整理 | 夢依丹
出品丨AI 科技大本營(ID:rgznai100)
在經歷 CEO 被迫下台、核心研發團隊成員離職等風波後,在文生圖領域享受盛名的 AI 獨角獸公司 S tability AI 如約開源 Stable Diffusion 3 Medium,並號稱這是迄今為止最先進且最新的文本影像開源生成模型。
Hugging Face 地址:
https://huggingface.co/stabilityai/stable-diffusion-3-medium
官網放出了一段效果視訊,先賞為盡:
新推出的 Stable Diffusion Medium 旨在成為一款體積更小、功能強大的模型,能夠在消費級 GPU 上流暢執行。目前該模型已授權非商業用途下載體驗。 API 體驗地址:
https://platform.stability.ai/

效能提升顯著, SD 3 Medium 亮點一覽
據官博介紹, SD3 Medium 是一款具備 20 億參數的 MMDiT 影像 模型, 其在 影像品質、字型處理、復雜指令理解及資源效率等方面實作了顯著的效能飛躍,其背後功臣則是 Diffusion Transformer 架構。 其中與輝達合作的 TensorRT 最佳化版效能直接提升了 50%。
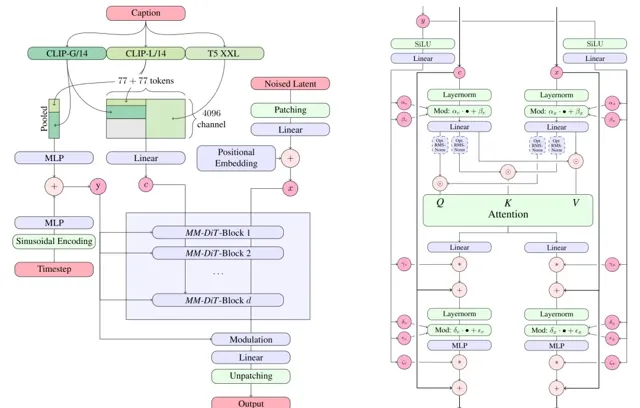
為此,官網還列出了 SD 3 Medium 的諸多亮點:
整體品質和照片級真實感:生成的影像細節豐富、色彩飽滿、光影自然,既能實作逼真的照片級輸出,也能適應多種風格的高品質創作。透過諸如 16 通道變分自編碼器(VAE)等創新技術,該模型成功規避了其他模型常見的缺陷,比如在渲染手部和面部時的不真實感,從而提升了這些部位的表現力和真實度;
提示詞理解能力:能深入理解包含空間推理、構成元素、動作及風格等復雜要素的長指令。使用者可透過全部三個文本編碼器的組合 使用,在效能與效率之間做出靈活取舍;
文字呈現:借助 Stability AI 的擴散變換器架構,實作了前所未有的文字品質,大幅減少了拼寫錯誤、字距調整、字母形態和間距問題;
資源高效:較低的 VRAM 占用,即便是在標準消費級 GPU 上執行,也能保持高效能,無效能衰減之憂;
精細調校:即使面對小型數據集,也能精準吸收其中的細微特色,非常適合個人化客製。
同時,Stability 與輝達和 AMD 開展合作。利用輝達 RTX GPU 以及 TensorRT 增強全體 Stable Diffusion 模型(包括 SD3 Medium)的效能,TensorRT 最佳化版本更可提供 50% 的一流效能提升;AMD 已針對各類 AMD 裝置(包括最新 APU、消費級 GPU 以及 MI-300X 企業級 GPU)最佳化了 SD3 Medium 的推理效能。
效果不錯?人體繪制大翻車!
期待之下,不少使用者及時測評了新模型的圖片生成效果。
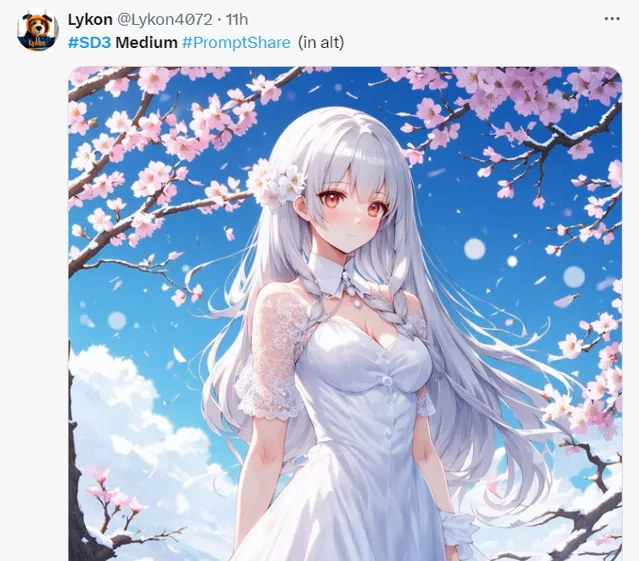
櫻花少女,甜美可愛。
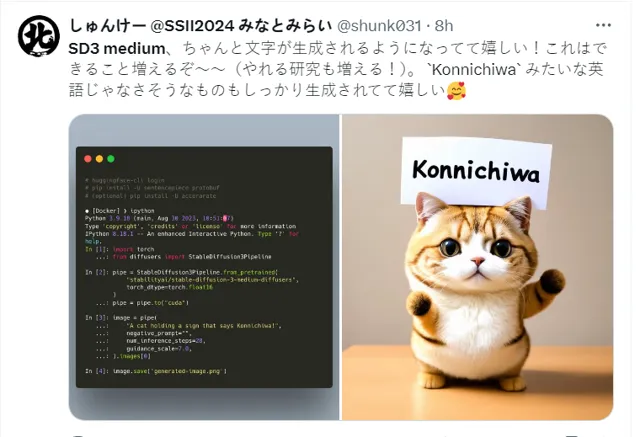
3D貓貓,萌感得讓人想rua。
同時,日語使用者還在感嘆 SD 3 Medium 對非英語的提示詞的輸入辨識理解及對應生成能力。
等等,事情並沒有這麽簡單。
到了現實場景的人像生成時,各種詭異的現象發生了……
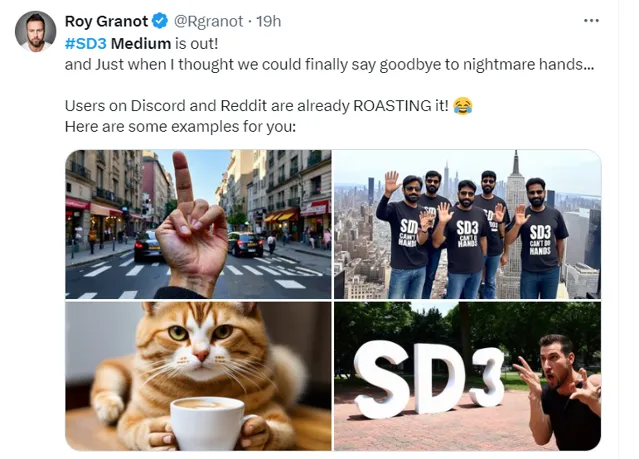
SD3 Medium 在人體影像生成能力上翻車了!
不少網友也曬出了更多翻車圖片
:

