
導讀 指標體系在數據分析、數據套用中有著重要的價值。本文從數倉開發的角度,分享在懂車帝業務中,指標體系建設工作如何開展落地,如何在數倉模型層面實作指標體系建設 。
今天的介紹會圍繞下面六點展開:
1. 如何建立指標體系規範
2. 指標模型建設在數倉工作中的收斂
3. 指標體系品質監控策略
4. 構建全方位的指標套用場景
5. 未來展望
6. 問答環節
分享嘉賓| 肖繼哲 字節跳動 懂車帝資深數倉研發工程師
編輯整理|許通
內容校對|李瑤
出品社群| DataFun
01
如何建立指標體系規範
首先讓我們來了解一下懂車帝業務的一些情況。
1. 懂車帝業務介紹

懂車帝是一站式汽車資訊與服務平台,涵蓋內容、工具和社群,致力於為使用者提供真實、專業的汽車內容和高效的選車服務,同時為汽車廠商和汽車經銷商提供高效解決方案。懂車帝的業務自成立以來,規模和體量在不斷擴充套件,不論是線上使用者還是內部業務場景,均需要數倉提供高品質的數據服務。
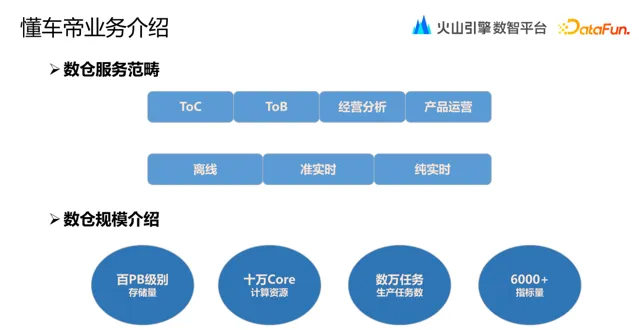
比如面向 C 端使用者視角的熱點文章推播、汽車銷量榜單對比分析等,面向B 端商家視角的使用者購車意願等,以及內部業務的產品營運、經營分析、戰略規劃等場景,數倉一直為其提供數據分析、資料探勘等數據服務。並且,數據服務包括多種時效場景:離線 T+1 場景、準即時(小時級、分鐘級)以及純即時場景。截止目前,懂車帝業務數倉的數據儲存規模在百 PB 級別,日常例行生產任務數據量達數萬,其計算資源消耗超十萬 Core,共累計建設有 6000 多個有效指標。從數倉建設的規模也一定程度上反應出懂車帝業務的復雜性。
2. 為什麽要做指標體系規範
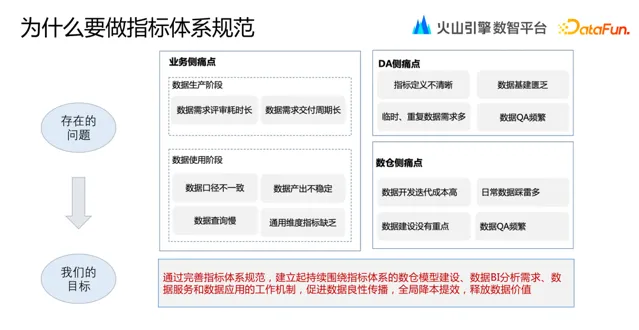
伴隨著懂車帝業務的復雜多樣和快速叠代,業務數據指標體系的建設相對應的也會變得非常復雜。這導致各相關團隊在日常工作中使用數據,都會遇到諸多痛點。為了解決相關工作中的實際問題,數倉團隊結合實際業務訴求,建立起持續圍繞指標體系的數倉模型建設、數據 BI 分析需求、數據服務和數據套用的工作機制,以促進數據良性傳播,全域降本提效,釋放數據價值。
3. DataLeap 指標管理平台
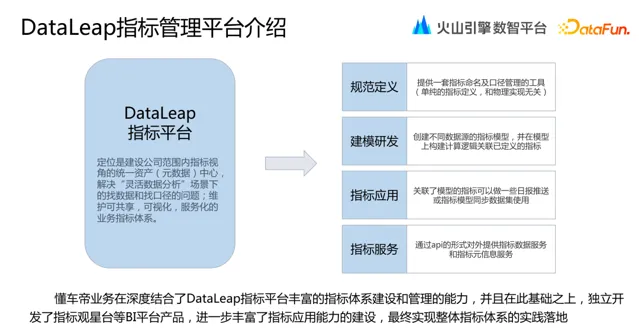
