点击上方 蓝字 关注我们
微信公众号: OpenCV学堂
关注获取更多计算机视觉 与深度学习知识
前言
在计算成像和计算机视觉领域,图像变形(IMAGE warping)至关重要,它是众多应用的基础,包括图像校正、图像矩形化、相机标定以及三维重建等。通过缩放、旋转和倾斜等过程对图像数据进行操作,可以实现不同视觉元素的无缝集成以及光学缺陷的校正。此外,在开发增强现实(AR)和虚拟现实(VR)应用时,图像变形也是不可或缺的,它有助于通过将纹理和图像精确映射到3D模型上,从而创建出沉浸式且逼真的环境。
MOWA
我们提出了一种名为 MOWA(Multiple-in-One图像变形模型)的模型 ,以解决实践中的各种任务,如图1所示。具体来说,我们考虑了计算摄影领域的六种代表性类型,即拼接图像、校正的广角图像、去卷帘图像、旋转图像、鱼眼图像和人像照片,这些类型涵盖了主流的实际图像变形任务。

MOWA模型结构
MOWA模型贡献主要有以下三点,分别是:
• 作者提出了MOWA,这是第一个实用的多合一图像变形框架。尽管该模型的规模适中,但它仍明显优于大多数最先进的方法。
• 我们提出通过解耦区域级和像素级的运动估计来缓解多任务学习的难度。此外,我们还设计了一个由轻量级基于点的分类器引导的快速学习模块,以促进任务感知的图像变形。
• 我们展示了通过多任务学习,我们的框架发展出了一种鲁棒的通用变形策略,该策略在各种任务上均表现出色,甚至能够泛化到未见过的任务上。
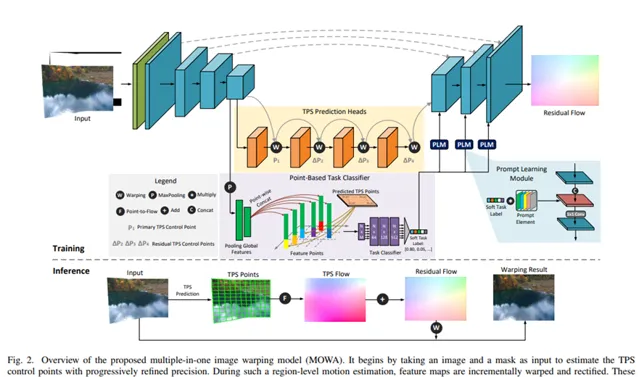
模型基于编码器-解码器架构设计,实现了区域级控制点回归和像素级残余流预测。具体来说,在编码器和解码器中(除了输入投影层和输出投影层外),都使用了带有移动窗口的Transformer块。编码器网络中通道的基本维度设置为32,并随着层数的增加而线性增加,而在解码器网络中则相反,逐渐减少到2。此外,每个Transformer块的深度设置为2,多头自注意力机制的头数在整个层中设置为[1, 2, 4, 8, 16, 16, 8, 4, 2]。在TPS预测头中,我们采用具有不同卷积核的卷积层来预测逐渐增加数量的控制点,数量分别设置为10×10、12×12、14×14和16×16。这些回归头的配置细节列于表I中。与全连接层相比,这种设计显著减少了参数。对于轻量级的基于点的分类器,我们使用了三个通道维度分别为256、256、512的1D卷积层来提取输入特征,然后使用三个单元数分别为512、256、6的全连接层来分类任务类型。

它接收图像和掩码作为输入,并估计出数量逐渐增加的TPS(薄板样条变换)控制点。在这种区域级运动估计中,特征图逐渐被扭曲和校正。随后,将扭曲后的特征输入到解码器中,以预测像素级的残余运动。为了实现任务感知和可扩展的能力,我们设计了一个轻量级的基于点的分类器和即时学习模块。

代码与使用
作者已经开源代码,参见这里:
https://github.com/KangLiao929/MOWA
论文地址
https://arxiv.org/pdf/2404.10716
C++ 推理
https://github.com/hpc203/MOWA-onnxrun
OpenCV4系统化学习

深度学习系统化学习

推荐阅读












