裏不再一一列舉。簡言之,筆者認為基於數據和智慧AI的創新是幫助企業從激烈的競爭中走出差異化的道路的有效手段。
數據平台促進非技術團隊的分析能力
透過提供易於使用的工具,數據分析不再是數據分析師和科學家的專屬領域。非技術團隊如市場、營運、財務甚至產品研發等,傳統上依賴BI團隊和數據開發運維團隊支持,可自己上手用更直觀的方式進行數據分析,這得益於數據平台的不斷演進,包括采用如數據視覺化的操作面板,後設資料和數據資產管理平台,免運維的SQL執行環境,更安全的數據管理機制,也包括自然語言支持的數據分析能力逐步成熟。總的說,數據平台凝結了技術普惠的結晶,一整套提供給組織使用,大幅降低了門檻,提升組織的數據能力。
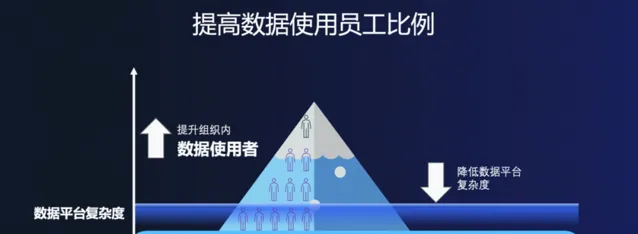
圖1:提升企業內數據使用員工比例
最佳化資源分配與成本控制
在成本控制方面,講究的是數據新鮮度和成本平衡。例如處理高新鮮度的流式數據,透過flink和kafka的組合,由於流數據要保持常駐的計算節點,通常會有比較高的成本,而且如果考慮後續的分析加工鏈路也需要即時,整體方案的成本會比較高。如何無極調節數據新鮮度和成本的平衡,是一個數據平台需要具備的能力。
新的解法有包括更統一的引擎架構,例如下一代數據平台數據引擎可以用增量計算技術實作數據的微批次處理和增量儲存。此外更智慧的引擎也可以透過AI辨識和學習適合合並數據和計算任務,進行增量而非全量處理流程、或透過最佳化數據儲存方案,減少重復冗余的數據儲存降低成本。具有AI加持的數據平台可以透過多種自動化方式減少手動處理需求,從而降低成本並提高效率。

圖2:無極調速的數據平台大幅提升執行效率概念圖
定義數據平台功能的組成,分別解決什麽問題
通常一個數據平台有如下功能模組(熟悉這個領域的朋友可以略過)包括:
1.數據整合同步
將來自不同資料來源的數據整合到一起形成一個統一的數據集的過程,涉及數據收集、清洗、轉換、重構和整合,以便在統一的資料倉儲或數據湖中進行儲存和管理,包括離線同步和即時同步。

圖3:典型數據整合
2.數據的批次處理
數據的批次處理是數據最通常的處理方式,將數據集合按照上下遊關系安排任務順序,分批次進行處理,以處理海量數據,是一種最大化處理數據規模,最大化節省資源的數據處理方式。
3.流數據的處理
是即時處理和分析連續生成的數據流的過程。流數據的處理透過跟蹤和儲存有狀態算子的中間計算結果,支持有狀態的計算和容錯性,具有低延遲和高吞吐量的特點,適用於即時數據處理場景,如網路監控、推薦系統和物聯網數據分析等場景。
4.互動式分析
數據分析師使用例如SQL/Python/R等數據分析語言,或透過視覺化工具對數據進行即時的查詢,聚類,匯總等分析,得出分析結果並支持企業或組織采取決策或行動。互動式分析有低延遲高並行的特點,以更好支持分析師對即時性及臨時性(ad-hoc)和互動性的使用體驗。
5.任務開發排程和運維監控
透過數據開發界面,使用類似SQL等通用的描述性數據分析語言,對數據進行抽取(Extract)、轉換(Transform)和裝入(Load)的步驟,或進行ML/數據科學研究,進行數據分析的模組。
透過對系統內所有資料庫資源進行統一管理和監控,采集監控數據,並根據預警規則進行判定,以及采取相應的預警或自動化處理措施,確保系統的穩定性和效能。
圖4:數據目錄監控數據血緣
6.數據資產管理
狹義上是對數據本身的建立、儲存、加工和控制的一整套流程,旨在幫助使用者快速理解數據的上下遊關系及其含義,精準定位所需數據,減少數據研究時間成本,提高效率。進一步,現代的數據資產管理,旨在提供企業對數據資產進行規劃、控制和供給數據的方式。例如確保數據的安全前提下的跨組織共享;例如有嚴格許可權管控的數據報表,確保核心數據保密;例如同一個報表,不同人看有不同的報表層級——區域只能看到區域的數據,總部能縱覽全域,等數據許可權控制機制。
把元件組裝在一起,就可以了麽?
