
導讀 近年來,湖倉一體化在業界備受矚目,不論是單點最佳化還是整體遷移 ,都取得了顯著成果。本文將介紹騰訊遊戲數據分析的湖倉一體化實踐。(本文整理自 2023 年 7 月 21 日 DataFunCon2023(北京站)(線下)周威老師關於【騰訊遊戲數據分析的湖倉一體化實踐】的演講,文章內容均切合於當時時間點)
主要包含以下內容:
1. 計畫背景
2. 存算分離
3. 數據分層
4. 湖倉一體化
5. 效能最佳化
6. 效果展示和後續規劃
7. 問答環節
分享嘉賓| 周威 騰訊遊戲 騰訊遊戲分析引擎Tech Lead
編輯整理|劉明城
內容校對|李瑤
出品社群| DataFun
01
計畫背景
1. 計畫背景
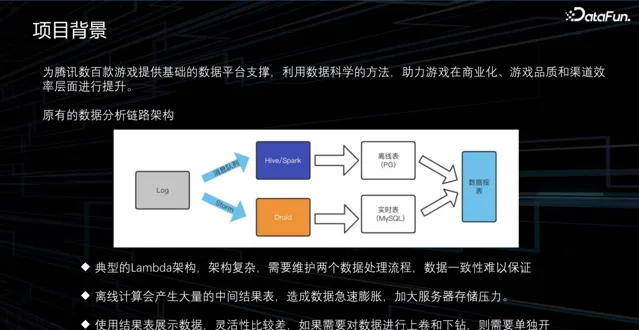
騰訊遊戲公共數據平台部在開始制定新數據平台方案前,是基於已經執行了大約十年的原始架構,是一個典型的 Lambda 架構,其中涉及眾多元件,流程復雜。典型的 Lambda 架構下主要存在三方面問題:
數據平台架構復雜,需要維護兩個數據處理流程,數據一致性難以保證。
離線計算會產生大量的中間結果表,造成數據急速膨脹,加大伺服器儲存壓力。
使用結果表展示數據,靈活性比較差,如果需要對數據進行上卷和下鉆,則需要單獨開發程式,計算新的結果表。
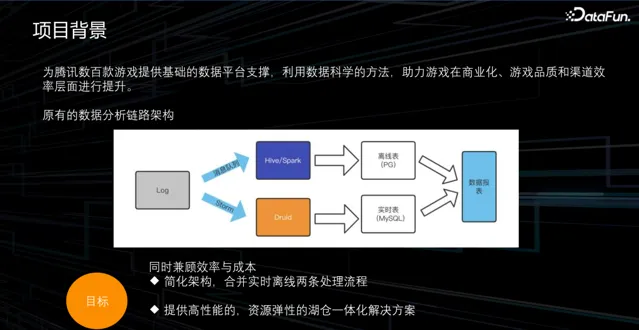
為了解決上述問題,我們考慮在同時兼顧效率與成本的情況下采用新的開發模式或架構,實作以下幾個目標:
簡化架構,合並即時離線兩條處理流程,減少元件數量。
我們需要一個更靈活的方案,能夠在效能方面提升,並且在資源管理、計算和儲存方面具備更彈性的特點,從而降低成本。
使用同一套架構,透過不同的元件和配置支持不同場景的數據分析服務。
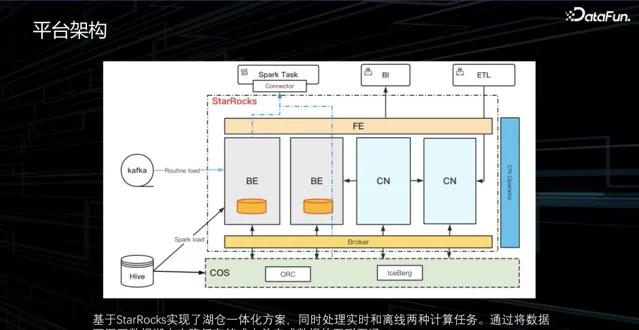
2. 平台架構
為了實作上述目標,我們對業界的數據產品和元件進行了一系列調研。最終,選擇了基於 StarRocks 的方案來構建我們的湖倉一體化產品。在新的架構中,StarRocks 分析引擎是核心元件。結合了 Iceberg 數據湖和騰訊雲的物件儲存COS 來實作。即時數據透過 Kafka 和 Routine load 方式匯入,離線數據則透過 Spark load 方式從 Hive 表中匯入。除此之外,還透過這樣一個統一的方案,實作了數據科學的 Spark 任務、線上 BI 報表以及 ETL 任務的支持。
02
存算分離
