【導讀】 隨著時間推移,RAG 技術已經迅速成為在實際套用中部署大型語言模型(LLMs)的首選方式。本文旨在介紹混合檢索和重排序技術的基本原理,解釋其對提升 RAG 系統文件召回效果的作用,並討論構建生產級 RAG 套用的復雜性。透過對實驗數據評估和測試結果的分析,本文還突出了混合檢索 + 重排序在不同場景下的顯著優勢。
本文精選自【 007:大模型時代的開發者】,【新程式設計師 007】聚焦開發者成長,其間既有圖靈獎得主 Joseph Sifakis、前 OpenAI 科學家 Joel Lehman 等高瞻遠矚,又有對於開發者們至關重要的成長路徑、工程實踐及趟坑經驗等,歡迎大家 。
作者 | 何文斯 張路宇
責編 | 王啟隆
出品 | 【新程式設計師】編輯部


我相信在當下這個時間點,每一個大模型套用開發者對 RAG( Retrieval Augmented Generation,檢索增強生成 )的技術概念都已經不再陌生。在著手寫這篇文章 之前,我觀察到仍有不少技術文章將 RAG 簡單歸納為基於 Embedding 的向量檢索技術與大模型生成技術的結合。
但實際上,各行各業的開發者們在 RAG 套用方向上經過近一年的探索和實驗後,普遍意識到一個問題: 在打算將套用部署到生產環境時,僅僅依靠向量檢索技術構建 RAG 套用是遠遠不夠的。
9 月份,Microsoft Azure AI 在官方部落格上釋出了一篇題為【Azure 認知搜尋:透過混合檢索和排序能力超越向量搜 索】 [1] 的文章。該文對在 RAG 架構的生成式 AI 套用中引入混合檢索和重排序技術進行了全面的實驗數據評估,量化了該技術組合對改善文件召回率和準確性方面的顯著效果。
在查閱了與這項技術相關的中英文資料後,我發現中文互聯網對這項技術的討論尚少。
本文作為一篇關於混合檢索和重排序技術入門的文章,一方面將介紹這兩項技術的基本原理,解釋其為何能夠改善 RAG 系統的召回效果。另一方面,也將討論構建生產級 RAG 套用的復雜性。 為了便於理解,我先用通俗的語言快速解釋一下 RAG 系統是什麽。
RAG 概念解釋
2024 年,以向量檢索為核心的 RAG 架構成為解決大模型獲取最新外部知識、同時解決生成幻覺問題的主流技術框架,並已在相當多的套用場景中得到實際套用。
開發者可以 利用該技術以較低成本構建 AI 智慧客服、企業智慧知識庫、AI 搜尋引擎等 ,透過自然語言輸入與各類知識組織形式進行對話。以一個有代表性的 RAG 套用為例(見圖 1):
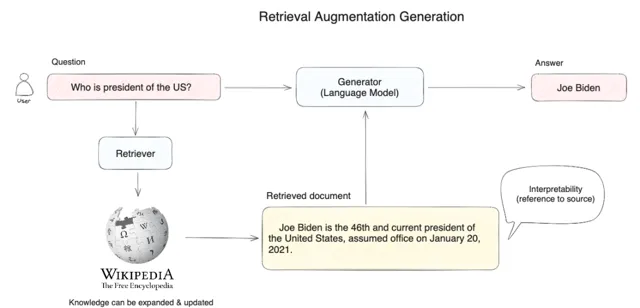
圖 1 RAG 套用示意圖
在圖 1 中,當使用者提問「美國總統是誰? 」時, 系統並非直接將問題送出給大模型來回答,而是首先在知識庫中( 如圖 1 中的維基百科 )進行向量搜尋,透過語意相似度匹配的方式查詢相關內容( 例如,拜登是美國現任第 46 屆總統… ),然後再將使用者問題和搜尋到的相關知識提供給大模型,以使大模型獲得足夠完備的知識來回答問題,從而獲得更可靠的問答結果。
為什麽需要這樣做呢?
我們可以將大模型比作超級專家,他熟悉人類各個領域的知識,但也有自己的局限性。例如,他不了解你個人的一些狀況,因為這些資訊是私人的,不會在互聯網上公開,所以他沒有提前學習的機會。
當你想僱用這個超級專家充當你的家庭財務顧問時,需要允許他在接受你的提問時先檢視一下你的投資理財記錄、家庭消費支出等數據。這樣他才能根據你個人的實際情況提供專業的建議。
這就是 RAG 系統所做的事情:幫助大模型臨時性地獲取他所不具備的外部知識,允許他在回答問題之前先找答案。
根據上面這個例子,我們很容易發現 RAG 系統中最核心的是外部知識的檢索環節。超級專家能否向你提供專業的家庭財務建議,取決於他能否精確找到需要的資訊;如果他找到的不是投資理財記錄,而是家庭減肥計劃,那麽再厲害的專家都會無能為力。
為什麽需要混合檢索?
