
文章來源|豆包大模型團隊
作為數據科學與機器學習經典競賽,Kaggle 以其高難度、高獎金、高關註度吸引了大量頂尖人才參與。Kaggle 競賽任務往往涉及需求理解、數據清洗和預處理、特征工程和建模等多個環節,需要參與者具備極強的專業知識與協作能力。
字節跳動豆包大模型團隊與 M-A-P 社群於近日提出 AutoKaggle ,為數據科學家提供了一個端到端的數據處理解決方案,幫助簡化和最佳化日常數據科學工作流程的同時,極大降低數據科學的門檻,可幫助更多沒有相關背景的使用者進行有價值的探索。在相關評估中,AutoKaggle 效能表現超出人類平均水平。
目前,該成果已經開源,本文將介紹其立項緣起、技術亮點及實驗中的更多結論。
大型語言模型(LLMs)近年來展現出驚人能力,遺憾的是,盡管 LLMs 在單一任務上表現出色,面對復雜、多步驟的計畫處理時,仍存在顯著缺陷。
以數據分析計畫為例,這類任務通常涉及 需求理解、數據清洗和預處理、探索性數據分析、特征工程和建模等 多個環節。每個步驟都需要專業知識和細致的規劃,通常需要多次叠代,門檻非常高。
基於上述背景,豆包大模型團隊與 M-A-P 社群聯合提出 AutoKaggle,一個端到端的數據處理解決方案。
AutoKaggle 透過構建一個多智慧體(Agent)的工作流,以提高邏輯復雜的數據科學任務中間決策步驟的可解釋性與透明性,並保持優秀效能及易用性,以降低理解難度和使用門檻。團隊認為,AutoKaggle 可系統地解決數據科學任務的復雜問題,保證程式碼魯棒、正確地生成。
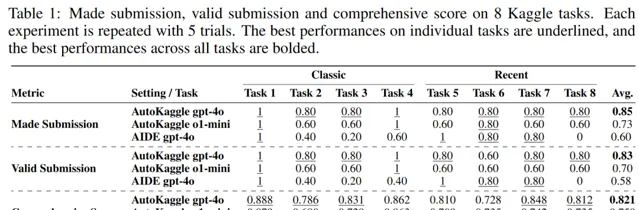
實驗結果表明,在對 8 個 Kaggle 競賽數據集的評估中,AutoKaggle 的有效送出率達到 85% ,綜合評分為 0.82 (滿分為 1), 超過了 在 MLE-Bench 中表現優秀的 AIDE 框架 ,展現了其在復雜數據科學任務中的高效性和廣泛適應力, 效能超過人類平均水平 !
目前,論文成果已經開源,同時,團隊針對 AutoKaggle 的執行結果提供了 詳細報告 ,可幫助大家觀察細節,以便進一步探索。
Au toKaggle: A Multi-Agent Framework for Autonomous Data Science Competitions
論文連結:
https://arxiv.org/abs/2410.20424
程式碼連結:
https://github.com/multimodal-art-projection/AutoKaggle
成果展示頁:
https://m-a-p.ai/AutoKaggle.github.io/

0 1
成為「 Kaggle 大神」有多難?
在介紹我們工作之前,先簡單介紹 Kaggle,以及計畫的復雜性。
Kaggle 是一個業內流行的數據科學競賽平台,企業和研究者可在其上釋出數據和問題,並提供獎金給解決問題的參賽者。 每個 Kaggle 競賽題目都是一座極其復雜的知識迷宮,沒有標準答案,只有無限逼近最優解,促使參與者不斷提出更好方案,探尋技術邊界。