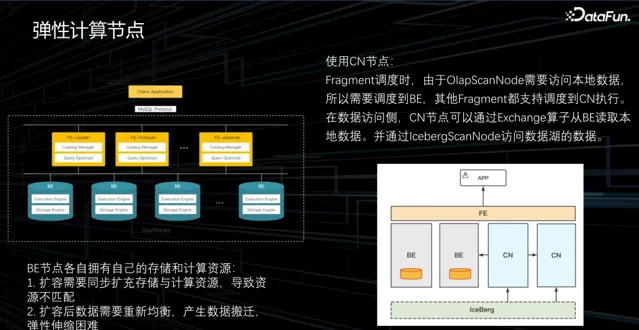
1. 彈性計算節點
在轉向新方案時,原 StarRocks 的架構分為兩層,上層是 FE 節點,下層是 BE 節點。FE 節點的主要作用是生成查詢計劃和管理原始數據,而具體的執行由下方的 BE 節點完成。然而,BE 節點不僅執行計算任務,還負責儲存。
BE 節點存算一體結構,會導致儲存和計算資源不匹配的問題。在很多情況下,集群中儲存的數據量並不大,但計算任務卻非常繁重,提升計算能力只能透過擴充機器,但這會導致 BE 節點儲存的浪費。另一個問題是,由於 BE 需要負責儲存,擴充套件機器後的均衡和搬遷操作較慢,且在均衡時會消耗效能,影響查詢效能。為了解決這些問題,我們與社群合作提出了一個方案:將 BE 的計算能力分離,建立 CN 節點(Computer Node)。將 BE 的儲存引擎替換為新元件,並放置在 CN 節點上。在排程過程中,透過 exchange 算子將數據從 BE 拉到 CN 上本地進行計算,實作了加速或擴充套件集群計算資源的目的。
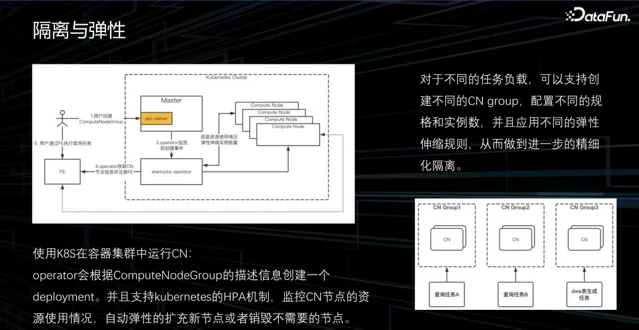
2. 隔離與彈性
將 BE 的計算能力分離,建立 CN 節點(Computer Node)時,可以看到 CN 已經演變成一個無狀態的節點。為了解決 CN 的擴容和彈性需求,我們充分利用了 K8s 的特性,並開發了一個 K8s 的 operator。透過將 CN 執行在容器中,能夠利用 K8s 的 HPA 機制軔態監控 CN 的負載,並自動執行擴容和縮容操作。此外,我們在 CN 上引入了一個內容,實作了 CN 的分組能力。
透過將不同的業務負載分配到不同的 CN 組中執行,實作了不同業務之間的隔離。同時,可以根據不同的 CN 組制定不同的彈性任務策略,例如在白天高負載時擴容,在晚上低負載時縮容。透過這種方式,能夠靈活地進行計算資源的彈性伸縮,不論是大規模還是小規模的計算都可以在同一個集群中滿足。
03
數據分層
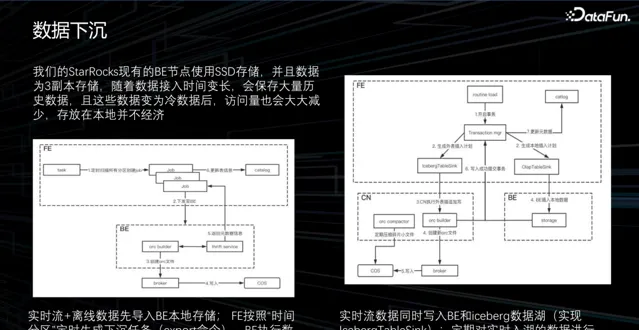
1. 數據下沈
除了計算部份,我們還需要解決儲存方面的彈性需求。目前我們的 StarRocks 集群使用 SSD 儲存,為了高可用性,我們的所有數據都儲存了三份副本。然而,由於遊戲周期較長,遠古時期的數據很少被存取,如五年前或三年前的數據。將這些數據直接儲存在本地成本很高。為了解決這一問題,我們考慮與數據湖結合,將數據儲存到數據湖中。為此我們提出了兩種下沈到數據湖的方案:
