點選「 IT碼徒 」, 關註,置頂 公眾號
每日技術幹貨,第一時間送達!
本文主要去理解 offset 為什麽會在大數據量下的查詢帶來效能問題?思考完後,可以在思考下,如果分庫分表,你會這麽去分頁呢?
不需要擔心資料庫效能最佳化問題的日子已經一去不復返了。
隨著時代的進步,隨著野心勃勃的企業想要變成下一個 Facebook,隨著為機器學習預測收集盡可能多數據的想法的出現。
作為開發人員,我們要不斷地打磨我們的 API,讓它們提供可靠和有效的端點,從而毫不費力地瀏覽海量數據。
如果你做過後台開發或資料庫架構,你可能是這麽分頁的:

如果你真的是這麽分頁,那麽我不得不抱歉地說,你這樣做是錯的。
你不以為然?沒關系。Slack、Shopify 和 Mixmax 這些公司都在用,我們今天將要討論的方式進行分頁。
我想你很難找出一個不使用 OFFSET 和 LIMIT 進行資料庫分頁的人。對於簡單的小型應用程式和數據量不是很大的場景,這種方式還是能夠「應付」的。
如果你想從頭開始構建一個可靠且高效的系統,在一開始就要把它做好。
今天我們將探討已經被廣泛使用的分頁方式存在的問題,以及如何實作高效能分頁。
1
OFFSET 和 LIMIT 有什麽問題?
正如前面段落所說的那樣,OFFSET 和 LIMIT 對於數據量少的計畫來說是沒有問題的。
但是,當資料庫裏的數據量超過伺服器記憶體能夠儲存的能力,並且需要對所有數據進行分頁,問題就會出現。
為了實作分頁,每次收到分頁請求時,資料庫都需要進行低效的全表掃描。
什麽是全表掃描?全表掃描 (又稱順序掃描) 就是在資料庫中進行逐行掃描,順序讀取表中的每一行記錄,然後檢查各個列是否符合查詢條件。
這種掃描是已知最慢的,因為需要進行大量的磁盤 I/O,而且從磁盤到記憶體的傳輸開銷也很大。
這意味著,如果你有 1 億個使用者,OFFSET 是 5 千萬,那麽它需要獲取所有這些記錄 (包括那麽多根本不需要的數據),將它們放入記憶體,然後獲取 LIMIT 指定的 20 條結果。
也就是說,為了獲取一頁的數據:
10萬行中的第5萬行到第5萬零20行
需要先獲取 5 萬行。這麽做是多麽低效?如果你不相信,可以看看這個例子:
https://www.db-fiddle.com/f/3JSpBxVgcqL3W2AzfRNCyq/1?ref=hackernoon.com
左邊的 Schema SQL 將插入 10 萬行數據,右邊有一個效能很差的查詢和一個較好的解決方案。
只需單擊頂部的 Run,就可以比較它們的執行時間。第一個查詢的執行時間至少是第二個查詢的 30 倍。
數據越多,情況就越糟。看看我對 10 萬行數據進行的 PoC:
https://github.com/IvoPereira/Efficient-Pagination-SQL-PoC?ref=hackernoon.com
現在你應該知道這背後都發生了什麽:OFFSET 越高,查詢時間就越長。
2
替代方案
你應該這樣做:

這是一種基於指標的分頁。
你要在本地保存上一次接收到的主鍵 (通常是一個 ID) 和 LIMIT,而不是 OFFSET 和 LIMIT,那麽每一次的查詢可能都與此類似。
為什麽?因為透過顯式告知資料庫最新行,資料庫就確切地知道從哪裏開始搜尋(基於有效的索引),而不需要考慮目標範圍之外的記錄。
比較這個查詢:
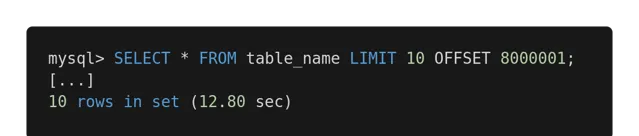
和最佳化的版本:

返回同樣的結果,第一個查詢使用了 12.80 秒,而第二個僅用了 0.01 秒。
要使用這種基於遊標的分頁,需要有一個惟一的序列欄位 (或多個),比如惟一的整數 ID 或時間戳,但在某些特定情況下可能無法滿足這個條件。
我的建議是,不管怎樣都要考慮每種解決方案的優缺點,以及需要執行哪種查詢。
如果需要基於大量數據做查詢操作,Rick James 的文章提供了更深入的指導:
http://mysql.rjweb.org/doc.php/lists
如果我們的表沒有主鍵,比如是具有多對多關系的表,那麽就使用傳統的 OFFSET/LIMIT 方式,只是這樣做存在潛在的慢查詢問題。
我建議在需要分頁的表中使用自動遞增的主鍵,即使只是為了分頁。
來源:51CTO技術棧
— END —
PS:防止找不到本篇文章,可以收藏點贊,方便翻閱尋找哦。
往期推薦











