ByConity 是字節跳動開源的雲原生資料倉儲,在滿足數倉使用者對資源彈性擴縮容,讀寫分離,資源隔離,數據強一致性等多種需求的同時,提供優異的查詢,寫入效能。
GitHub:https://github.com/ByConity/ByConity
作者 | 程偉,MetaAPP 大數據研發工程師
MetaApp 是國內領先的遊戲開發與營運商,專註移動端資訊高效分發,致力於構建面向全年齡段的虛擬世界。截至 2023 年,MetaApp 註冊使用者已超 2 億,聯運合作 20 萬款遊戲,累計分發量過 10 億。
MetaApp 在 ByConity 開源早期便保持關註,是最早進行測試並在生產環境上線的使用者之一。抱著了解開源數倉計畫能力的想法,MetaApp 大數據研發團隊對 ByConity 進行了初步測試。其存算分離的架構、優秀的效能,尤其在日誌分析場景中,對於大規模數據復雜查詢的支持,吸引 MetaApp 對 ByConity 進行了深入測試,最終在生產環境全量替換 ClickHouse , 使資源成本降低超 50%。
本文將主要介紹 MetaApp 數據分析平台的功能,業務場景中遇到的問題及解決方案以及引入 ByConity 對其業務的幫助。
MetaApp OLAP 數據分析平台架構及功能
隨著業務的增長,精細化營運的提出,產品對數據部門提出了更高的要求,包括需要對即時數據進行查詢分析,快速調整營運策略;對小部份人群做 AB 實驗,驗證新功能的有效性;減少數據查詢時間,降低數據查詢難度,讓非專業人員可以自主分析、探查數據等。為滿足業務需求,MateApp 實作了集事件分析、轉化分析、自訂留存、使用者分群、行為流分析等功能於一體的 OLAP 數據分析平台。
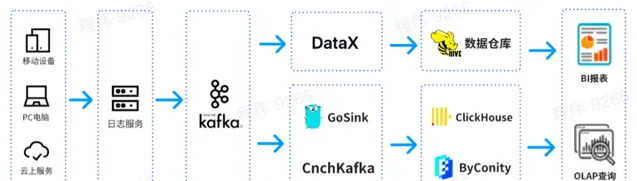
這是一個典型的 OLAP 的架構,分成兩部份,一部份是離線,一部份是即時。
在 離線場景 中,我們使用 DataX 把 Kafka 的數據整合到 Hive 數倉,再生成 BI 報表。BI 報表使用了 Superset 元件來進行結果展示;
在 即時場景 中,一條線使用 GoSink 進行數據整合,把 GoSink 的數據整合到 ClickHouse,另外一條線使用 CnchKafka 把數據整合到 ByConity。最後透過 OLAP 查詢平台獲取數據進行查詢。
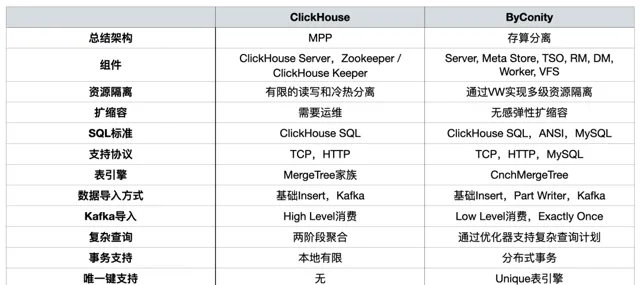
ByConity 和 ClickHouse 功能對比