即時流+離線數據先匯入 BE 本地儲存;FE 按照「時間分區」定時生成下沈任務(export 命令),BE 執行數據下沈到數據湖的操作。
即時流數據同時寫入 BE 和 Iceberg 數據湖(實作 IcebergTableSink);定期對即時入湖的數據進行 compact,排序並合並來提升存取效能。
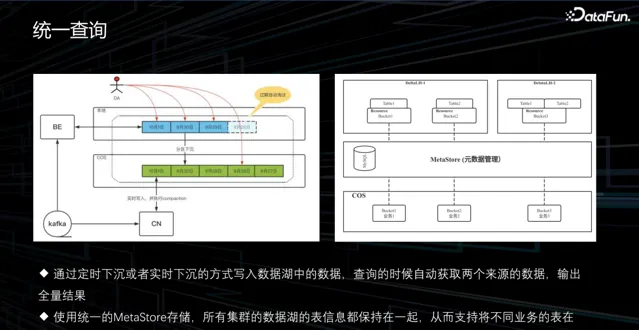
2. 統一查詢
在查詢數據時也面臨一些問題。在我們的遊戲場景中,業務通常是隔離的,因此我們為每個業務建立了一個集群。在數據分析時會遇到數據需要共同處理的情況,由於這些數據存在於不同的 StarRocks 集群中,無法進行關聯查詢。為了解決這個問題,我們透過數據湖的方式將這些數據聯動起來,實作下沈後進行分析。由於我們使用 Iceberg,並使用相同的 MetaStore 進行後設資料管理,因此所有集群都能直接檢視這些下沈後的數據,實作關聯分析。
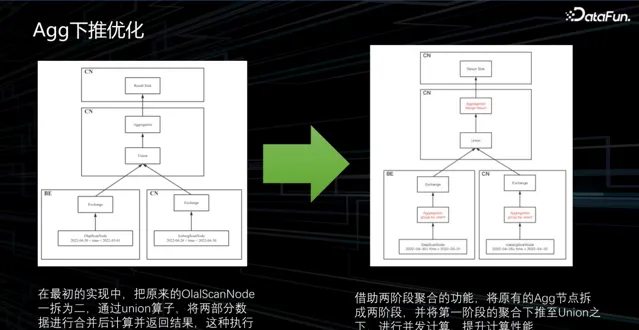
3. Agg 下推最佳化
在對湖倉數據進行合並測試時,發現其效能存在問題。我們進行了分析,並檢視了執行計劃。原先的執行計劃比較簡單,它首先讀取 BE 表的數據,再讀取 CN 表的數據,接著對這些數據進行聯合運算,最終得出結果。然而,如果只需要進行簡單的 count 操作,按照原先的執行計劃執行的話,實際上會讀取符合條件的所有數據並將其傳輸到另一個 CN 節點上,在那個節點上進行 count 計算,然後再返回結果。
顯然,這個過程中傳輸了大量不必要的數據,實際上我們只需要傳輸 count 的結果就可以。為了解決這個問題,我們可以避免將原始數據傳輸 shuffle,而是在原地進行 count 計算,然後再進行 sum 操作。
基於這樣的思想,借助於 StarRocks 具備的一個多階段聚合的特性。我們可以將第一階段的聚合下推到 union 操作的下面,如此一來數據傳輸量就會大大減少。透過這種計算拆分的方式,數據的讀取效能提升了約六倍。
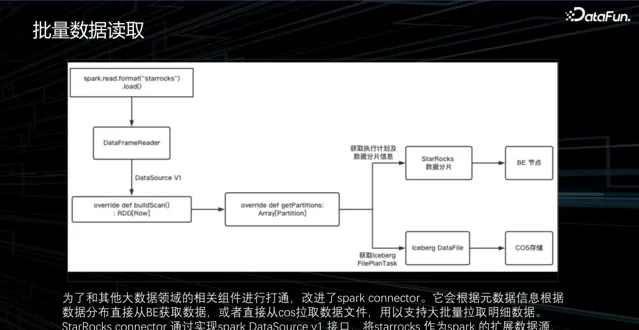
4. 批次數據讀取
在我們的場景下,還涉及到一些數據科學的任務,即執行 Spark 任務並計算出一個模型。在數據科學的任務中,通常需要讀取最近一個月甚至一年的所有明細數據。然而,使用 JDBC 的方式顯然效率很低,可能會導致集群崩潰或者非常慢。為解決這個問題,StarRocks 社群提供了一種解決方案,即使用 Spark 來讀取數據。