在介紹指標體系建設之前,我們先了解一下火山引擎 DataLeap 平台。DataLeap 的定位是建設公司範圍內指標視角的統一資產(後設資料)中心,解決「靈活數據分析」場景下的找數據和找口徑的問題;維護可共享、視覺化、服務化的業務指標體系。
DataLeap 包含四大部份功能:規範定義、建模研發、指標套用和指標服務。
懂車帝業務深度結合了 DataLeap 指標平台豐富的指標體系建設和管理的能力,並且在此基礎之上,獨立開發了指標觀星台等業務 BI 平台產品,進一步豐富了指標套用能力的建設,最終實作整體指標體系的實踐落地。
4. 指標體系建設框架
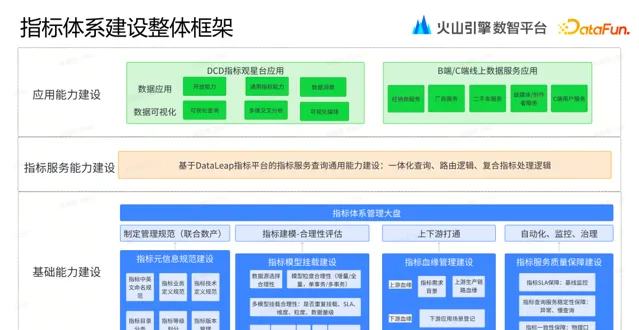
我們整套指標體系建設包括三部份內容:基礎能力建設、指標服務能力建設、套用能力建設。
基礎能力建設主要包括:
指標元資訊規範建設,比如指標的命名規範、業務定義、元資訊管理,解決指標是什麽的問題;
指標模型掛載建設,包 括模型粒度的選擇、多模型如何掛載等,關乎如何保證數據查詢的準確性和效率,解決指標怎麽開發的問題;
指標血緣管理建設,明確上遊生產鏈路以及下遊套用場景,解決指標用在哪的問題;
指標服務品質保障建設,保證指標一致性和整個系統的穩定性,解決指標數據準不準的問題。
有了這些指標的基礎資訊,我們構建了指標體系管理大盤,視覺化地體現基礎元資訊、血緣鏈路資訊等。
在基礎能力具備之後,我們借助 DataLeap 指標平台的能力進行一體化的指標服務查詢能力建設,包括指標路由查詢邏輯的處理和容災處理等。
再進一步,打造指標的套用能力,為業務提供多樣化的指標服務查詢能力。比如我們推出了 DCD 指標觀星台,提供了視覺化的查詢、分析和編排能力。還有很多 B 端、C 端線上數據服務套用,都是建立在統一的指標服務能力基礎上,來確保業務使用數據的一致性和準確性。
5. 指標後設資料管理規範
在指標體系建設中,首先要關註指標後設資料管理規範,包括指標命名規範、指標業務定義、指標等級管理、指標目錄管理、指標版本管理和指標業務命名管理等。
指標命名規範,標準化指標中英文命名,透過指標的詞根拆解來定義沒有歧義、標準一致的數據指標體系,同時透過對詞根進行規範管理,避免同名不同義、同義不同名等問題。
指標業務定義,要結合業務場景,保證指標完善、準確、易懂、精要。
指標等級管理,制定指標優先級,重點關註高級別指標。具體分級為:
一級指標: 衡量業務結果的北極星指標, OKR 指標;
二級指標: 業務重點關註的指標,能夠反映當前業務效果的指標;