ByConity 是基於 ClickHouse 內核研發的開源雲原生資料倉儲,采用存算分離的架構。兩者都具有以下特點:
寫入速度非常快,適用於大量數據的寫入,寫入數據量可達 50MB - 200MB/s
查詢速度非常快,在海量數據下,查詢速度可達2-30GB/s
資料壓縮比高,儲存成本低,壓縮比 可達 0.2~0.3
ByConity 擁有 ClickHouse 的優點,與 ClickHouse 保持了較好的相容性,在 讀寫分離、彈性擴縮容、數據強一致 方面進行了增強。兩者對於以下 OLAP 場景均適用:
數據集可能很大 - 數十億或數萬億行
數據表中包含許多列
僅查詢特定幾列
結果必須以毫秒或秒為單位返回
在之前的分享中, ,概括總結如下:
> 詳見:
在 OLAP 平台構建過程中,我們主要關註 資源隔離、在擴縮容、復雜查詢 ,以及 對分布式事務的支持 。
使用 ClickHouse 遇到的問題
問題一:讀寫一體容易搶占資源,無法保證讀/寫穩定
業務高峰期時,數據寫入將大量擠占 IO 和 CPU 資源,導致查詢受到影響(查詢時間變長)。數據查詢也是如此。
問題二:擴/縮容麻煩,周期長
擴/縮容時間長:由於機器在 IDC,屬於私有雲,其中一個問題在於,節點增加周期特別長。從增加節點需求發出到真正增加好節點需要一周到兩周的時間,影響業務;
無法快速進行擴縮容: 擴縮容以後要重新進行數據分布,否則節點壓力非常大。
問題三:運維繁瑣,業務高峰期無法保證 SLA
常常因為業務的節點故障導致數據查詢緩慢,數據寫入延遲(從延遲幾小時到幾天的程度);
業務高峰期時資源出現嚴重不足,短期內無法擴容資源,只能透過刪減部份業務的數據,為優先級高的業務提供服務;
業務低峰期時,資源大量空閑,成本虛高。 雖然我們在 IDC,但是 IDC 的機器購買也受成本控制,且不能無限制的節點擴容,另外在正常使用時也有一定的成本消耗;
無法和雲上資源進行互動使用。
引入 ByConity 後的改善效果
首先,ByConity 讀寫分離計算資源隔離可以保證讀寫任務比較穩定。如果讀的任務不夠,可以擴充套件相應資源,哪裏不夠補哪裏,包括使用雲上資源進行擴容。
其次,擴縮容比較簡單,可以在分鐘級別進行擴縮容。由於使用 HDFS/S3 分布式儲存,計算儲存分離,所以擴容以後不需要進行數據重分布,擴容後可以直接使用。
另外,雲原生部署,運維相對簡單。
HDFS/S3 的元件相對成熟穩定,擴縮容,災備方案成熟,出現問題可快速解決;
業務高峰期時,可以透過快速擴容資源保障 SLA;