然而,社群方案只能讀取存在 BE 的數據。為了實作查詢的統一,我們對StarRocks 原生的 Spark connector 和 Iceberg Spark connector 進行了融合,並在上面實作了數據的路由。透過原始數據的資訊,可以確定數據實際上儲存在BE 上,然後直接從 BE 讀取數據。如果發現數據儲存在湖中,就從物件儲存中讀取數據,然後直接返回。
04
湖倉一體化
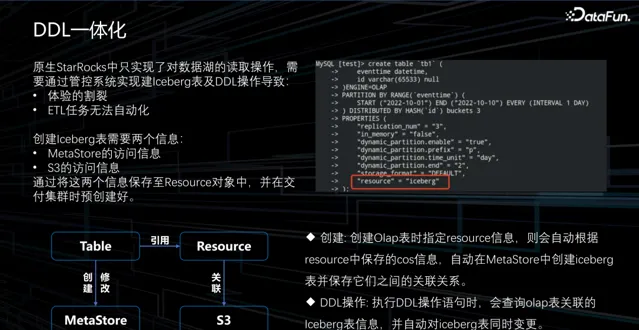
1. DDL 一體化
在完成存算分離和數據分層這兩步,我們已經實作了任務計算和儲存的彈性。然而,要更全面地利用它們,僅有這兩項彈性還不夠,我們需要考慮更簡潔、更易用的方面。例如,StarRocks 對數據湖的原生支持只涉及讀取,但在我們的場景中,有時會透過執行 etl 任務生成數據並將其寫入數據湖。
對於大型數據,人們希望能夠直接將臨時數據寫入數據湖而不是下沈的方式,然後在 StarRocks 上使用。然而,StarRocks 原生不支持建立 Iceberg 表,這就導致了體驗不連貫,同時 ETL 任務可能無法自動化。因此,我們需要實作建表功能。理論上建立 Iceberg 表只需要獲取兩種資訊:MetaStore 的存取資訊,用於獲取原始數據資訊和物件儲存路徑,以及物件儲存的許可權資訊。一旦有了這兩種資訊,就可以在 StarRocks 中建立表,我們將這些資訊都儲存在 Resource 物件中。透過這種方式,使用者在編寫指令碼時只需指定 Resource 物件,就可以建立表。此外,在執行其他 DDL 語句時,我們也將這些資訊同步到 Iceberg 中。
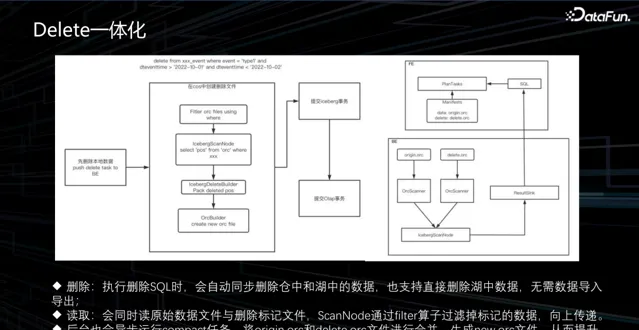
2. Delete 一體化
在實際操作中,我們經常會遇到數據的補錄或修正的場景。例如,使用者可能發現半年前的數據存在錯誤,需要進行修正。在這種情況下,我們的處理邏輯很簡單,即刪除數據並重新上傳。然而,StarRocks 之前並不支持 Iceberg 數據刪除操作。Iceberg 的數據刪除有兩種方法:
第一種方法是 Copy on Write。這種方法需要先讀取所有數據,然後刪除不需要的數據,生成新的數據並儲存。雖然這種方案實作簡單,讀寫效能較好,但寫入速度較慢,因為需要一次全量讀取和寫入。
另一種方案是 Merge on Read,即在讀取數據後標記不需要的數據,並將刪除檔寫入,需要對讀取部份做改造以過濾不需要的數據。考慮到補錄業務通常是緊急需求,我們選擇了 Merge on Read 方案。