三級指標: 衡量過程效率,輔助推動結果達成的指標;
四級指標: 臨時性指標,適用於小範圍的指標。
指標命名規範是後設資料管理規範中的重點,命名不規範會帶來歧義,增加使用的成本。接下來具體介紹如何進行指標命名。

標準的指標中英文命名透過詞根拆解來實作,拆解過程總體包括基礎詞根資訊配置和指標拆解定義。透過規範約束詞根,來實作指標組合拼接達到統一標準。
詞根包括五種:數據域、業務過程、度量、修飾詞、時間周期。透過這五種詞根可以組合拼接出原子指標、衍生指標、復合指標的規範名稱。
為了高效實作詞根拆解,我們開發提供了線上化工具,將詞根拆解過程自動化執行。
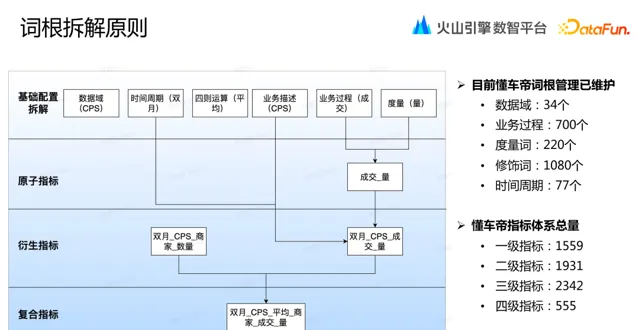
以成交量為例,詞根拆解過程為:
分析業務過程,對應詞根為「成交」;
分析度量,對應詞根為「量」;
分析業務描述,對應詞根為: 「 CPS 」 ;
分析時間周期,對應詞根為: 「雙月」;
依次,可以得到原子指標「成交_量」與衍生指標「雙月_CPS_成交_量」。
進一步,如果和其他指標結合,如「雙月_CPS_商家_數量」,進行四則運算得到復合指標,復合指標名稱為「雙月_CPS_平均_商家_成交_量」。
目前懂車帝詞根管理已維護的包括:34 個數據域、700 個業務過程、220 個度量詞、1080 個修飾詞和 77 個時間周期。
詞根拆解之後,指標後設資料建立流程也會遵循指定的 SOP 約束。
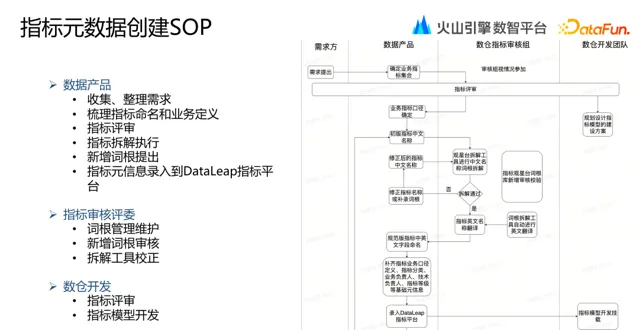
指標後設資料建立過程中,參與角色除了需求方、數據產品團隊、數倉開發團隊,還有數倉指標評審組。數倉指標評審組是一個虛擬小組,有專項數倉同事參與指標評審。
指標後設資料建立 SOP 包括:
需求方提出需求
數據產品團隊確定業務指標集合
數倉指標稽核組進行指標評審
確定業務指標口徑
給出初版指標中文名稱
在觀星台拆解工具中進行中文名詞根拆解
詞根工具根據詞根中文名自動進行英文名稱轉譯
明確指標中英文名稱後,數據產品團隊補齊其他基礎後設資料
錄入 DataLeap 指標平台
在詞根拆解過程中,會透過拆解工具確定詞根是否已經錄入或存在同義詞根。如果詞根庫中詞根已滿足需求,就可直接使用。詞根庫中需要詞根補錄時,數倉指標評審組先進行評審,透過後再加入詞根庫。透過數倉指標評審組的校驗,可以有效保證詞根庫的規範和品質。
