一、背景
一套監控系統檢測和告警是密不可分的,檢測用來發現異常,告警用來將問題資訊發送給相應的人。vivo監控系統1.0時代各個監控系統分別維護一套計算、儲存、檢測、告警收斂邏輯,這種架構下對底層數據融合非常不利,也就無法實作監控系統更廣泛場景的套用,所以需要進行整體規劃,重新對整個監控系統架構進行調整,在這樣的背景下統一監控的目標被確立。
以前監控被劃分為基礎監控、通用監控、呼叫鏈、日誌監控、撥測監控等幾大系統,統一監控的目標是將各個監控指標數據進行統一計算、統一儲存、統一檢測、統一告警、統一展示。這裏不作贅述,後面會出一期vivo監控系統演進的文章進一步說明。
上面我們說了監控統一的大背景。以前各個監控系統會各自進行告警收斂、訊息組裝等工作,為了減少冗余,需要將收斂等工作由一個服務統一做處理,與此同時告警中心平台也到了更新叠代的階段,這樣就需要建設一個對內部各業務統一提供告警收斂、訊息組裝、告警發送的告警平台,有了這個構想,我們準備將各系統告警收斂能力與告警發送能力下沈,將統一告警服務做成一個與各監控服務解偶的通用服務。
二、現狀分析
對於1.0時代的監控系統來說,如圖1所示各個監控系統要先進行告警收斂,然後分別和老的告警中心進行對接,才能將告警訊息發送出來。每一套系統都要單獨進行維護一套規則,有很多重復功能建設,而實際這些功能具有高度通用性,完全可以建立合理模型對異常檢測服務生成的異常進行統一處理,從而生成問題,然後進行統一的訊息組裝,最後發送告警訊息。

( 圖1 老監控系統告警流程圖)
在監控系統中一個異常從被檢測出來到最終發出告警有幾個重要概念:
異常
在一個檢測視窗(視窗大小可以自訂),一個或幾個指標值達到檢測規則定義的異常閾值,就產生一個異常。如圖2所示,檢測規則定義當指標值在一個檢測視窗為6的檢測周期內,有3個數據點超過閾值就認為有異常,我們簡稱這個檢測規則為6-3,如圖所示第一個檢測視窗內(藍色虛線筐內)只有6和7兩個點的指標值超過閾值(95),不滿足6-3的條件,所以第一個檢測視窗沒有異常。在第二個檢測視窗內(綠色虛線框內)有6、7、8三個點的指標值超過閾值(95),所以第二個視窗就是一個異常。
問題
一個連續的周期內產生的所有同類異常的集合,我們稱之為問題。如圖2所示,第二個檢測視窗就是一個異常,同時這個異常也會對應有一個問題A,如果第三個檢測視窗也是一個異常,那麽這個異常對應的問題也是A,所以問題和異常是一對多的關系。
告警
當一個問題透過告警系統將訊息以簡訊、電話、信件等方式告知給使用者時,我們稱之為一條告警。
恢復
當問題對應的異常不滿足檢測規則定義的異常條件時,就認為所有異常都恢復了,同時問題也認為恢復了,恢復也會發送相應的恢復通知。
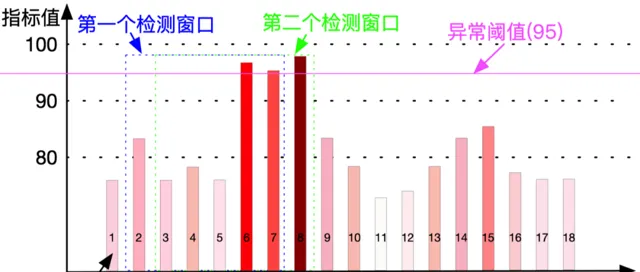
( 圖2 時序數據異常檢測原理圖)
三、衡量指標
一個系統我們如何衡量它的好壞,如何提升它,如何管理它? 管理學大師彼得·德魯克曾說「你如果無法度量它,就無法管理它(If you can’t measure it, you can’t manage it) 」。 從這裏可以看出,如果想全面管理提升一個系統,就需要先對它的各項效能指標有一個衡量,知道它的薄弱點在哪裏,找到病癥所在才能對癥下藥。

( 圖3 運維指標時間節點關系圖)