然而,Merge on Read 方案對查詢效能並不友好,因為每次查詢都需要過濾一遍刪除檔。我們借助了 compact 任務,定期合並數據來提升查詢效能。
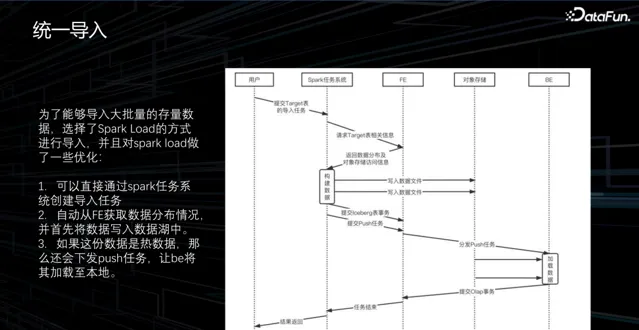
3. 統一匯入
在大規模數據匯入的場景中,數據基於 Hive 架構的儲存,需要遷移至另一儲存地點,且數據量龐大。過去使用的 steam load 方案存在問題,需要在 BE 節點進行序列化、反序列化、數據分發、任務送出和壓縮。而且單次 steam load 數據量有限,需要多次送出,給 BE 節點帶來巨大壓力。
針對此問題,社群提出了 Spark load 方案。該方案在數據讀取後,使用 Spark 進行數據重組,根據 BE 節點所需的 StarRocks 數據格式進行分區、統計和排序,儲存到外部儲存中,然後請求 BE 節點將外部儲存數據一次性匯入。此流程能減少多余步驟,BE 節點只需執行一次壓縮就可匯入數據。結合湖倉一體場景,可考慮將外部儲存更換成數據湖,直接將數據寫入物件組中。具體來說,Spark 任務完成數據構建後,將數據寫入湖倉。若數據為熱數據,即一年內使用的數據,可向 BE 請求將數據載入回本地;若數據為冷數據,則可直接使用。透過此方式簡化數據匯入,減少對負載的影響。
05
效能最佳化
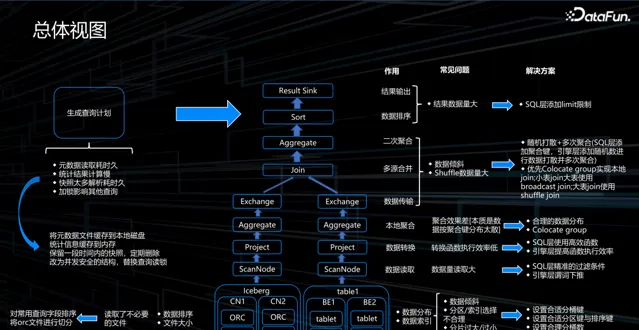
1. 總體檢視
我們在實踐中發現,讀取數據湖近 90% 甚至更多的時間都花費在 IO 操作上,也就是將數據從湖中讀取出來的過程。因此,最佳化數據湖的方案主要聚焦於減少數據讀取量。從湖中直接讀取數據檔時,根據使用者的 where 條件,使用條件進行排序和重組數據,還會調整檔的大小。另外,壓縮演算法也有一定作用。不同的數據可使用不同的壓縮演算法,其壓縮比也會有所不同。當然,這些參數需要結合數據格式進行驗證才能得到合理的結果。
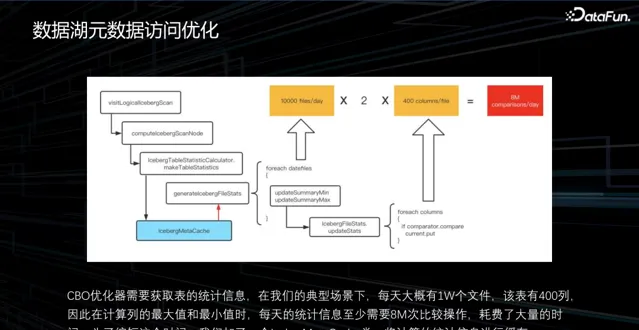
2. 數據湖後設資料存取最佳化
此外,執行計劃的生成也是一個重要的方面,執行計劃的生成包括語法解析、語意解析、最佳化器、邏輯計劃和物理計劃。在 CBO 最佳化器層面,為了獲取數據的統計資訊,通常至少需要一個最大值和一個最小值進行篩選。在一個典型的場景中,假設一天會產生一萬個數據檔,而表有 400 列,這個是一個比較平均的表大小。經簡單計算,每天都要做 800 萬次的最小值比較,這個代價是相當高的,其實沒有必要每次都這樣做。所以我們進行了最佳化,將所有的統計數據先計算出來,放到記憶體中,下次取數據時直接從緩存中獲取結果。透過這種方式,可以減少統計資訊計算的耗時。