指標後設資料建立後,就會由數據開發同學進行模型的開發以及指標繫結。
02
指標模型建設在數倉工作中的收斂
在介紹指標模型建設之前,先來看一下數倉同學在過往工作中存在的問題。

整體上,指標模型建設的情況可以總結為「散、亂、差」。具體表現在:
維度表建設不足:缺少一致性維度層,維度表和事實表沒有嚴格區分,有些維表也放在了 DWD 層。
匯總層嚴重缺失:未沈澱通用的指標邏輯,復用性差,存在同名不同義和同義不同名的問題,血緣鏈路也不清晰,加大了維護和問題排查成本。
明細層建設混亂:直接使用明細數據進行簡單加工,沒有進行過程抽象,造成大量耦合資訊,數據產出的品質和時效越來越沒有保障。
套用層重復建設:隨著需求的增加,套用層快速膨脹,通用邏輯未下沈,造成大量重復建設,導致了資源的浪費。
為了解決指標模型建設的問題,需要結合業務特性制定規範標準。
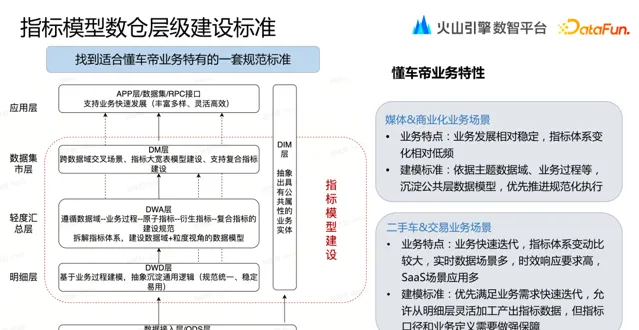
懂車帝的業務場景包括:媒體&商業化業務場景、二手車&交易業務場景。
媒體&商業化業務場景中業務發展相對穩定,指標體系變化相對低頻。這種業務穩定的情況,依據主題數據域、業務過程等,沈澱公共層數據模型,優先推進規範化執行。
二手車&交易業務場景中業務快速叠代,指標體系變動比較大,即時數據場景多,時效響應要求高,並且線上 SaaS 場景套用居多。對應這種快速變化的情況,優先滿足業務需求快速叠代,允許從明細層靈活加工產出指標數據,但指標口徑和業務定義需要做強保障。
為了兼顧兩大類場景,對數倉各層提出了如下一些規範要求:
明細層( DWD 層)基於業務過程抽象,沈澱通用邏輯, 達到 規範統一、穩定易用。
輕度匯總層( DWA 層)遵循數據域 -- 業務過程 -- 原子指標 -- 衍生指標 -- 復合指標的建設規範,拆解指標體系,建設數據域 + 粒度視角的數據模型。
數據集市層( DM 層)處理跨數據域交叉場景,進行指標大寬表模型建設、支持復合指標建設。
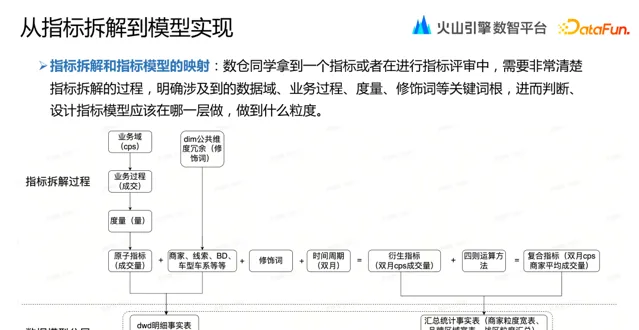
數倉同學拿到一個指標或者在進行指標評審中,需要非常清楚指標拆解的過程,明確涉及到的數據域、業務過程、度量、修飾詞等關鍵詞根,進而判斷、設計指標模型應該在哪一層做,做到什麽粒度。
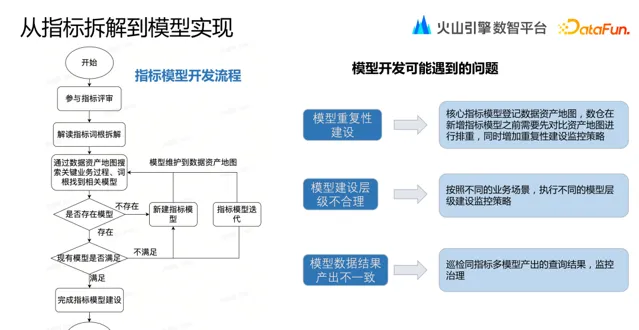
在實際的模型開發中可能會遇到的問題包括:
模型重復建設
