整理 | 王軼群
責編 | 唐小引
出品丨AI 科技大本營(ID:rgznai100)
近日,來自德國圖賓根大學Hertie腦健康人工智慧研究所、圖賓根人工智慧中心的研究團、美國西北大學的研究者 釋出了一篇名為【透過多余詞匯 探究學術寫作中 ChatGPT 的使用】( Delving into ChatGPT usage in academic writing through excess vocabulary )的論文。
論文透過細致的語言分析提出了一個驚人的結論:
ChatGPT 等大語言模型輔助寫作對科學文獻產生了的影響,甚至超過了 COVID-19 疫情對學術寫作的影響。
論文「AI味」有點濃:2024至少10%的論文使用了LLM
自OpenAI在2022年11月釋出ChatGPT以來,學術文獻的寫作風格「AI味」變得有點濃,尤其是2024年。
「我們僅分析了出版年份從2010年到2024年的論文,得到了14182520篇摘要供分析。」該論文將分析了 PubMed 圖書館中超過 1400 萬篇2010至2024年生物醫學摘要的語料庫,跟蹤了過去十年科學寫作的變化。
研究者驚訝地發現,至少10%的2024年釋出的研究論文在撰寫過程中使用了大型語言模型(如ChatGPT)進行輔助。在某些特定領域和國家,這一比例更是高得驚人。
研究人員首先確定了2024年相比以往年份顯著更頻繁出現的詞匯。這些詞匯包括 ChatGPT 寫作風格中典型的許多動詞和形容詞,比如 「深入挖掘」、「復雜」、「展示」 和 「突出」 等。
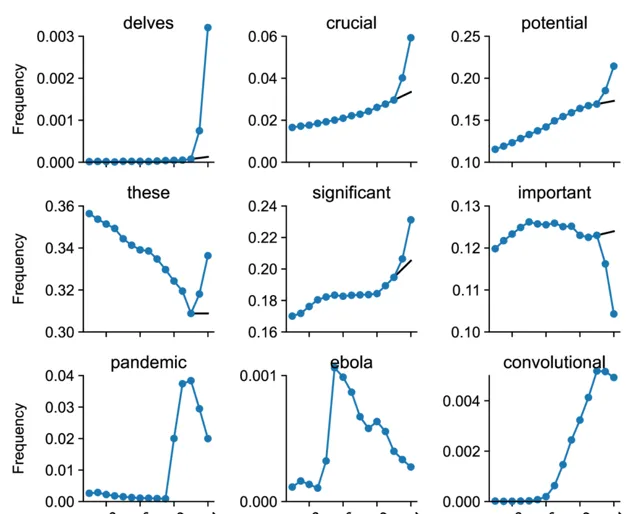
上圖包含某些單詞的 PubMed 摘要的頻率。黑線顯示從 2021-22 年到 2023-24 年的反事實推斷。前六個單詞受到 ChatGPT 的影響;後三個單詞與影響科學寫作的重大事件有關,並顯示出來以供比較。(圖片摘自原論文)
透過分析詞匯使用頻率的變化,研究人員註意到,自ChatGPT釋出以來,許多特定的風格詞匯,如「delves(鉆研)」「showcasing(展示)」「underscores(強調)」等詞匯的使用頻率顯著增加,這反映出科學家們在撰寫論文時,越來越多地借助ChatGPT來潤色和修改文本。
論文采集了3個真實的 2023 年摘要的範例,來說明了這種 ChatGPT 風格的摘要語言表達方式:

根據這些具備AI生成色彩的標誌詞,研究人員估計在2024年,AI 文本生成器影響了至少10% 的所有 PubMed 摘要。
有趣的是,論文中研究者以新冠病毒等詞匯對學術論文的影響對AI生成的影響做了對比。
發現在某些情況下,ChatGPT等AI生成工具給學術文獻寫作帶來的影響,甚至超過了 「Covid」、「流行病」 或 「埃博拉」 等詞匯在其所處時期的影響。
研究者對2013 年至 2023 年的所有年份進行了相同的分析,發現諸如「冠狀病毒」、「封鎖」和「大流行」等詞匯的使用量非常大,這與新冠疫情對生物醫學出版產生前所未有的影響的觀察結果一致。
研究者將2013至2024年的所有774個獨特多余詞註釋為內容詞(如mask或convolutional)和風格詞(如intricate或notably)。新冠疫情期間的多余詞匯幾乎完全由內容詞組成(例如breathing、remdesivir等),而 2024 年的多余詞匯幾乎完全由風格詞組成。在 2024 年的所有 280 個多余風格詞中,66% 是動詞,18% 是形容詞。相比之下,前幾年的大多數多余詞都是名詞。如下圖所示,ChatGPT的多余詞使用量,遠高於新冠等流行病毒的數量。

新冠疫情期間的多余詞匯幾乎完全由內容詞組成(例如breathing、remdesivir等),而 2024 年的多余詞匯幾乎完全由風格詞組成。在 2024 年的所有 280 個多余風格詞中,66% 是動詞,18% 是形容詞。相比之下,前幾年的大多數多余詞都是名詞。(圖片摘自原論文)
IT 期刊裏中國作者對LLM的使用比例高達35%
