點選關註公眾號,Java幹貨 及時送達 👇

測試環境:
MySQL版本:8.0
資料庫表:T (主鍵id,唯一索引c,普通欄位d)

如果你的業務設計依賴於自增主鍵的連續性,這個設計假設自增主鍵是連續的。但實際上,這樣的假設是錯的,因為自增主鍵不能保證連續遞增。
一、自增值的內容特征:
1. 自增主鍵值是儲存在哪的?
MySQL5.7版本
在 MySQL 5.7 及之前的版本,自增值保存在記憶體裏,並沒有持久化。每次重新開機後,第一次開啟表的時候,都會去找自增值的最大值
max(id)
,然後將
max(id)+1
作為這個表當前的自增值。
MySQL8.0之後版本
在 MySQL 8.0 版本,將自增值的變更記錄在了
redo log
中,重新開機的時候依靠
redo log
恢復重新開機之前的值。
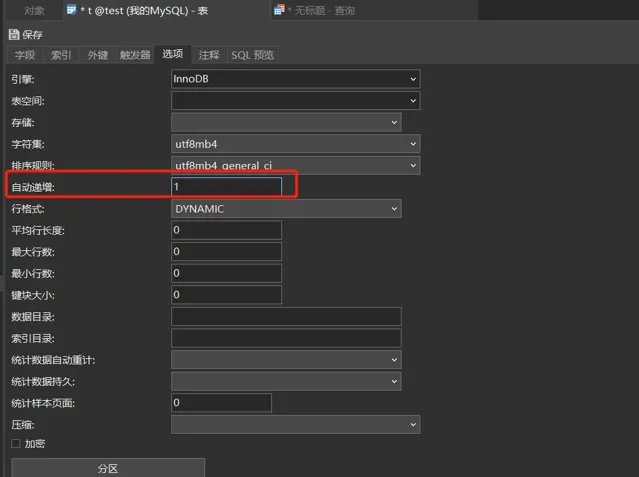
可以透過看表詳情檢視當前自增值,以及檢視表參數詳情
AUTO_INCREMENT
值(
AUTO_INCREMENT
就是當前數據表的自增值)
2. 自增主鍵值的修改機制?
在表t中,我定義了主鍵id為自增值,在插入一行數據的時候,自增值的行為如下:
如果插入數據時 id 欄位指定為 0、null 或未指定值,那麽就把這個表當前的
AUTO_INCREMENT值填到自增欄位;如果插入數據時 id 欄位指定了具體的值,就直接使用語句裏指定的值。
根據要插入的值和當前自增值的大小關系,自增值的變更結果也會有所不同。假設,某次要插入的值是 X,當前的自增值是 Y。
如果 X<Y,那麽這個表的自增值不變;
如果 X≥Y,就需要把當前自增值修改為新的自增值。
二、新增語句自增主鍵是如何變化的:
我們執行以下SQL語句,來觀察自增主鍵是如何進行變化的
insertinto t values(null, 1, 1);
流程圖如下所示
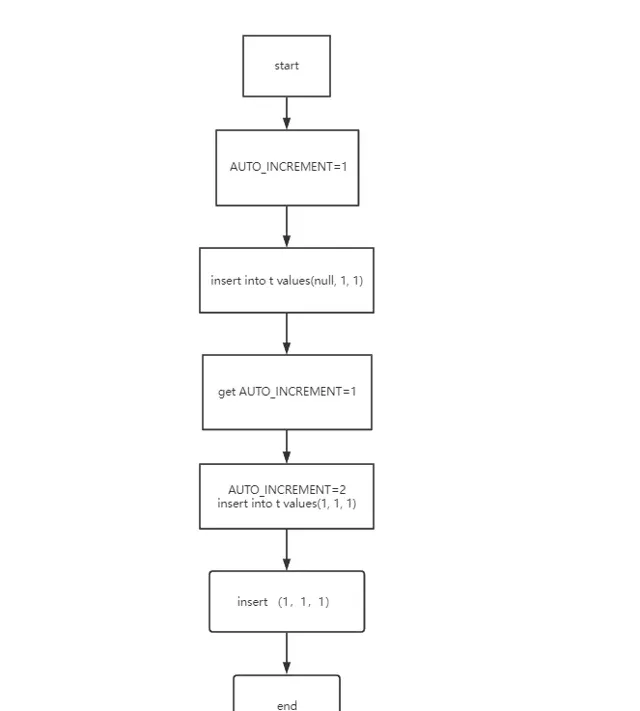
流程步驟:
AUTO_INCREMENT=1 (表示下一次插入數據時,如果需要自動生成自增值,會生成 id=1。)
insert into t values(null, 1, 1) (執行器呼叫 InnoDB 引擎介面寫入一行,傳入的這一行的值是 (0,1,1))
get AUTO_INCREMENT=1 (InnoDB 發現使用者沒有指定自增 id 的值,獲取表 t 當前的自增值 1 )
AUTO_INCREMENT=2 insert into t values(1, 1, 1) (將傳入的行的值改成 (1,1,1),並把自增值改為2)
insert (1,1,1) 執行插入操作,至此流程結束
大家可以發現,在這個流程當中是先進行自增值的+1,在進行新增語句的執行的。大家可以發現這個操作並沒有進行原子操作,如果SQL語句執行失敗,那麽自增是不是就不會連續了呢?