一個建設大數據平台的最樸素的想法就是把上述的元件組合在一起,構成企業能用的平台。MDS(Modern Data Stack)就是這樣的數據架構理念,它強調元件之間的解耦與模組化,組合實作不同工具和服務的整合。
MDS理念和反思
Tristan Handy,dbt的CEO,最先在2020年下半年的Future Data會議上提出了「Modern Data Stack」(MDS)這一概念,既由眾多模組化功能組合而成的數據技術棧,並在dbt Labs的部落格上發表了相關文章。
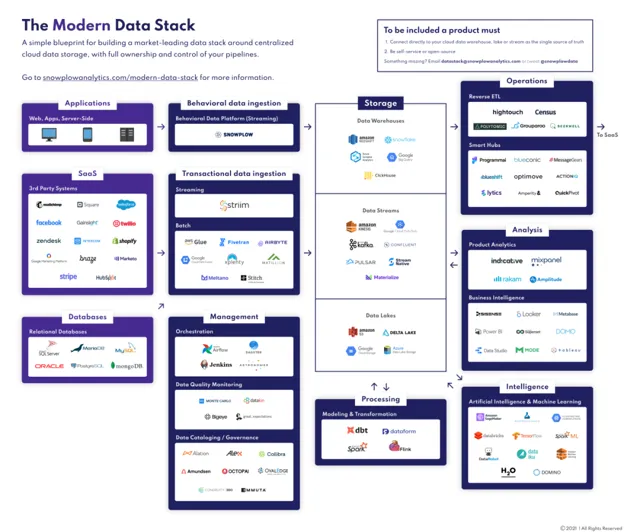
圖5:Modern Data Stack(MDS)
業界對MDS的討論
Modern Data Stack(MDS)概念的提出者 Tristan Handy在2024年2月的文章中也表達了他最新的思考,文章的標題就是「Is the 'Modern Data Stack' still a useful idea?"。當一個概念的提出者都發出這樣的疑問,我們就應該引起重視了。感興趣的朋友可以參看這篇文章:【Is the "Modern Data Stack" Still a Useful Idea?】
Tristan Handy
Finally, as a result of all of this pressure on data spend, buyers developed a strong preference to buy integrated solutions rather than to buy many tools to construct a stack. Buyer willingness to construct a stack from 8-12 vendors has declined significantly . Companies are much more likely today to expect to buy 2-4 products as the core of their analytics infrastructure.