業務低峰期時,可以透過縮減儲存/計算資源達到降低成本的目的。
ByConity 的使用與運維
ByConity 集群使用情況
目前,我們平台已經在業務場景穩定使用 ByConity。透過陸續遷移,ByConity 已經完全接管了 ClickHouse 集群的數據,並已經開始穩定提供服務。我們使用雲上 S3 加 K8s 的模式搭建了 ByConity 集群;同時使用了定時擴縮容方案,可以在工作日早上 10 點進行擴容,晚上 8 點進行縮容,一天只需要使用十多個小時的資源。透過計算,此方式比直接使用包年包月降低資源 40%- 50% 左右。另外,我們也正在推進 私有雲 + 公有雲 相結合的方式,以達到降低成本與提升服務穩定性的目的。
下圖為我們目前的使用情況,透過 OLAP 伺服器對線下 IDC 機房的 ClickHouse 集群和 ByConity 進行聯合查詢。短期內 ClickHouse 集群將依然使用,作為部份依賴 ClickHouse 業務的過渡。
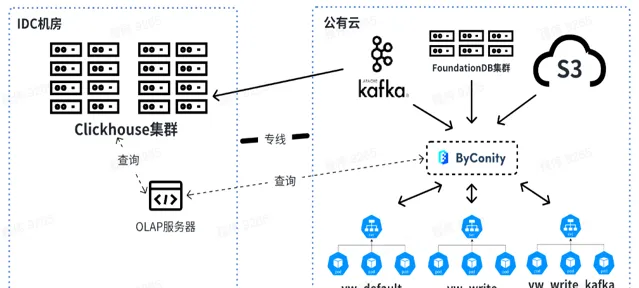
未來我們會線上下進行查詢和合並數據,而 Kafka 消耗的資源放到線上使用。在資源擴容時,可以將 vw_default 和 vw_write 的資源擴到線上,合理使用公有雲的資源應對資源不足的問題。同時在業務低峰時進行縮容,降低公有雲消耗。

ByConity 和 ClickHouse 在業務數據中的查詢對比
> 測試數據集及資源配置
數據條數:按日期做分區,單日 40 億條,10 日共計 400 億
表列數 據: 2800 列

由上表可以看出:
ClickHouse 集群查詢使用的資源為:400核 2560G記憶體
ByConity 8 worker 集群查詢使用的資源為:120核 880G記憶體
ByConity 16 worker 集群查詢使用的資源為:240核 1760G記憶體
> 業務 SQL 查詢結果匯總
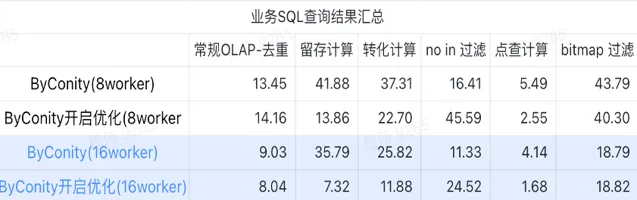
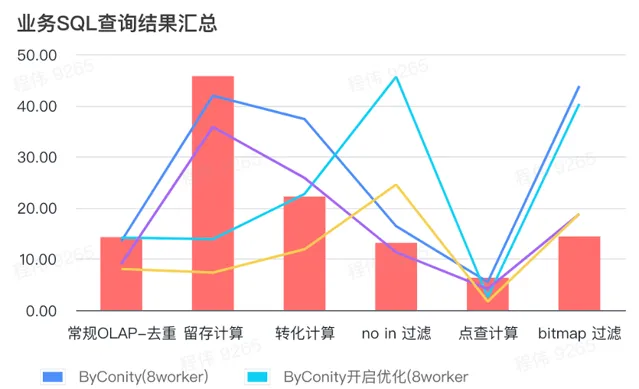
這裏的匯總都采用的是平均值,可以看到:
常規 OLAP - 去重、留存、轉化、點查都可以透過比較小的資源代價(120C, 880G)達到與 ClickHouse 集群(400C, 2560G)一致的查詢效果,並且可以透過擴充套件一倍資源(240C, 1760G)達到查詢速度提升翻倍的效果。如果需要更高的查詢速度,可以擴充套件更多的資源;