「我們估計,不同學術領域、所屬國家和期刊的 LLM 使用率下限從 5% 以下到 30% 以上不等。這種差異可能與 LLM 采用率的實際差異相對應。例如,計算領域的 LLM 使用率下限較高(20%)可能是因為電腦科學研究人員更熟悉並願意采用 LLM 技術。在非英語國家,LLM 可能確實可以幫助非母語人士編輯英語文本,這可以證明其廣泛使用是合理的。最後,在審查流程加快和/或簡化的期刊上發表文章的作者可能會爭取 LLM 來撰寫省力文章。」研究者在論文中寫道。
在電腦科學和生物資訊學等領域,大語言模型的使用率最高,其次為環境、醫學、生物資訊學、材料學。
(圖片摘自原論文)
在非英語母語國家如中國、南韓等,大語言模型在學術論文寫作中的使用率相對較高。 研究人員發現,在中國和南韓等國家的 PubMed 子組中,大約有15% 的摘要是使用 ChatGPT 生成的。
而在英語母語國家如英國和紐西蘭的使用率則較低,在英國僅為3%。 然而,這並不一定意味著英國作者使用 ChatGPT 較少。
事實上,根據研究人員的說法,實際上使用 AI 文本生成器的可能要高得多。
研究者認為:許多研究人員會編輯 AI 生成的文本,以刪除典型的標誌詞。母語使用者在這方面可能具有優勢,因為他們更有可能註意到這類短語。這使得確定受 AI 影響的摘要的真實比例變得困難。
在可測量的範圍內,AI 的使用在期刊中特別高,比如在 Frontiers 和 MDPI 期刊中約為17%,在 IT 期刊中更是達到了20%。在 IT 期刊中,中國作者的比例最高,達到了35%。
在學術界高聲望期刊如【自然】【科學】【細胞】等,LLMs使用率較低,而一些開放獲取期刊如 Sensors 、 Cureus 的使用率則較高。
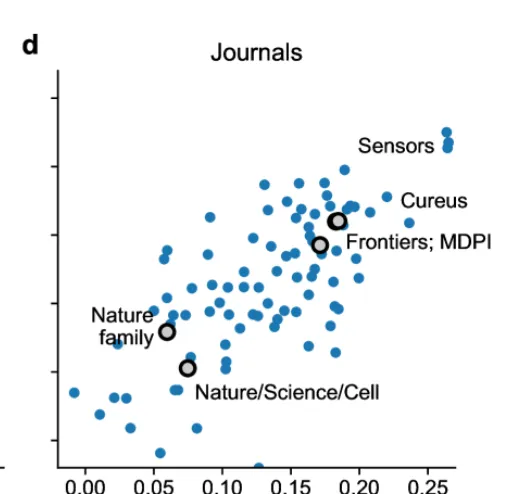
(圖片摘自原論文)
LLM 真的可靠嗎?研究者:需重估AI輔助論文寫作的規則
科學家使用LLM輔助寫作,是因為LLM可以提加文本的語法、修辭和整體可讀性,幫助轉譯成英文,並快速生成摘要。
然而,LLM 可能會捏造事實、強化偏見,甚至進行抄襲。
論文指出:「LLM因編造參考文獻而臭名昭著, 提供不準確的總結,並做出看似權威、令人信服的虛假陳述。雖然研究人員可能會註意到並糾正LLM輔助的自己工作摘要中的事實錯誤,但發現LLM生成的文獻綜述或討論部份中的錯誤可能更難。」
此外,LLM 還可以模仿訓練數據中的偏差和其他缺陷,甚至是徹頭徹尾的抄襲,這種同質化會降低科學寫作的品質。該研究表明,盡管LLM存在以上種種限制,但 LLM 在學術寫作中的使用率仍在上升。
學術界應該如何應對這一發展? 一些人建議使用檢索增強型 LLM,從可信來源提供可驗證的事實或讓使用者向 LLM 提供所有相關事實,以保護科學文獻免於積累細微的不準確性。 其他人認為,對於某些任務,如同行評審,LLM並不適合,根本不應該使用。 因此,出版商和資助機構出台了各種政策,禁止LLM參加同行評審, 作為合著者,或任何型別的未公開資源。
該論文 註明:「我們沒有使用 ChatGPT 或任何其他 LLM 來撰寫手稿或進行數據分析。」
借助這一研究,研究者在論文中呼籲重新評估當前有關 LLM 用於學術的政策和法規: 「LLM 的使用對科學寫作的影響確實是前所未有的,甚至超過了新冠疫情引起的詞匯量的劇烈變化。 LLM 的使用可能偽裝得很好,難以察覺,因此其采用的真實程度可能已經高於我們測量的範圍。 這一趨勢要求重新評估當前有關 LLM 用於學術的政策和法規。 」
研究者在論文結尾處寫道:「我們希望未來的工作能夠更細致地深入追蹤 LLM 的使用情況,並評估哪些政策變化對於應對 LLM 在科學出版領域興起所帶來的復雜挑戰至關重要。 」
由 CSDN 和 Boolan 聯合主辦的「2024 全球軟體研發技術大會(SDCon)」將於 7 月 4 - 5 日在北京威斯汀酒店舉行。
由世界著名軟體架構大師、雲原生和微服務領域技術先驅 Chris Richardson 和 MIT 電腦與 AI 實驗室(CSAIL)副主任,ACM Fellow Daniel Jackson 領銜,BAT、微軟、字節跳動、小米等技術專家將齊聚一堂,共同探討軟體開發的最前沿趨勢與技術實踐。
大會官網: http://sdcon.com.cn/ (可點選 閱讀原文 直達)