上文提到,RAG 檢索環節中的主流方法是向量檢索,即語意相關度匹配的方式。技術原理是透過將外部知識庫的文件先拆分為語意完整的段落或句子,並將其轉換( Embedding )為電腦能夠理解的一串數位表達( 多維向量 ),同時對使用者問題進行同樣的轉換操作。
計 算機能夠發現使用者問題與句子之間細微的語意相關性,比如 「貓追逐老鼠」 和 「小貓捕獵老鼠」 的語意相關度會高於 「貓追逐老鼠」 和 「我喜歡吃火腿」 之間的相關度。在尋找到相關度最高的文本內容後,RAG 系統會將其作為使用者問題的上下文一起提供給大模型,幫助大模型回答問題。
除了能夠實作復雜語意的文本尋找,向量檢索還具有其他的優勢:
相近語意理解( 如老鼠/捕鼠器/起司、谷歌/必應/搜尋引擎 )
多語言理解( 跨語言理解,如輸入中文匹配英文 )
多模態理解( 支持文本、影像、音視訊等的相似匹配 )
容錯性( 處理拼寫錯誤、模糊的描述 )
雖然向量檢索在以上情景中具有明顯優勢,但在某些情況中效果不佳。比如:
搜尋一個人或物體的名字( 例如伊隆·馬斯克、iPhone 15 )
搜尋縮寫詞或短語( 例如 RAG、RLH F )
搜尋 ID( 例如 gpt-3.5-turbo、titan-xlarge-v1.01 )
而上述缺點正好是傳統關鍵詞搜尋的優勢所在。傳統關鍵詞搜尋擅長:
精確匹配( 如產品名稱、姓名、產品編號 )
少量字元的匹配( 透過少量字元進行向量檢索時效果非常不好,但很多使用者恰恰習慣於只輸入幾個關鍵詞 )
傾向低頻詞匯的匹配( 低頻詞匯往往承載了語言中的重要意義,比如「你想跟我去喝咖啡嗎?」這句話中的分詞,「喝」「咖啡」會比「你」「嗎」在句子中承載更重要的含義 )
對於大多數文本搜尋的情境,首要的是確保潛在最相關的結果能夠出現在候選結果中。向量檢索和關鍵詞檢索在檢索領域各有其優勢。 混合檢索 正是結合了這兩種搜尋技術的優點,同時彌補了兩者的缺陷。
在混合檢索中,我們需要在資料庫內提前建立向量索引和關鍵詞索引。在使用者輸入問題時,透過兩種檢索模式分別在文件中檢索出最相關的內容( 見圖 2 )。
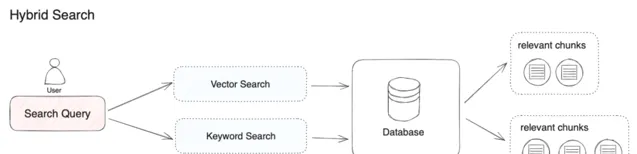
圖 2 混合檢索流程
「混合檢索」實際上並沒有明確的定義,本文以向量檢索和關鍵詞檢索的組合為例。如果我們使用其他搜尋演算法的組合,同樣可以被稱為「混合檢索」。例如,我們可以將用於檢索實體關系的知識圖譜技術與向量檢索技術結合。
不同的檢索系統各自擅長尋找文本( 段落、語句、詞匯 )之間不同的細微聯系,包括精確關系、語意關系、主題關系、結構關系、實體關系、時間關系、事件關系等。可以說沒有任何一種檢索模式能夠適用於全部情境。混合檢索透過多個檢索系統的組合,實作了多個檢索技術之間的互補。
這裏我想強調的是:選擇何種檢索技術,取決於開發者需要解決什麽樣的問題。RAG 系統的本質是基於自然語言的開放域問答系統。對於使用者的開放性問題,要想獲得高的事實召回率,就需要對套用情景進行概括和收斂,尋找合適的檢索模式或組合。
在著手設計一個 RAG 系統之前,最好先考慮清楚自己的使用者是誰,以及使用者最可能提出什麽樣的問題。
為什麽需要重排序?