模型建設層級不合理
模型數據結果產出不一致。
如何解決這些問題?這就用到了我們整理建設的數倉資產地圖,這裏包含了數倉已經建設的各個主題的數據模型,明確描述了覆蓋的業務過程、數據粒度以及核心滿足的業務場景。在指標模型開發前,數倉同學會透過數據資產地圖搜尋關鍵業務過程、詞根尋找模型。存在已有模型滿足需求,可以直接使用避免重復建設。已有模型不滿足需求時,如新增維度拆解,可以原有模型上進行叠代,並將叠代資訊維護在資產地圖中。透過這樣過程,可以避免模型的重復建設。
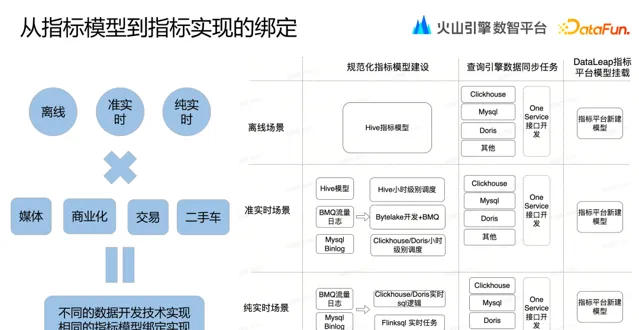
指標模型建設完成後,將指標模型與指標繫結。在懂車帝業務場景中,有離線場景、準即時場景、純即時場景,這些場景中具體的指標實作過程不一樣,但是都會透過 DataLeap 指標平台進行掛載。
一個指標可能會繫結多個指標模型。因為在具體工作中,同一個指標在不同場景會有不同效果的查詢需求,比如 A 場景需要查詢快速響應得到具體數據,B 場景需要進行多維度數據分析,這樣同一個指標的不同的模型產出,可以滿足不同維度分析與產出時效、查詢效率的平衡。

03
指標體系品質監控策略
指標查詢中會遇到各種問題,如:查詢失敗、慢查詢、指標產出時間延遲、不同業務找同一個指標查詢結果不一致、指標生產資源浪費等問題,因此需要建立指標體系品質監控來及時發現和解決問題。
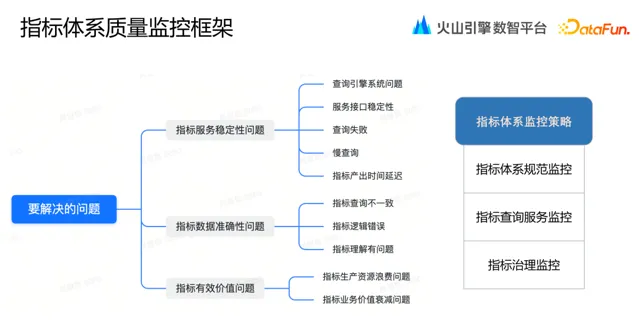
指標體系監控策略整體上包括三大部份:指標體系規範監控、指標查詢服務監控和指標治理監控。
1. 指標體系規範監控

指標體系規範監控包括:詞根管理監控、指標業務定義監控、指標等級監控和指標版本監控四大方面。具體內容如上圖所示。
2. 指標查詢服務監控
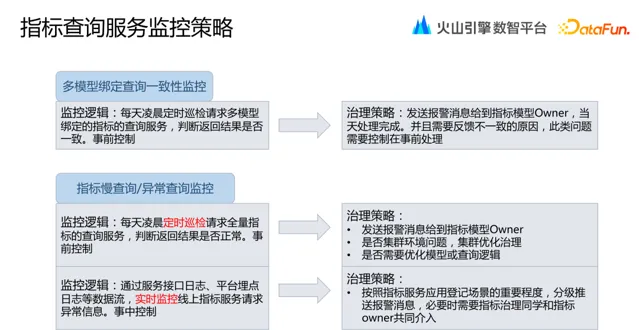
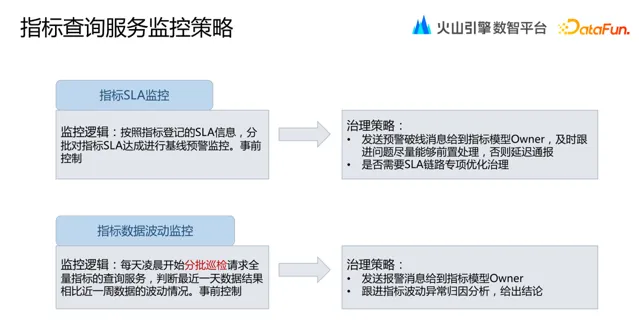
指標查詢服務監控包括:
多模型繫結查詢一致性監控: 支持多模型的指標體系,最擔心的就是指標不一致。 我們透過定時巡檢指標查詢服務,發現指標結果不一致,發送報警訊息到指標模型 Owner 。 此類問題需要在開發階段就將問題處理。
指標慢查詢 / 異常查詢監控: 對慢查詢同樣采取定時巡檢,事前處理。 對於查詢異常,透過服務介面的查詢日誌、使用者存取平台的埋點日誌,即時監控線上指標服務請求異常資訊。 發現異常時,按照指標服務登記場景的重要程度,分級發送報警訊息。