Handy的觀察是「(隨著經濟大環境的改變),來自成本的壓力逐級傳導到數據團隊和架構選擇上,客戶越來越傾向於購買整合一體的產品。而組合8-12個廠商的技術棧方案,已不太受買家青睞,采用的意願度大幅下降...」
此外,Ternary Data的創始人兼CEO,暢銷書【數據工程基礎】的聯合作者Joe Reis,與Matt Housley共同討論了Modern Data Stack的未來,並在他們的線上書中提到了「現代數據棧」MDS這一概念的消亡。文章的標題甚至更直接「Everything Ends - My Journey with modern data stack」 ,直譯文章標題【一切都結束了——我的MDS歷程】:Everything Ends - My Journey With the Modern Data Stack
文中的觀點也是對現代數據技術棧的反思 ,講到由於多種數據工具的大量產生使得人們的關註點不再是基礎和原理,而是簡單的實踐,重視工具的使用技巧而不是工具背後的原理。導致數據技術棧的發展缺乏創新。
Joe Reis也很不留情面的講出,「MDS元件確為客戶提供了‘豐富’的工具,讓企業的數據團隊有了成噸的‘問題’要解決——然而對企業本身無實際附加價值。」
Joe Reis
I feel like the MDS made it easy for the data industry to go backward, allowing data teams to have a ton of convenient tooling while adding questionable value to their organization.
大部份使用開源工具的企業或者組織,買台機器並下載開源數據工具使用,並不會對程式碼和計畫做客製化開發和長期的投入,僅僅是使用基礎能力。這樣的方式既沒有發揮出開源軟體的工具的100%潛力,也沒有真正的降低成本。
筆者的觀察是,一方面數據架構過於復雜,如果並非對極致的場景的特殊元件有強要求,可以考慮更一體化的整套商業化產品。這一點Joe Reis說的情況看來是在國內海外差異不大,畢竟改造開原始碼做企業的在地化適配,是只有少數幾個大廠才投得起的事。要看企業規模來決定是不是采用大量開源組裝的方案。有能力使用開源並基於開源做客製開發以更好的做到數據創新,才是開源元件的正確開啟方式。然而這種級別的投入,也只有少數幾個大廠能夠想想,在如今的創業環境中這樣的投入不一定經濟。
數據架構的演進
參考A16Z-Andreessen Horowitz在2023年更新總結 現代數據架構 全景圖,包括離線、即時以及數據湖,資料倉儲,ML/AI等多個領域統一數據架構。圖中每一個灰色框代表一個專門的領域模組,通常有多個類似的產品提供相似的功能。
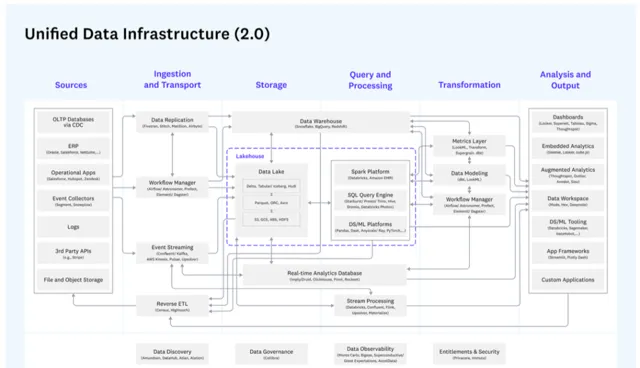
圖6:A16Z 2023 現代數據架構全景圖
在具體的場景中選擇適合的產品,例如我們可以在Spark/Trino/Impala/Doris等產品中做選擇,如果看中多樣性可能選擇Spark對接Hive,如果對高並行和時效性有要求會選擇Trino/Impala等。在不同的場景中選擇各有優勢的產品,還包括用Yarn統一管理資源等等。