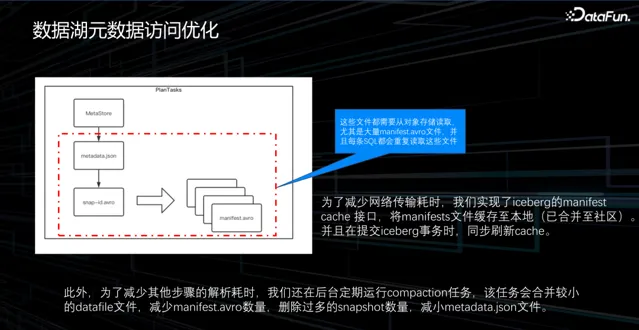
最佳化物理執行和物理計劃時,需要從 Iceberg 獲取所有的 data file 檔列表,在獲取 metadata.json 之後透過 MetaStore 獲取所有 snapshot,再獲取 manifest 檔。除了第一個步驟需要透過資料庫讀取外,其余檔都需要從物件儲存讀取。由於數據量大,因此讀取過程非常耗時。最初的想法是將所有內容存入記憶體,每次讀取時直接從記憶體中取出,但測試結果發現記憶體無法儲存如此龐大的數據,有可能高達上百 GB。因此,我們將數據持久化到本地儲存,以防止因 FE 重新開機而遺失數據。此外,我們還采取了一些查詢最佳化手段,主要集中在減少檔數量和大小方面。
06
效果展示和後續規劃
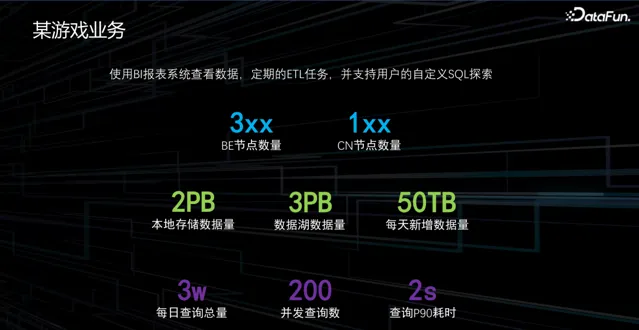
1. 某遊戲業務效果展示
因為我們的遊戲都是相對獨立的,所以每個遊戲都有自己的數據集群。例如,某頭部遊戲業務,數據部份涉及大約 300 多個 BE 節點,以及 100 多個 CN 節點。因此,該遊戲的本地數據量大約為 2PB,同時數據湖中的數據量約為 3PB。該業務每天會新增大約 50TB 的數據,單次查詢的總量約為 3 萬條,同時支持 200 個並行查詢,查詢 P90 的耗時為 2 秒。
2. 後續規劃
下面是後續規劃。盡管我們已經對數據湖進行了一些最佳化,但仍然有一些業務抱怨速度太慢,尤其是對於某些活動數據的頻繁查詢,比如遊戲中的活動,可能會關註去年或前年的活動數據。因此,我們希望透過物化檢視的能力,將這部份數據臨時緩存到本地。
另外,我們對原始數據進行了最佳化,但解析過程仍然耗時,因為所有解析都在 FE 上進行,而 FE 是一個單點,且只有一台機器,會有效能上限。我們計劃將原始數據解析後的結果儲存到 OLAP 表中。這樣可以透過 BE 或 CN 的引擎能力提升篩選速度,減少序列化反序列化的時間。另外,我們還計劃使用 CN 集群做預構建匯入,並減少 compact 消耗,以提升大批次數據匯入速度。

07
問答環節
Q1:我註意到您之前提到在 StarRocks 上實作了存算分離,並引入了 CN 節點。對於社群來說,您認為這種設計有什麽貢獻意義?社群如何看待這個方案?