指標 SLA 監控: 對每個指標登記 SLA 資訊,進行基線預警監控,還要根據需要進行專項最佳化治理。
指標數據波動監控: 數據波動不一定是存在問題,但需要去分析其原因。
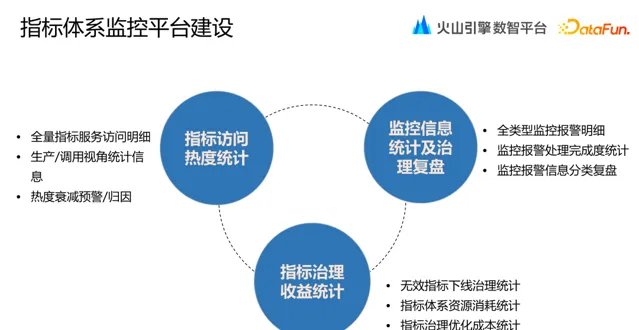
為了更直觀的看到指標體系服務的品質效果,我們構建了視覺化監控平台。該平台包括指標存取熱度統計、監控資訊統計和治理復盤,以及指標治理收益的統計。
04
構建全方位的指標套用場景
有了清晰的指標定義、穩定的指標模型生產、完備的指標監控體系以及統一的指標查詢服務,我們整體為懂車帝內部份析業務和外部線上業務提供了多樣化的套用場景。
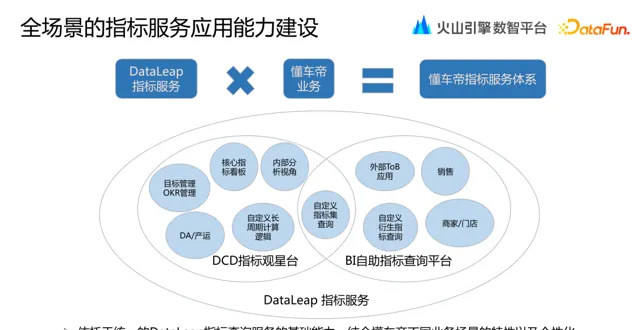
比如面向業務內部管理層檢視的核心指標看板,面向產品營運同學靈活業務分析的自助指標 BI 分析平台,以及面向汽車經銷商門店、銷售提效的商業化營運平台。
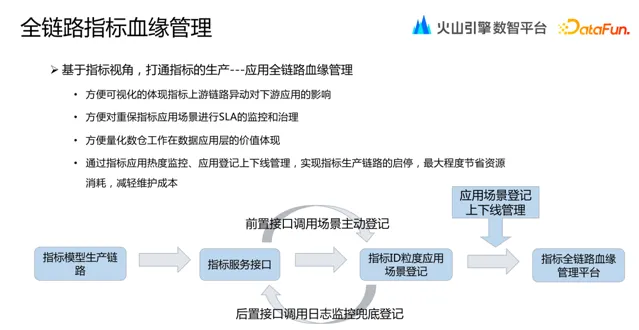
結合實際的業務使用場景,我們還建設了全鏈路指標血緣套用管理。血緣管理可以方便視覺化地體現指標上遊鏈路異動對下遊套用的影響,方便 SLA 治理,也方便量化數倉工作價值。
其中血緣管理包括前向鏈路和後向鏈路兩個過程。所有指標服務介面的呼叫都要在使用前做好介面呼叫場景的登記。即使某個指標服務跳過 SOP 沒有進行登記,我們也可以透過呼叫日誌監控發現遺漏,然後反向推動服務登記。透過這樣的措施,保證了數倉能夠對所有指標服務套用場景進行全面的掌控,以做好服務品質的管理。
05
未來展望
指標體系是一個持續建設過程,還會繼續完善。
未來,我們會結合 BSC(平衡計分卡),將指標體系與業務管理結合。將戰略目標、實作路徑、策略打法這些業務戰略規劃體現在指標體系中。
另外,要建設更加完整、統一的數據服務查詢層。現在借助 DataLeap 提供的數據服務介面,基本實作了指標粒度的統一服務查詢。未來要應對更復雜的查詢場景,提供不限於指標粒度的統一介面服務,實作一體化數據查詢服務。
最後還將考慮指標體系與大模型的結合,提供數據智慧的問答互動能力。透過自然語言互動模式為業務人員提供自主取數、快速找數、理解數據的能力。
06
問答環節
Q1 :拆解好的指標體系是按照原子指標、修飾詞、時間、維度,那麽實際儲存中是如何處理?