這個思路就是我們常說的Lambda架構,Lambda架構是一種用於處理大數據的架構模式,通常至少是將數據處理分為兩個明確的層次:批次處理層(Batch Layer)和流處理層(Speed Layer)。Lambda架構的目的是同時兼顧數據處理的準確性和即時性,透過這兩個層次的結合,能夠有效處理和分析大規模數據集。同理,組合結構化數據所需的資料倉儲和非結構化數據的數據湖,等等組裝的方式來實作一個基礎的數據平台。有過統計,如果需要完成基本的數據平台,會需要至少10余個元件拼裝完成。這是一個比較復雜且有挑戰的過程。
Lambda架構
實踐上,以下是幾個不同場景不同使用者的數據架構例項,可以作為參考理解數據平台的典型架構:
(圖文參照自雲器科技聯合創始人關濤的文章AI風暴來襲: )
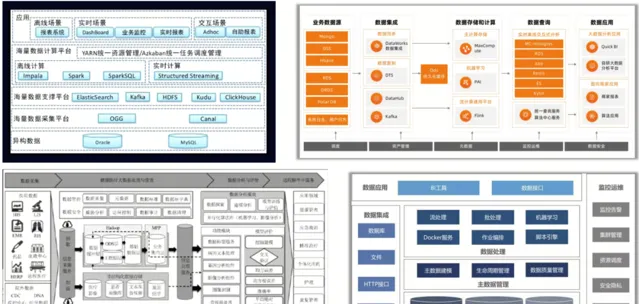
圖7:目前典型的大數據系統架構案例
Lambda架構受詬病的原因,還在於數據處理需要分為兩個路徑:一個是批次處理路徑,用於處理大量歷史數據;另一個是流處理路徑,用於處理即時數據。
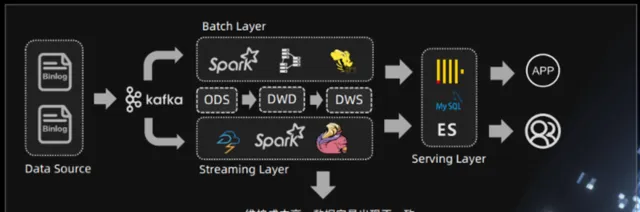
圖8:Lambda架構數據處理流程
這兩個路徑在處理邏輯上往往有所重疊,但是需要分別維護,這就增加了系統的復雜性和開發成本。此外數據湖和倉難統一,也有格式不開放,冗余數據的諸多問題。
Kappa架構是什麽
Kappa架構的設計理念是簡化即時大數據系統的復雜性。
與Lambda架構不同,Kappa架構提出了一個更為簡潔的解決方案。在Kappa架構中,所有數據——無論是即時的還是歷史的——都被同一套處理引擎進行處理,無論是實分時析還是批次處理,都使用相同的處理邏輯,從而簡化了系統設計,減少了冗余,並使得系統維護和擴充套件變得更加容易。
簡單來說,如果把Lambda架構比作一家餐廳裏分開運作的速食視窗(流處理)和正餐區(批次處理),那麽Kappa架構就像是一個將所有顧客都透過同一個視窗服務的速食店。這樣做的好處是,餐廳的工作人員只需要掌握一套服務流程,無論是面對想要快速吃完走人的顧客,還是想要慢慢享用的顧客,服務的效率和品質都能得到保證。
一體化架構有統一的引擎,支持即時、離線和互動分析,避免了數據冗余、多條鏈路等問題。下圖是舉例一個典型的在Kappa架構的數據分析架構,支持多種不同的任務負載,共享資源池,可彈性伸縮並有統一儲存等特點。
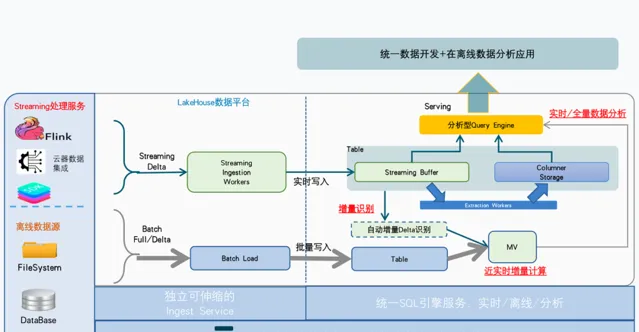
圖9:一體化架構使用示意圖
總結數據平台必備的元件和要素
總結一下現在的數據平台——不再只是單一功能的大資料庫,有處理批和流以及實分時析等多種負載的引擎能力,有整體的支持非結構化數據和結構化數據的管理機制,有更多有機組合的管控能力。數據平台也不再是幾個元件的簡單集合。
數據平台應該具備如下六個關鍵要素:
穩定 :數據平台需穩定執行,直接支撐業務營運。保證數據處理及時準確,遵循「可監控,可灰度,可回滾」原則。關鍵在於可觀測性,確保任務執行、版本控制、監控、告警、運維等功能齊全。