Kaggle Days 在中國舉辦 來源:Kaggle官方
以醫療影像診斷為例,參賽者不僅需要熟練運用演算法,還須深入理解醫學專業知識,方能在極其微小的像素細節中,捕捉肉眼容易忽略的關鍵特征。
金融風險預測更是充滿不確定性,競賽者需要構建能穿透市場復雜波動的模型,在海量且充滿噪音的時間序列數據中,提取有價值的訊號。
而將這種復雜性推向極致的,則是氣候變遷預測,參與者要整合全球多源數據,模擬地球系統錯綜復雜的交互作用,在有限計算資源下做出精確預測。
這些題目不僅考驗技術能力,更對協同能力、領域知識提出極高要求。通常一個計畫參與人數能達到數千,只有 Top1 可以得到高額獎金。即便多個專家組隊協同開發,也只能提供一個不算差的方案,想再往前沖,則要有一定程度的默契和合作經驗。
高難度既代表高額獎金,亦意味著聲望。此前,Hinton 及其學生就曾在競賽中展示深度神經網路的強大能力,成為業內標誌性事件。而許多機器學習技術實力過硬的人才,也同樣因 「 Kaggle 大神」之名而被認可。
02
基於階段的多智慧體推理,疊加兩大重要模組
前文提及,Kaggle 競賽大部份任務往往涉及需求理解、數據清洗和預處理、探索性數據分析、特征工程和建模等多個環節。每個步驟需要專業知識和細致規劃,歷經多次叠代,門檻非常高。
為此,需要解決的問題包括:對整個任務的抽象和多智慧體協作、叠代偵錯和單元測試、使用復雜的機器學習知識、全面的報告。
帶著上述問題,團隊進行了如下工作:
架構設計
AutoKaggle 的核心是 基於階段的多智慧體推理 ,透過對競賽任務的抽象,將復雜數據科學問題轉化為可泛化的工作流。由兩套元件來完成這個任務: 多階段的工作流及多智慧體 。
我們將數據科學解題過程分為六個關鍵階段: 背景理解、初步探索性數據分析、數據清洗、深入探索性數據分析、特征工程以及模型構建、驗證和預測 。結構化的設計提供了清晰的問題解決路徑,確保各個方面都得到系統和全面的處理。
定義好每個階段需要解決的問題後,需要設計對應的智慧體以完成不同階段任務,它們分別為 Reader、Planner、Developer、Reviewer 和 Summarizer。這些智慧體在工作流程中,分別承擔 協同分析問題、制定策略、實施解決方案、審查結果並生成綜合報告 的角色。
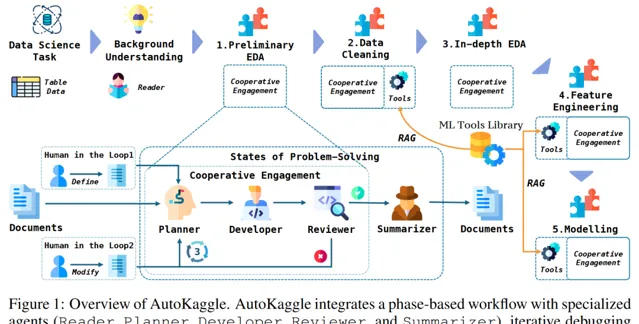
多智慧體協作的方式不僅提高了任務完成效率,還增強了系統靈活性和適應力,使得 AutoKaggle 能夠應對各種復雜的數據科學挑戰。
重要模組之程式碼開發模組
在架構之內,Developer 模組更復雜,也更值得分析。
團隊透過叠代開發與測試,構建了一個 自適應、魯棒的數據科學程式碼生成系統 。Developer 會基於當前狀態、Planner 提供的策略和上下文做初始程式碼生成。之後,Developer 進入叠代的偵錯和測試過程:
1) 執行生產的程式碼,如果有錯誤,則送入偵錯工具。
2) 程式碼偵錯工具基於原始碼和報錯資訊修改程式碼。
3) 單元測試生成的程式碼,透過多次程式碼執行、智慧偵錯和全面單元測試,實作了對復雜研發過程的精準控制。
在 Kaggle 競賽中,單純 確保程式碼無錯誤執行遠非充分條件 。競賽問題涉及復雜數據處理和精密演算法,其中隱藏的細微邏輯差錯往往對最終結果產生決定性影響。
因此,單元測試不僅需要驗證程式碼的形式正確,更要 深入審視其是否完全符合預期的邏輯和效能標準 。若忽視這點,微小誤差將在各階段累積,可能導致整個分析產生系統性偏差。
為降低這種潛在風險,必須對 每個開發階段進行極其細致的單元測試設計 ,全面覆蓋常規場景與邊緣情況。
該方法的核心優勢在於:動態捕獲潛在錯誤、即時修正程式碼邏輯、預防錯誤傳播,並在最小化人工幹預的前提下,保證了程式碼的正確性和一致性。由於引入了自我修復和持續最佳化機制, 能顯著提升程式碼生成水平 。