not in 過濾可能需要適中的資源代價(240C, 1760G)可以達到和 ClickHouse 集群(400C, 2560G)相似的效果;
bitmap 可能需要更大的資源代價可以達到和 ClickHouse 集群相似的效果。
常規查詢/事件分析查詢
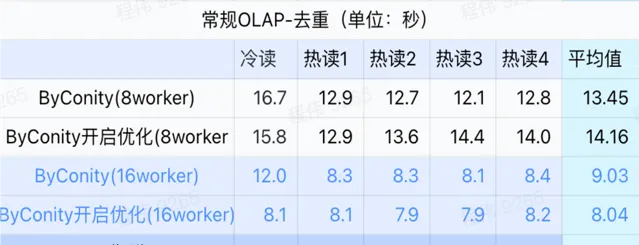
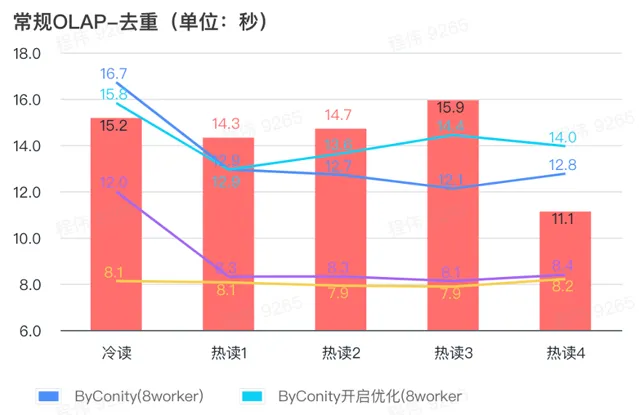
由上圖可知:
去重查詢場景上 ByConity 開啟最佳化與不開啟最佳化區別不大;
8 worker (120C 880G) 基本上達到與 ClickHouse 接近的查詢時間;
去重場景上,可以透過擴充套件計算資源來加快查詢速度。
留存計算
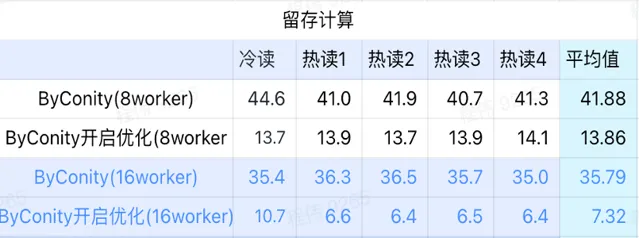
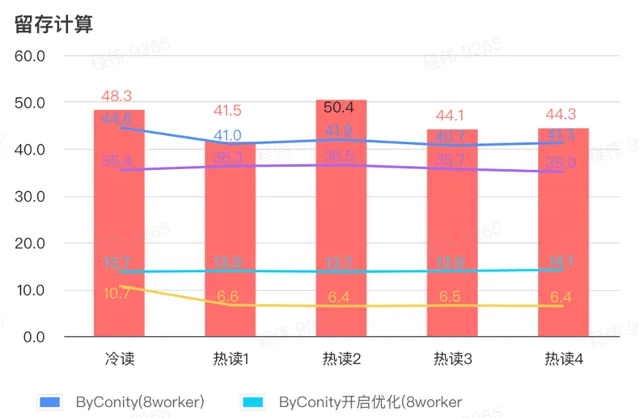
由上圖可知:
留存計算場景上 ByConity 開啟最佳化後查詢時間是不開啟最佳化查詢時間的33%;
8 worker (120C 880G) 開啟最佳化的查詢時間是 查詢時間的30%;
留存計算場景,可以透過擴充套件計算資源+最佳化的方式來將查詢速度加速至 CK查詢時間的16%。
轉化計算
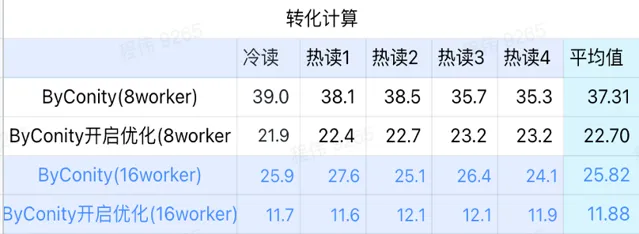
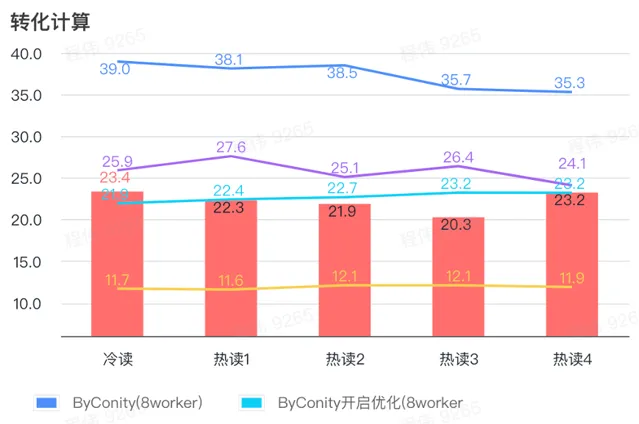
由上圖可知:
轉化計算場景上ByConity開啟最佳化後查詢時間是不開啟最佳化查詢時間的 60%;
8 worker (120C 880G) 開啟最佳化的查詢時間與 ClickHouse 查詢時間接近;
轉化計算場景,可以透過擴充套件計算資源+最佳化的方式將查詢速度加速至 ClickHouse 查詢時間的 53%。
not in 過濾
not in 過濾主要套用於使用者分群場景,以及使用者打標簽場景。
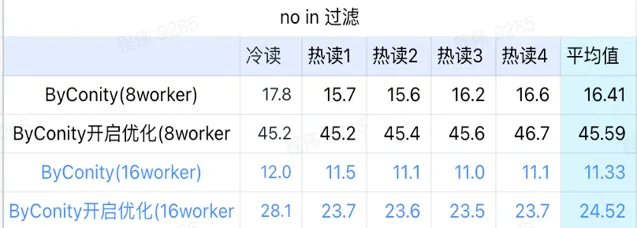
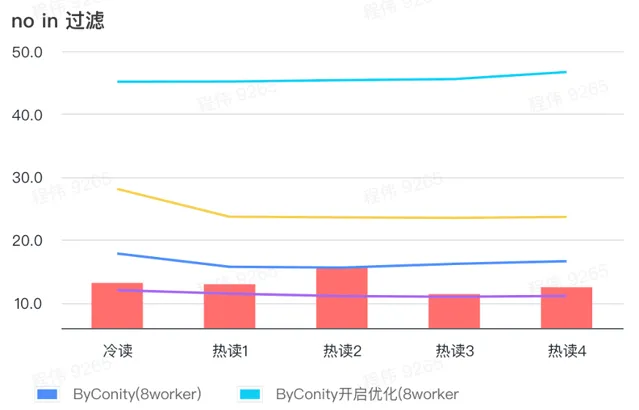
由上圖可知:
no in 過濾場景上 ByConity 開啟最佳化後比 ByConity 不開啟最佳化差,所以此場景下我們直接使用不開啟最佳化的方式;
8 worker (120C 880G) 不開啟最佳化的查詢時間比 ClickHouse 查詢時間慢一些,但並不多;