經濟 :儲存和計算的高效對於成本的節約至關重要。儲存格式,壓縮率、檔的讀寫效能,單位算力處理數據的效能,一直是基礎平台層持續最佳化追求的目標。在效能上的比拼,是數據平台在穩定性之外的主要考量要素。
多樣 :數據平台需要能夠支持多樣的數據處理模式,比如離線批次處理、互動式查詢分析、流計算和即時處理等。傳統的方式透過組裝不同的計算引擎來滿足,但業界也開始出現基於Single Engine來滿足不同作業負載的新的趨勢。
安全 :數據平台需要能提供體系化的安全管控能力,諸如統一的數據許可權管理、儲存加密、數據脫敏、風險辨識,以及滿足安全合規要求等
開放 :數據平台可以與其他產品進行對接,尤其是儲存、計算引擎的開放性;數據平台自身也要易於擴充套件增加新的元件。
易用 :數據平台在操作層面的易用性容易被忽視、但對數據平台的成功套用至關重要。數據平台需要綜合考量不同的使用者群體,比如數倉ELT工程師、數據分析師、業務營運人員等,在專業技能和使用習慣上的差異性,使用者使用體驗。從平台建設視角看,僅面向技術同學、單純以技術視角來構建數據平台產品是大忌,會嚴重影響平台的推廣使用。數據平台效率為本、業務價值優先。
開篇曾談到數據平台的定義,「數據平台是指用最少資源,處理和分析海量且多樣數據的技術平台」。我認為這個定義足夠簡潔抽象地概括了數據平台的核心價值——透過整合和統一為企業和組織提升數據分析效率。
此外關於數據平台的發展趨勢,如果您想深入了解演進過程和發展趨勢,我重磅推薦這篇文章 ,對數據平台的演進過程和方向做了很好的梳理。
如何選擇數據平台
1.明確企業或組織對數據平台的需求
並非所有企業的數據需求都是相同的。根據企業的成熟度、業務目標和技術能力,我們可以將企業對數據平台的需求分為五個級別,從基礎的數據收集和儲存到高級的數據智慧和預測性分析,每一級別都代表了企業在數據套用深度和復雜度上的逐級上升。

圖10:數據分析5級智慧分層模型
如圖所示的企業數據智慧化的5級分層模型,代表企業對數據的分析能力和智慧化能力,從L1到L5逐步升級向上,層級越高智慧化能力越強,也需要更完備的數據平台能力支撐。這裏建議重點關註兩個關鍵跨越——分別出現在向L2級和L4級的跨越上。
第一個關鍵跨越 是由第1級台階邁向第2級台階的過程,為什麽這一個跨越很重要,因為這是真正進入大數據分析的分水嶺——考慮到數據量的快速增加,CTO必須要考慮數據平台的成本和效率問題。相對的,第一級台階基於對小量數據,依靠記憶體計算和MPP高並行低延遲的計算已經逐漸成為數據分析的統一標準,很容易給使用者帶來「甜區」效應。問題就在於當數據量快速擴大時,組織往往會發現很難一邊對接更多的多個元件,保證數據分析規模平滑擴充套件,一邊控制成本:總系統復雜度和維護成本陡然上升。
第二個關鍵跨越 是由第3級邁向第4級的過程中,為什麽它重要,有兩個原因,其一是外部環境的劇變,AI時代下應該考慮數據資產如何能夠更好地和AI結合,結合數據和AI的能力。其二是數據生態的內耗阻力讓CTO重新思考尋找開放的數據格式和數據湖倉方案。傳統的方案數據格式在多種負載中不統一,在數據傳統的數據湖不具備狀態儲存,而即時鏈路又需要帶狀態的儲存。挑戰在於此時企業已經有了非常大的數據規模,方案的調整和遷移成本都會相對更高。所以這級跨越也對組織來說非常具有挑戰,需要提前規劃長效的升級方案。
