「客製」這件事在我們生活中十分常見。
但大模型的客製你見過嗎?🤔
文生圖模型的客製化現在發展迅速,但文生視訊模型的客製化還在研究中。
谷歌DeepMind團隊 的最新研究—— Still-Moving 框架,實作了 T2V 模型的客製化生成!!
掃碼加入AI交流群
獲得更多技術支持和交流

計畫簡介
視訊生成的客製化之所以仍然處於起步階段,主要原因是缺乏客製化視訊數據。
Still-Moving 是一個不需要客製視訊數據的創新型通用框架,可以對文本生成視訊模型進行客製化。
給定一個基於T2I模型構建的T2V模型, Still-Moving 可以 僅使用少量靜態參考影像,來 調整任何自訂的 T2I 權重與T2V模型保持一致, 並保留 T2V 模型的運動先驗 。
Demo
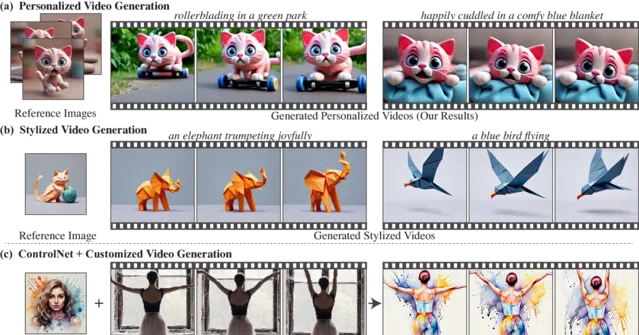
下面是透過調整個人化T2I模型來生成 個人化視訊 的範例。
參考圖

生成視訊
參考圖

生成視訊
參考圖

生成視訊
Still-Moving還可用於基於預訓練的風格化T2I模型,生成具有一致風格的視訊。
下面是 風格化視訊 生成的案例,這些視訊遵循參考影像的風格,同時也展現了T2V模型的自然運動。
參考圖

生成視訊
參考圖

生成視訊
參考圖

生成視訊
計畫原理
大家設想一下當我們看到一組靜態影像時,肯定能夠想象出這些影像中的主體在不同場景下的動態變化。👾
這種能力源於我們對物體運動、物理和動態的強烈先驗認知。
所以該研究的核心問題是:是否可以使用一個學會了運動先驗的生成視訊模型,來實作類似的人類想象能力?🤔
Still-Moving提出了一種 無需客製視訊數據 的方法,直接擴充套件T2I模型的客製化成果到T2V模型。
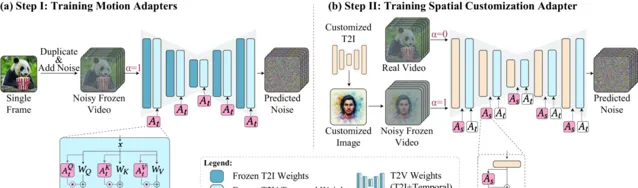
具體來說,Still-Moving透過兩個步驟實作客製化:
運動介面卡訓練 :引入運動介面卡,用於控制模型生成視訊的運動量。透過在靜態視訊上訓練這些介面卡,模型學會生成靜態視訊。
空間介面卡訓練 :註入客製化的T2I權重,並訓練空間介面卡,這些介面卡在組合了客製化影像和自然視訊的數據上進行訓練,從而在保持模型運動先驗的同時,適應客製化的空間先驗。
下面是團隊展示的使用不同比例的運動介面卡的效果比較。
DeepMind團隊在多個任務上展示了Still-Moving框架的有效性,包括個人化生成、風格化生成和條件生成。
在所有評估場景中,Still-Moving成功地結合了客製化T2I模型的空間先驗與T2V模型的運動先驗,生成了高品質的視訊內容。
下面將Still-Moving套用於AnimateDiff T2V模型,並將Still-Moving與簡單註入進行了比較,第二行是Still-Moving的結果。
參考圖

生成對比
同時團隊對Still-Moving和基線方法進行了定性比較。最後一列是Still-Moving的效果展示。
參考圖

生成對比
Still-Moving擴充套件了T2I模型的客製化成果到視訊生成領域,解決了缺乏客製化視訊數據的關鍵問題。
DeepMind團隊的這一創新實作了高品質的客製化視訊生成,小編期待後續團隊為AI生成領域的高樓再次添磚加瓦!
🔗 計畫連結 :
https://still-moving.github.io
關註「 向量光年 」公眾號
加速全行業向AI的改變
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點
關註「 AGI光年 」公眾號
獲取每日最新咨詢