no in 過濾場景,可以透過擴充套件計算資源方式來將查詢速度加速至 ClickHouse 查詢時間的86%。
點查計算
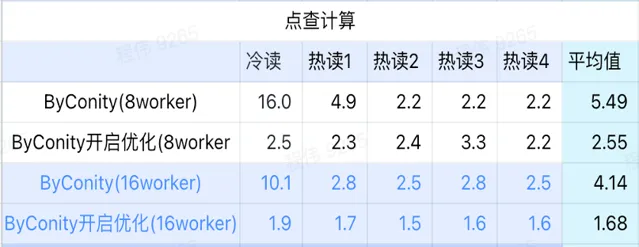
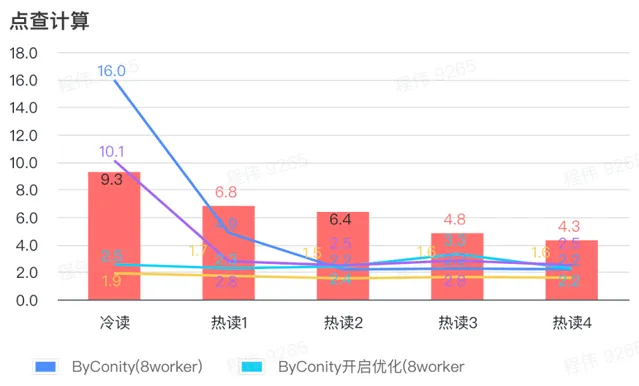
由上圖可知:
點查場景上 ByConity 開啟最佳化後比 ByConity 不開啟最佳化好;
8 worker (120C 880G) 不開啟最佳化的查詢時間與 ClickHouse 查詢時間接近;
點查場景,可以透過擴充套件計算資源+開啟最佳化的方式來將查詢速度加速至 ClickHouse 查詢時間的 26%。
bitmap 查詢
bitmap 查詢是在 AB 測試中使用更多的一種場景。
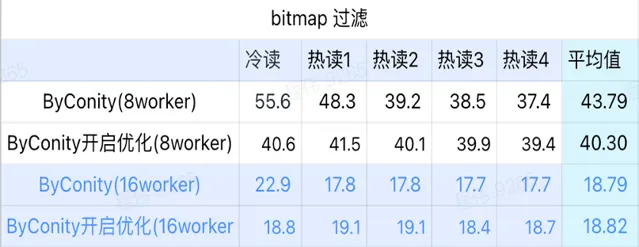
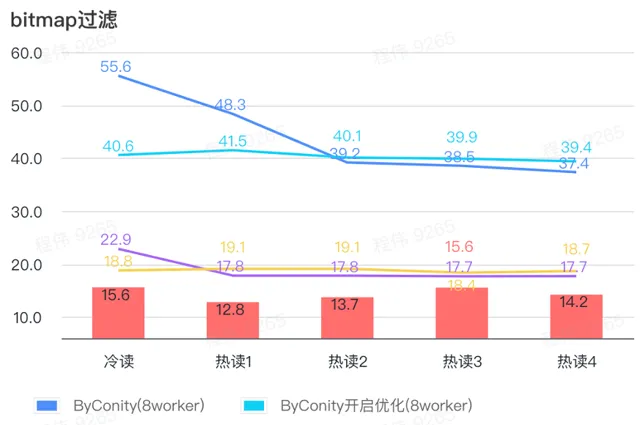
由上圖 可知:
bitmap 過濾場景上 ByConity 開啟最佳化後比 ByConity 不開啟最佳化好一點;
8 worker (120C 880G) 不開啟最佳化的查詢時間比 ClickHouse 查詢時間慢很多;
bitmap 過濾場景,擴充套件資源至 16 worker(240C 1769G) 比 ClickHouse 查詢慢。
ByConity 全量遷移後的收獲
> 資源降低
以下未統計 CPU 的差異性,數據僅供參考
使用 ByConity 進行全量遷移之後
查詢合並資源消耗對比,CPU 消耗比之前減少了 75% 左右;
數據寫入資源對比,CPU 消耗比之前減少了進 35% 左右;
只需要購買一半的固定資源,剩下一半靠工作日(早10晚8)定時彈性,成本相比全量購買資源降低了 25% 左右;
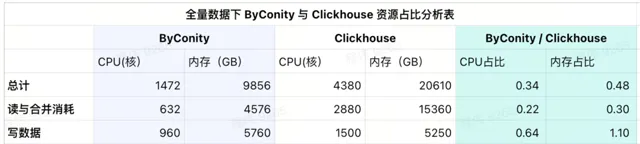
從當前使用的結果表中可以看到,ByConity 的 CPU 和 記憶體占比分別為 ClickHouse 的 34%和 48%。
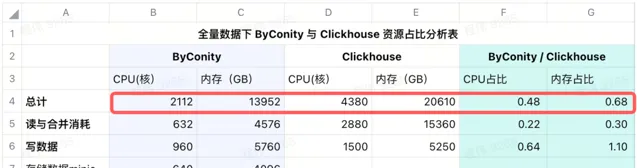
我們在 IDC 使用 minio 來進行數據儲存,使用 640 核的 CPU,4096G 記憶體,16個節點,單節點 40 核,256G,磁盤為 36T,把這些成本加在 ByConity 上之後,ByConity 的 CPU 和 記憶體占比依然低於 ClickHouse,分別為 ClickHouse 的 48% 和 68%。 可以說,在資源的使用上,如按包年包月購買資源計算,ByConity 比原來至少降低 50% 左右;如按需啟停,相比全量購買資源,成本將再降低 25% 左右。