2.選擇「雲上」或「雲下On-Premise」

圖11:雲下 vs 雲上
近期「下雲」話題炒得火熱,特別是在馬斯克推動Twitter全力「下雲」之後,這一討論達到了高潮。所謂「下雲」,指的是企業從依賴雲端運算服務商提供的雲服務,轉而采用自建數據中心或其他本地解決方案來處理和儲存數據。據評估這個決策可以為Twitter節省60%的成本。對頭部巨型企業而言,這個成本節省是非常有吸重力的。有一個數據可以參考,據評估蘋果公司每月在亞馬遜雲端運算上的支出就超過了3000萬美元。
安全考慮,對於對數據安全性和私密有嚴格要求的企業來說,On-Premise部署提供了讓數據管理者放下顧慮的方式。企業可以直接控制物理伺服器和網路環境,實施自訂的安全策略,減少數據泄露和未經授權存取的風險。
自建伺服器部署的另一個考慮是企業想實作「可控」。企業將擁有對資料庫系統的完全控制權,包括硬體選擇、配置設定、數據管理和安全性控制。此外,企業會拒絕接受雲廠商提供的一系列服務,不想被釘選了軟體生態,不想被「繫結」。
優點
安全因素
自主可控,不會被雲廠商繫結
缺點
需要龐大的專業的技術團隊
數據規模和計算規模缺乏彈性
On-Premise部署的 缺點 也是很明顯,首先需要龐大的專業的技術團隊,這就決定了必須要有足夠大規模的計算集群,這樣做才值得。其次,選擇OP部署相當於放棄了雲的彈效能力,擴縮容將變得復雜,需要一系列流程和操作。
筆者認為現在已經有越來越多的PaaS層產品/開源生態方案,支持在多雲環境部署,也是一種解除軟體生態繫結的方式。另外On-Premise要考慮數據備份問題,異地災備也並不簡單。對於大中型企業,數據安全的擔憂永遠是相對於成本和效能做綜合考慮,根據企業自身情況安排適合的方式。舉個例子,您會選擇把錢放在家裏的保險箱,還是存在銀行?數據的上雲或下雲也是類似的選擇。
相應的在雲環境搭建數據平台是有它的優勢,首先是計算資源和儲存資源的彈性伸縮能力,雲資源池提供了近乎無限的可能性,而企業不用關心如何采購伺服器的和軟體執行環境,運維擴縮容等問題。雲端運算契合增長型企業對數據平台的訴求:全面、靈活且易擴充套件。
3.選擇「全托管」的數據平台,或自建
自建企業數據平台 允許企業根據目前的需求客製其數據處理、儲存和分析的元件,例如目前不需要流數據的處理那就可以先不考慮流計算,如果暫時沒有大規模數據要求,例如可以用2台機器先執行起來開源軟體做分析。這種方法為企業提供了靈活性和控制權,使企業能夠調整數據架構以最佳化效能和效率。然而靈活和控制權的代價是顯著的初期投資,包括硬體、軟體授權以及招募和培養專業人員的成本。開源數據平台的執行離不開持續的維護和升級成本,如前文所述,組裝本身有系統復雜和冗余鏈路的諸多問題。
優點
靈活和可延伸性的控制權
如果選擇開源自建則軟體本身是「免費」的
如果能參與開源社群,或在此基礎上做客製開發,可以在特定場景專項最佳化
缺點
初始成本和維護成本難控制
技術復雜度,系統復雜度有挑戰
維護成本高