混合檢索能夠結合不同檢索技術的優勢,以獲得更好的召回結果。然而,在不同檢索模式下的查詢結果需要進行合並和歸一化( 將數據轉換為統一的標準範圍或分布,以便更好地進行比較、分析和處 理),然後再一並提供給大模型。在這個過程中,我們需要引入一個評分系統:重排序模型( Rerank Model )。
重排序模型透過將候選文件列表與使用者問題的語意匹配度進行重新排序,從而改進語意排序的結果( 見圖 3 )。其原理是計算使用者問題與給定的每個候選文件之間的相關性分數,並返回按相關性從高到低排序的文件列表。常見的 Rerank 模型如:Cohere rerank、bge-reranker 等。
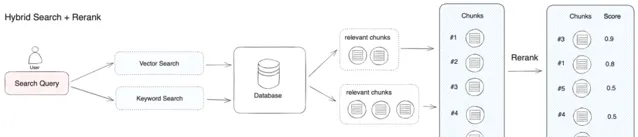
圖 3 混合檢索 + 重排序
在大多數情況下,由於計算查詢與數百萬個文件之間的相關性得分將會非常低效,通常會在進行重排序之前進行一次前置檢索。因此,重排序一般放在搜尋流程的最後階段,非常適合用於合並和排序來自不同檢索系統的結果。
然而,重排序並不是只適用於不同檢索系統的結果合並。 即使在單一檢索模式下,引入重排序步驟也能有效幫助改進文件的召回效果,例如在關鍵詞檢索之後加入語意重排序。
在具體實踐過程中,除了將多路查詢結果進行歸一化之外,我們會在將相關的文本分段交給大模型之前限制傳遞給大模型的分段個數( 即 TopK,可以在重排序模型參數中設定 )。這樣做的原因是大模型的輸入視窗存在大小限制( 一般為 4K、16K、32K、128K 的 Token 數量 ),我們需要根據選用的模型輸入視窗的大小限制,選擇合適的分段策略和 TopK 值。
需要註意的是,即使模型上下文視窗足夠大,過多的召回分段可能會引入相關度較低的內容,從而導致回答的品質降低。因此,重排序的 TopK 參數並不是越大越好。
重排序並不是搜尋技術的替代品,而是一種用於增強現有檢索系統的輔助工具。 它最大的優勢在於,不僅提供了一種簡單且低復雜度的方法來改善搜尋結果,允許使用者將語意相關性納入現有的搜尋系統中,還無需進行重大的基礎設施修改。
以 Cohere Rerank 為例,我們只需要註冊帳戶和申請 API,接入只需要兩行程式碼。此外,Cohere Rerank 還提供了多語言模型,這意味著我們可以將不同語言的文本查詢結果進行一次性排序。
Azure AI 實驗數據評估
Azure AI 對 RAG 中幾種常用的檢索模式做了實驗數據測試,包括關鍵詞檢索、向量檢索、混合檢索、混合檢索 + 重排序。實驗結果支持將混合檢索 + 重排序視為改進文件召回相關性的有效方法,對於使用 RAG 架構的生成式 AI 場景尤其適用。
以下是針對不同數據集型別的測試結果,可以看到混合檢索 + 重排序的組合在不同測試集下的召回品質上都有一定程度的提升( 見圖 4 )。
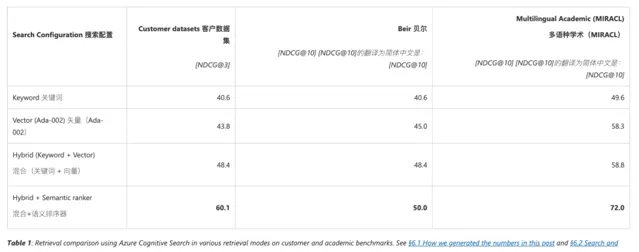
圖 4 針對不同數據集型別的測試結果
以下是針對不同查詢情景的評估結果,可以看到在各個用例情景下,混合檢索 + 重排序在不同程度上提升了文件召回的品質( 見圖 5 )。

圖 5 針對不同查詢場景的評估結果
總結
本文討論了在 RAG 系統中引入混合檢索和語意重排序對於改善文件召回品質的原理和可行性,但這僅僅是 RAG 檢索管道設計中的一部份環節。
改善 RAG 套用的效果不能依賴於一個個獨立的單點最佳化,而是要具備系統性的工程設計思維。要深刻理解使用者的使用場景,將復雜的開放域問答問題概括為可收斂的一個個情景策略,只有在此基礎之上,才能合理地選擇索引、分段、檢索、重排等一系列技術組合。
相關資料:
[1] https://techcommunity.microsoft.com/t5/ai-azure-ai-services-blog/azure-cognitive-search-outperforming-vector-search-with-hybrid/ba-p/3929167
[2] https://txt.cohere.com/rerank/
[3] https://vectara.com/what-is-reranking-and-why-does-it-matter/
[4] http s://vectara.com/how-to-implement-hybrid-search-into-your-product-for-better-customer-experiences/
[5] https://qdrant.tech/articles/hybrid-search/
[6] https:/ /weaviate.io/blog/hybrid-search-fusion-algorithms
[7] https://www.pinecone.io/learn/series/rag/rerankers/
[8] https://medium.com/@ben.burtenshaw/similarity-learning-vs-search-reranking-practical-approaches-to-boosting-real-world-search-367a152ff870
[9] https://weaviate.io/developers/weaviate/concepts/reranking
[10] https:// zhuanlan.zhihu.com/p/84206752
[11] https://eugeneyan.com/writing/llm-patterns/
[12] https://towardsdatascience.com/vector-search-is-not-all-you-need-ecd0f16ad65e
在 RAG 檢索技術革新的同時,程式設計師的編程範式也正在被 AI 顛覆!由 CSDN 和 Boolan 打造的【基於大語言模型的套用開發】課程將為你引領至機率的世界,歡迎點選下方直播預約,第一時間了解大語言模型的核心技術,把握這場顛覆性的技術革命機遇。