> 運維成本降低
更簡單的配置數據寫入方式。之前我們專門配置的寫入服務,常常出現 Too many parts 等問題。
高峰查詢擴容更加簡單,添加 pod 數量就可以很快擴容,再也沒有人來問「數據查了半小時為啥沒出來」。
ByConity 替換 ClickHouse 的建議
在業務中測試你的 SQL 是否可以在 ByConity 平台上正常執行,如果能夠相容,則基本都可執行。如個別情況下出現一些小問題,可以在社群中提出,獲取快速反饋;
控制測試集群的資源,測試數據集大小,對比 ByConity 集群與 ClickHouse 集群的查詢結果,看是否符合預期。 如果符合預期,可以進行替換計劃。 對於更側重計算的任務,可能在 ByConity 中表現更好;
根據測試數據集的大小,消耗的 S3 和 HDF 空間、頻寬、QPS 計算資源的使用量,來評估全量數據時儲存與計算需要使用的資源;
將數據同時打入 ByConity 或者 ClickHouse 集群,開始一段時間的雙跑,解決雙跑期間出現的問題。 例如我們公司在資源不足的情況下,使用是按業務進行,我們可以先在雲上建一個 ByConity 集群,遷入某一部份的業務,之後逐步按業務來替換,騰出 IDC 資源以後,再把這一部份的數據遷移到線下;
雙跑沒有問題後就可以退訂 ClickHouse 集群。
在此過程中有一些註意事項:
S3 和 HDFS 遠端儲存的讀取頻寬與 QPS 可能會要求高一些,需要做一定的準備。例如,我們峰值每秒讀寫頻寬為:寫 2.5GB/讀 6GB,峰值每秒 QPS 為:2~6k;
Worker 節點的頻寬用滿,也會造成查詢瓶頸;
Default 節點(也就是讀取計算節點)的緩存盤可以配置的適當大一些,可以降低查詢時S3的頻寬壓力,加快查詢速度。
如果遇到未緩存的數據,可能會有冷啟動問題。 對此 ByConity 也有一些操作建議,具體還需要更多結合自己的業務進行,比如我們使用在早上進行預查的方式來將這一部份的冷啟動問題進行緩解。
未來規劃
未來我們將推動 ByConity 數據湖方案的測試與落地。
另外,我們會 將數據指標管理與數倉理論相結合,將 80%的查詢落到數倉上。歡迎大家一起加入體驗。
GitHub:https://github.com/ByConity/ByConity