A1:這個方案已經融入到社群,並可以在 2.4 以上版本使用,因此它已成為社群的標準特性。
Q2:關於數據湖,在您的場景中,數據儲存在物件儲存上,您能詳細介紹一 下「物件儲存」在資料庫方面的優劣勢嗎?您是否與其他儲存進行過比較?
A2:物件儲存的好處在於它是一個通用且雲原生的方案。對於我們的業務來說,在騰訊內部是相對特殊的,因為我們有很多海外場景,而騰訊的其他部門可能沒有這種需求。因此,我們更關註我們的架構是否能夠在海外或公有雲環境中部署。由於很多情況下我們的遊戲是代理遊戲,海外的合作夥伴傾向於使用亞馬遜或谷歌的雲服務。因此,我們需要考慮一些通用性,選擇物件儲存作為我們的雲布局方案。當然,使用物件儲存可能會有一些劣勢,比如在效能方面,由於數據量較大,可能會存在頻寬瓶頸。為了解決這個問題,我們與騰訊雲合作,他們提供了一些加速方案來提升存取效能。
Q3:如果使用 StarRocks 的湖倉一體化架構,是否更加高效?為什麽選擇現在的架構而不是直接使用 StarRocks 整體化架構?
A3:這個問題的關鍵是時間因素。我們的架構方案早在 StarRocks 3.0 的湖倉一體化方案提出之前就已經開始了。所以社群的方案也借鑒了我們的一些早期經驗,比如 CN 節點就是我們和社群共同開發的。另外一個考慮是在我們公司中,我們更傾向於使用儲存格式更加開放的方案。因此,我們選擇了一個相對較開放的Iceberg 的數據格式來進行實作我們的架構。
Q4:MetaStore 未來會整合在 StarRocks 上,還是會成為獨立元件?
A4:首先,MetaStore 肯定是一個獨立的元件,不會整合到 StarRocks 中。因為這個元件比較獨立,整個數據湖環境是一個獨立的架構,我們會有一個團隊來維護數據湖,並與 OLAP 團隊合作。因此,我們不會將這個元件完全整合到 StarRocks 中。但我們實作了這種同步機制,當在 StarRocks 中做了更改時,會自動同步到 MetaStore,包括建表和 DDL 操作都會被同步。
以上就是本次分享的內容,謝謝大家。

分享嘉賓
INTRODUCTION
周威
騰訊遊戲
騰訊遊戲分析引擎 Tech Lead
擔任騰訊遊戲分析引擎團隊 Tech Lead,負責遊戲數據分析引擎技術研發和規劃工作;近期主要從事數據分析引擎的研發以及數倉一體化架構在騰訊遊戲數據分析場景下的落地;在開源社群有諸多貢獻,StarRocks 開源社群 Committer;同時在儲存計算底層技術領域,如 MySQL,Ceph,K8s,Linux Kernel 等領域均有豐富的研發和營運經驗 。
活動推薦
往期推薦
點個 在看 你最好看