三、自增主鍵值不連續情況:(唯一主鍵沖突)
當我執行以下SQL語句時
insertinto t values(null, 1, 1);
第一次我們可以進行新增成功,根據自增值的修改機制。如果插入數據時 id 欄位指定為 0、null 或未指定值,那麽就把這個表當前的
AUTO_INCREMENT
值填到自增欄位;
當我們第二次在執行以下SQL語句時,就會出現錯誤。因為我們表中c欄位是唯一索引,會出現
Duplicate key error
錯誤導致新增失敗。
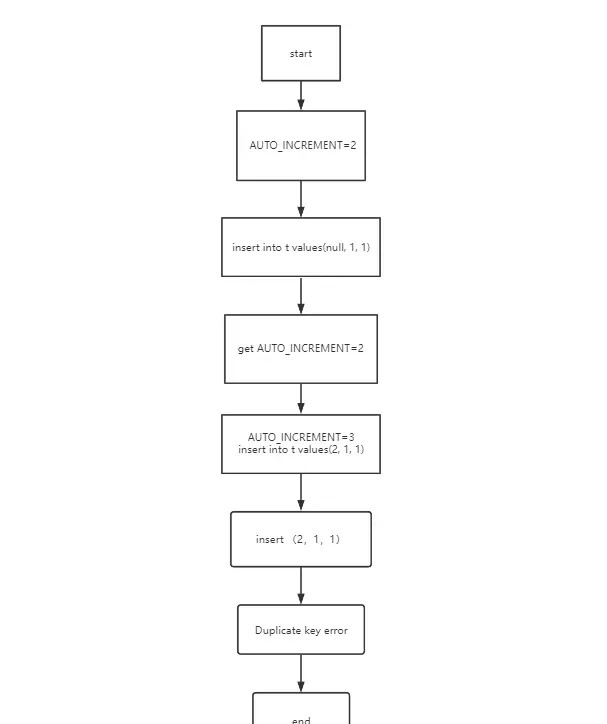
例如:
AUTO_INCREMENT=2 (表示下一次插入數據時,如果需要自動生成自增值,會生成 id=2。)
insert into t values(null, 1, 1) (執行器呼叫 InnoDB 引擎介面寫入一行,傳入的這一行的值是 (0,1,1))
get AUTO_INCREMENT=2 (InnoDB 發現使用者沒有指定自增 id 的值,獲取表 t 當前的自增值 2 )
AUTO_INCREMENT=3 insert into t values(2, 1, 1) (將傳入的行的值改成 (2,1,1),並把自增值改為3)
insert (2,1,1)
執行插入操作,由於已經存在 c=1 的記錄,所以報
Duplicate key error
,語句返回。
可以看到,這個表的自增值改成 3,是在真正執行插入數據的操作之前。這個語句真正執行的時候,因為碰到唯一鍵 c 沖突,所以 id=2 這一行並沒有插入成功,但也沒有將自增值再改回去。所以,在這之後,再插入新的數據行時,拿到的自增 id 就是 3。也就是說,出現了自增主鍵不連續的情況。
四、自增主鍵值不連續情況:(事務回滾)
其實事務回滾原理也和上面一樣,都是因為異常導致新增失敗,但是自增值沒有進行回退。
五、自增主鍵值不連續情況:(批次插入)
批次插入數據的語句,MySQL 有一個批次申請自增 id 的策略:
語句執行過程中,第一次申請自增 id,會分配 1 個;
1 個用完以後,這個語句第二次申請自增 id,會分配 2 個;
2 個用完以後,還是這個語句, 第三次申請自增 id,會分配 4 個;
依此類推,同一個語句去申請自增 id,每次申請到的自增 id 個數都是上一次的兩倍。
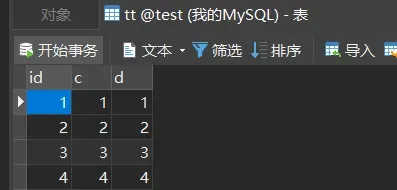
執行以下SQL語句(在表t中先新增了4條數據,在建立表tt把表t數據進行批次新增)
insertinto t values(null, 1,1);
insertinto t values(null, 2,2);
insertinto t values(null, 3,3);
insertinto t values(null, 4,4);
createtable tt like t;
insertinto tt(c,d) select c,d from t;
insertinto tt values(null, 5,5);