使用 Stable Diffusion 3 生成的躺在草地上的女孩的 AI 影像

使用 Stable Diffusion 3 Medium 生成的 AI 影像
根據實測表現,使用者對該款模型的釋出並未給到多少贊譽,反而是嘲笑的成分更多些: 這款號稱最先進的影像合成模型,卻在人像生成及人體部位繪制上比 Midjourney 或 DALL-E 3 的效果更差,著實令人大跌眼鏡。
簡直就是對上述官網列出的亮點第一條的大型打臉現場!各種匪夷所思的「鬼胎」生成,讓網友直呼:太陰間!
在 Reddit 上,一篇名為「這個版本是個笑話嗎?」的貼文詳細描述了 SD3 Medium 在渲染人類特別是四肢(如手和腳)方面的失敗。使用者直接吐槽 道: 「S tableDiffusion 與 Midjourney 的競爭時間並不長,現在它看起來簡直像個笑話。唯一能拿出來說說的,就只有數據集安全和符合道德原則了!」
問題就出在道德準則
Stability 強調安全、負責任的 AI 實踐原則,並已經采取並將繼續透過合理措施以防範惡意行為者對 SD3 Medium 的濫用行為。該公司表示,安全自模型訓練之時起,貫穿整個測試、評估與部署過程。Stability 對模型開展了廣泛的內、外部測試,同時制定並實施了多項保護措施以防止危害發生。
然而,這樣嚴苛的道德準則,也會影響訓練圖片中的過濾機制。
「分享一條冷知識,對模型的嚴格審查也會過濾掉人體解剖素材,於是……就變成現在這樣了。」一位 Reddit 使用者如是說。
AI 影像愛好者們目前將 SD3 的人體繪制問題,歸咎於 Stability 堅持從 SD3 的訓練數據中過濾掉成人內容,即所謂「不適合工作時間觀看」的內容,簡稱 NSFW,影像生成品質因此有所下降。
每當使用者的提示詞表達了 AI 模型未能在訓練數據集中充分接觸過的概念,影像合成模型就會開始自行編造,扭曲詭異的影像也由此產生。
此前,類似情況也有發生。
2022 年釋出的 Stable Diffusion 2.0 在描繪人體方面也出現過類似的問題。當時,AI 研究人員很快發現,篩除包含裸露內容的成人素材很可能會嚴重妨礙 AI 模型準確生成人體解剖結構的能力。隨後釋出的 SD 2.1 和 SD XL 成功扭轉了局面,恢復了一部份因嚴格過濾 NSFW 內容而失去的繪圖能力。
模型預訓練期間可能出現的另一個問題,是研究人員設計的 NSFW 過濾器在刪除數據集中成人影像時可能過於挑剔,意外排除了那些並不存在冒犯性的內容,這就導致模型偶爾無法準確描繪人體。一位 Reddit 使用者在貼文中寫道,「只要圖片不涉及人物,SD3 的工作就一切正常。所以我認為是他們用於過濾訓練數據的 NSFW 過濾器敏感度過高,把所有人類影像都劃入了 NSFW 範疇。」
而這次,問題再次發生。
太講武德的開發及訓練規則,讓大模型難以窺其全貌,於是幻覺產生,「鬼胎」誕生。 道德準則也許不應前置在大模型學習階段,而應在輸出階段嚴加把控。
應該堅持怎樣的道德準則,如何設定道德規則以至於讓大模型更好地服務人類,此次 SD3 Medium 釋出及人體繪制的再次翻車更說明了其重要性。
參考連結:
https://thenextweb.com/news/stability-ai-launches-stable-diffusion-3-image-generator
https://stability.ai/news/stable-diffusion-3-medium
https://mp.weixin.qq.com/s/3ynUfre02C1Lz5jEfI62Rw