A1 :會區分原子指標、復合指標、衍生指標這幾種場景。對於原子指標,直接從業務到度量,儲存層面可以存在明細層。原子指標不存在跨域場景、不需要聚合。對於衍生指標、復合指標可能會涉及跨域的場景,在這種情況下需要考慮聚合到何種粒度。可以使用大寬表,也可以還在聚合層跨域查詢。在儲存層面,衍生指標、復合指標儲存在 DM 層。對外服務中,指標在查詢層面提供統一介面,原子指標直接查詢明細層,衍生指標、復合指標透過路由呼叫最優的模型來處理。
Q2 :如何保證語意相同的詞根不重復錄入?
A2 :平台中有一些演算法庫,提供智慧演算法辨識詞根的近義詞相似度。對於近似度高的詞根,進行人工排查。發現近義詞後,進行復盤,核實為近義詞後進行詞根剔出。
Q3 :對於同一個指標來自於不同的業務域、資料來源、商品範圍,數據應該如何處理?是先進行異構數據融合,還是分開建設。若是分開建設,如何保證這兩個口徑一致。
A3 :如果是同一個指標,資料來源、業務域都不一樣,首先需要判斷是否真的是同一個指標。如果是同一個指標,需要明確指標的業務定義,涉及指標口徑概念。比如,不同的商品範圍會對應商品範圍修飾詞,在不同修飾詞限定下是不同的衍生指標。指標開發中,結合不同的修飾詞在實際業務範圍中開發指標模型。可能在原子指標上是同一個概念、同一個過程、同一個度量詞,在不同修飾詞的背景下是不同的衍生指標,用不同的開發邏輯來處理。
Q4 :多模型繫結查詢具體是什麽?一個指標可以繫結多個模型嗎?
A4 :參考從指標模型到指標實作的繫結這頁 ppt。多模型繫結以 DAU 指標為例:可以透過每日活躍使用者的明細表來處理,可以按照省份、渠道聚合後來處理。在模型層面上是不同粒度、不同維度的模型,但是都是 DAU 指標。不同模型的輸出結果是一致的。不同維度分析的時候,可以更快的實作支持查詢。在查詢某個城市的 DAU 指標時,直接使用聚合後的模型更快速,不需要從明細表計算結果。路由查詢透過查詢維度選擇最優的模型來實作查詢。
Q5 :請再介紹一下指標血緣分析的方法。
A5 :血緣分析是一個全鏈路管理,包括生產鏈路和套用鏈路。生產鏈路中可以拿到數據的生產過程。不同的模型會有不同的數據生產上遊。在 SLA 治理場景下,如果要提前數據產出時間,可以透過鏈路來分析上遊各任務的生產時間,辨識慢任務、卡點任務。發現上級任務中瓶頸點後,可以透過最佳化對應模型來改善。對於下遊套用鏈路,主要是套用場景登記。透過套用場景登記,可以管控指標服務。比如,透過呼叫熱度統計,發現下遊呼叫方不再使用的指標服務,進行降級處理或者聯系服務呼叫方後進行指標下線處理。
Q6 :指標繫結模型,還是模型繫結指標?
A6 :先有業務需求,先定指標,然後根據指標設計模型。指標模型做到一定程度,可以考慮數據進一步發揮價值。這種情況先有模型然後來生成指標。
Q7 : 維度和修飾詞劃分的邊界是什麽?
A7 : 維度是模型中的欄位。修飾詞是維度中的列舉值。比如:維度是省份,修飾詞是山東省。
以上就是本次分享的內容,謝謝大家。

分享嘉賓
INTRODUCTION
肖繼哲
字節跳動
懂車帝資深數倉研發工程師
2017 年加入抖音集團旗下懂車帝數倉 團隊,一直從事業務數倉模型開發和數據服務建設的相關工作。先後負責離線/即時數倉模型開發、數倉開發規範制定、數據治理計畫、數據工程服務套用等工作,目前主要聚焦於業務數據指標體系的建設工作 。
課程推薦
往期推薦
點個 在看 你最好看