全托管的一體化數據平台 為企業提供了一個無需擔心硬體和軟體維護的解決方案,使得企業能夠更加專註於其核心業務。這些平台通常易於部署和使用,能夠快速適應企業需求的變化。由於成本大多是基於訂閱的,企業可以更容易地預測和管理其數據管理成本。然而,選擇全托管的SaaS解決方案也意味著企業可能會面臨一定程度的功能限制,以及對供應商的依賴增加。
優點
快速部署和易於使用,一體化綜合效能優異
直接獲得成熟的大數據infra架構
成本可預測,線性可控,免運維減輕內部負擔
多雲環境的數據平台也兼具靈活
缺點
平台有一整套元件,有一定的適應使用和學習門檻
在考慮是否自建企業數據平台或選擇全托管的SaaS模式數據平台時,關鍵在於評估您的企業情況。自建數據平台提供了高度的客製性和對數據控制的優勢,適合那些對數據安全有著嚴格要求,且願意投入初期成本和資源進行長期投資的企業。
企業選擇開源自建如果不能做到深度參與開源,或基於開源框架做一些客製改造,實際上與使用整套方案無異。
采用整套一體化方案適合專註在業務創新的企業,希望減輕管理負擔,快速啟動,並優先考慮成本效益。這種全托管的SaaS模式的數據平台可能是這類企業更合適的選擇。
決策建議
評估業務需求和目標:明確您的數據處理需求、安全標準以及長短期業務目標。
考慮資源和能力:評估您的內部資源和技術能力,確定是否有能力自行建設和維護數據平台。
成本效益分析:進行詳細的成本效益分析,包括初期投資、長期維護成本以及潛在的業務價值。
最後,無論選擇哪種路徑,都應保持靈活性,隨著企業發展和市場變化調整數據戰略。技術的迅速發展意味著今天的最佳選擇可能需要在未來重新評估。持續的技術評估和戰略調整將是企業成功利用數據的關鍵。
透過深入分析和適時的決策,企業可以選擇最適合其特定需求和目標的數據平台解決方案,最大化數據的潛在價值,從而在競爭中保持優勢。
幾個關鍵問題:
是否接受雲環境,或需要OnPrime部署?
是否有高數據新鮮度要求或場景?
是,批/即時場景都有
單一批次處理T+1和分析場景
單一的即時數據分析場景
是否對資源彈效能力,平台效率和成本敏感?
是否有非結構化數據的處理和ML及AI的需求?
是否沒有自研改造並適配開源方案的需求?
如果以上5個問題中,如果有2個以上的回答「是」,那麽可以考慮更「一體化」的平台方案;如果能接受雲環境的數據平台,則可以考慮全托管的數據平台,這樣能最大化的利用平台資源彈性伸縮的能力,降本增效。
目前實踐Kappa架構的廠商或計畫有:
雲器科技首先提出「增量計算」的一體化引擎(Single-Engine),可以統一批、流和實分時析,並且是一個湖倉平台。
關於一體化架構的價值和收益可以參看一些相關的案例,有降低50%成本的案例陸續和陸續的報道,例如這篇案例:
END
關於雲器
雲器Lakehouse 作為面向企業的全托管一體化數據平台,只需註冊帳戶即可管理和分析數據,無需關心復雜的平台維護和管理問題。新一代 增量計算 引擎實作了批次處理、流計算和互動式分析的統一,適用於多種雲端運算環境,幫助企業簡化數據架構,消除數據冗余。
點選文末「 閱讀原文 」,前往雲器官網申請試用,了解更多產品細節!
官網:yunqi.tech
B 站:雲器科技
知乎:雲器科技
▼點選關註雲器科技公眾號,優先試用雲器Lakehouse!
往期推薦