重要模組之機器學習工具庫
AutoKaggle 的機器學習工具庫,也是其架構的核心創新點。精心設計的三大工具集: 數據清洗、特征工程和模型構建與驗證 ,共同提供了一個全面、標準化的解決方案。
該庫不僅彌補了 LLM 在專業知識方面的固有局限,還透過七個數據清洗工具、十一個特征工程工具和綜合模型開發工具,實作了數據處理流程的智慧化和自動化。
其先進性體現在: 標準化的功能模組、全面的例外處理機制、對復雜 Kaggle 競賽場景的精準適配,以及能夠顯著降低技術實作復雜度 ,使多智慧體系統能更專註於高層次的戰略性任務規劃。每個工具的功能標準化使計畫能 無縫地共享和處理數據,提升特征品質,最佳化模型效能,從而提高整體工作流程的效率 。
可延伸性強,完整報告產出,使用者友好型框架
除技術方面優勢,AutoKaggle 還深度考慮到了使用者體驗,使其成為一個真正具有 可延伸性 和 使用者友好性 的框架,同時確保了數據處理過程的 透明性 ,提升使用者對於 AutoKaggle 解決方案的信任程度。
在可客製化方面,AutoKaggle 考慮到每位使用者的使用場景都獨具特色,透過開放客製化介面,使用者透過簡單的配置檔參數修改,即可客製整個數據處理流程。
此外,AutoKaggle 的機器學習工具庫設計高度開放,使用者只需提供一個函式及其配套的 Markdown 和 JSON 格式說明,即可延伸現有工具,滿足多樣化的使用者需求。
最後,為了提高 AutoKaggle 方案的可解釋性並實作整個數據處理流程的完全透明,AutoKaggle 在每個階段均提供了詳細報告,並在最後呈現競賽總結。
透過這些詳細的階段性報告,使用者不僅可以即時跟蹤 AutoKaggle 的工作進度,還能深入理解每個階段的分析邏輯,從而增強對框架的信任感。
詳情請見 https://github.com/multimodal-art-projection/AutoKaggle 。
03
在大多數評分中,AutoKaggle 展現出更優水平
我們將 8 個任務分為 classic 和 Recent 兩組,考慮到計畫依賴於 GPT4o,而該模型基於 2023 年 10 月以前可用數據進行訓練,因此,它可能包括大部份經典Kaggle 競賽數據。
為了更公平地評估工作流,我們選擇了 2023 年 10 月之前開始的、至少有 500 人參加的比賽,而 Recent 組選擇了 24 年後競賽問題。
我們對比了 AutoKaggle 與 AIDE 在不同維度的效能,包括任務送出、有效送出和綜合評分三個維度,可以看到, AutoKaggle 在大多數的評分中展現出更優水平 。
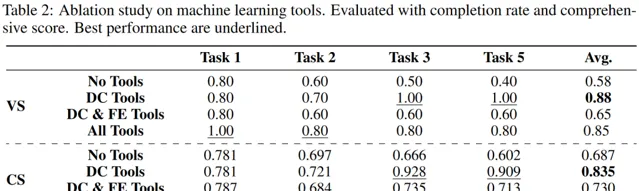
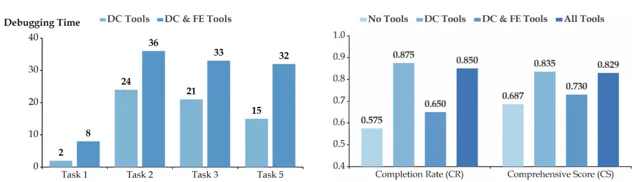
為了進一步探索其效能源於哪些因素,我們對比了 沒有使用任何工具、僅使用數據清洗工具、僅使用數據清洗和特征工程工具 以及 完全體 這四種場景的完成率和綜合評分。
可以看到,與沒使用任何工具相比,僅使用數據清洗工具的完成率最高, 提升 30% ,而使用了所有工具的完成率僅提高 27%。加入特征工程以後,完成率呈下降趨勢,這種下降可能因為涉及的特征數量相對較多,加之此階段工具的復雜性和高封裝性,需要增刪特征,從而讓使用變得復雜。
從下方左圖能觀察到,加入特征工程工具後, Debugging Time 顯著高於只使用數據清洗工具 。這種復雜性讓 Developer 們偵錯錯誤程式碼變難,也可能是效能下降的原因。
且從下方右圖可以看到,不同場景對於效能的影響。盡管機器學習工具庫並未顯著提升解決方案上限,但它作為一個更穩定的工具,提高了 AutoKaggle 的完成率。
而在沒有單元測試的情況下,完成率顯著降低,完成任務幾乎變得不可能。
這意味著,對於像數據科學為代表的高精度和邏輯要求的任務, 僅僅讓程式碼每個階段可執行且不出錯並不夠, 需要進行全面的單元測試,以確保程式碼邏輯正確,並實作每個階段的目標。

最後,我們統計了不同錯誤型別及出現次數,可以看到,每個子任務階段都有可能發生錯誤。數據清洗和特征工程錯誤率最高,分別為 25% 和 22.5%。值得註意的是,在特征工程階段的錯誤導致了 31.25% 任務失敗。

但是,團隊為開發者提供了詳細的偵錯過程。以檔未找到錯誤為例,偵錯工作流程如下:
1)錯誤定位 :開發人員最初遇到執行指令碼時出現問題,涉及檔保存操作。
2)錯誤修復 :為了解決這些問題,提出了幾個修改建議。
3)合並程式碼片段 :將已修正的片段合並回正確的原始程式碼,以建立一個無縫且穩健的解決方案。
04
一些思考
AutoKaggle 提供了一個健壯的框架以完成數據科學探索,基於各種 Kaggle 競賽問題的廣泛評估,證明了其有效性。該成果既展示了 多智慧體對於模型能力邊界的提升 ,也證明了,如果能把工作流抽象出來就能解決足夠復雜的問題, 為大模型套用提供了更多可能性 。當然,我們也留下一些遺憾,比如,無法在數據集規模特別大的比賽中,驗證 AutoKaggle 效能。
未來,團隊成員還將繼續探索智數據科學課題及相關開源工作,並關註 Kaggle 上的最新前沿技術,如果你也對智慧體協作、數據科學、大模型對復雜問題的解決感興趣,有誌於探索前沿課題, 歡迎關註「豆包大模型團隊」微信公眾號,或點選閱讀原文前往官網,了解更多資訊 。
推薦閱讀
點選「閱讀原文」,了解更多豆包大模型團隊資訊!