第一次申請到了 id=1,第二次被分配了 id=2 和 id=3, 第三次被分配到 id=4 到 id=7。當我們再執行
insert into t2 values(null, 5,5)
,實際上插入的數據就是(8,5,5),出現了自增主鍵不連續的情況。
六、自增主鍵值的最佳化
1.什麽是自增鎖
自增鎖是一種比擬非凡的表級鎖。並且在事務向蘊含了
AUTO_INCREMENT
列的表中新增數據時就會去持有自增鎖,假如事務 A 正在做這個操作,如果另一個事務 B 嘗試執行 INSERT語句,事務 B 會被阻塞住,直到事務 A 開釋自增鎖。
2.自增鎖有哪些最佳化
在 MySQL 5.0 版本的時候,自增鎖的範圍是語句級別。也就是說,如果一個語句申請了一個表自增鎖,這個鎖會等語句執行結束以後才釋放。顯然,這樣設計會影響並行度。在MySQL 5.1.22 版本引入了一個新策略,新增參數
innodb_autoinc_lock_mode
,預設值是 1。
傳統模式(Traditional)
這個參數的值被設定為 0 時,表示采用之前 MySQL 5.0 版本的策略,即語句執行結束後才釋放鎖;
傳統模式他可以保證數據一致性,但是如果有多個事務並行的執行 INSERT 操作,
AUTO-INC
的存在會使得 MySQL 的效能略有降落,因為同時只能執行一條 INSERT 語句。
間斷模式(Consecutive)
這個參數的值被設定為 1 時:普通 insert 語句,自增鎖在申請之後就馬上釋放;類似
insert … select
這樣的批次插入數據的語句,自增鎖還是要等語句結束後才被釋放;
間斷模式他可以保證數據一致性,但是如果有多個事務並行的執行 INSERT 批次操作時,就會進行鎖等待狀態。如果我們業務插入數據量很大時,這個時候MySQL的效能就會大大下降。
穿插模式(Interleaved)
這個參數的值被設定為 2 時,所有的申請自增主鍵的動作都是申請後就釋放鎖。
穿插模式他沒有進行任何的上鎖設定。在一定情況下是保證了MySQL的效能,但是他無法保證數據的一致性。如果我們在穿插模式下進行主從復制時,如果你的binlog格式不是row格式,主從復制就會出現不一致。
七、MySQL8.0做了哪些最佳化
在MySQL8.0之後版本,已經預設設定為
innodb_autoinc_lock_mode=2
,
binlog_format=row.
。這樣更有利與我們在
insert … select
這種批次插入數據的場景時,既能提升並行性,又不會出現數據一致性問題。
作者:又欠
來源:blog.csdn.net/qq_48157004/article/
details/128356734
END
看完本文有收獲?請轉發分享給更多人
關註「Java編程鴨」,提升Java技能
關註Java編程鴨微信公眾號,後台回復:碼農大禮包可以獲取最新整理的技術資料一份。涵蓋Java 框架學習、架構師學習等!
文章有幫助的話,在看,轉發吧。
謝謝支持喲 (*^__^*)