圖3是監控系統營運指標和對應時間節點關系圖,主要體現了MTTD、MTTA、MTTF、MTTR、MTBF等指標與時間節點的對應關系,這些指標對於提升系統效能,幫助運維團隊及早發現問題有很高的參考價值。業界有很多雲告警平台也很註重這些指標,下面我們著重介紹一下MTTA、MTTR這兩個和告警平台關系緊密的指標:
MTTA (Mean time to acknowledge,平均應答時間):
(圖4 MTTA計算公式)
t[i] -- 監控系統執行期間第i個服務出現問題後運維團隊或者研發人員響應問題的時間;
r[i] -- 監控系統執行期間第i個服務出現問題的總次數。
平均應答時間是運維團隊或者研發團隊響應所有問題所花費的平均時間。MTTA度量標準用於衡量運維團隊或研發團隊的響應能力和警報系統的效率。透過跟蹤和最小化MTTA,計畫管理團隊可以最佳化流程,提高問題解決效率,保障服務可用性,提升使用者滿意度[1]。
MTTR (Mean Time To Repair,平均維修時間):
(圖5 MTTR計算公式[2])
t[ri] -- 監控系統執行期間第i個服務出現r次告警後服務恢復正常狀態的總時間
r[i] -- 監控系統執行期間第i個服務出現告警的總次數
平均修復時間(MTTR)是修復系統並將其恢復到正常功能所需的平均時間。運維或研發人員開始處理異常,MTTR便開始計算,並且一直進行到被中斷的服務完全恢復(包括所需的任何測試時間)為止。在IT服務管理行業中,MTTR中的R並不總是表示維修。它也可以表示恢復,響應或解決。盡管這些指標都對應MTTR,但是它們都有各自的含義,因此,要弄清楚要使用哪個MTTR,有助於我們更好的分析理解問題。讓我們簡要地看一下它們各自的含義:
1)平均恢復時間 (Mean time to recovery)是從系統告警中恢復所需的平均時間。這涵蓋了從服務異常導致告警到恢復正常的整個過程。MTTR是衡量整個恢復過程速度的指標。
2)平均響應時間 (Mean time to respond)表示從出現第一個告警開始到系統從故障中恢復到正常狀態所需的平均時間,不包括告警系統中的任何延遲。該MTTR通常用於網路安全中,以衡量團隊緩解系統攻擊的效率。
3)平均解決時間 (Mean time to resolve)表示完全解決系統故障所花費的平均時間,包括檢測故障、診斷問題以及確保故障不再發生來解決問題所需的時間。此 MTTR 指標主要用於衡量不可預見事件的解決過程,而不是服務請求。
提升 MTTA 的核心是找對人、找到人[3],只有在最短的時間內找對能處理問題的人才能有效提升MTTR。通常在生產實踐過程中我們會遇到「告警泛濫」的問題,大量的告警出現時需要運維人員或者開發同學去解決,對於應激敏感的同學來說很容易出現「狼來了」的現象,只要收到告警就會很緊張,同時當大量的告警資訊頻發騷擾我們運維人員,會引發告警疲勞,體現為不重要的事件太多,最根本的問題較少,頻繁處理普通事件,重要的資訊淹沒在汪洋大海中。[4]
(圖6 告警泛濫問題圖[5])
四、功能設計
透過上面兩個重要指標的分析,我們總結出要從 告警數量 、 告警收斂 、 告警升級 等方面著手,減少告警發送的數量,提升告警準確性,最終提升解決問題的效率,降低問題恢復時長。下面我們從系統和功能層面說明如何降低告警量,把真正有價值的告警資訊發送到使用者手中。本文也將重點圍繞告警訊息收斂進行講解。
從圖1中可以看出各個監控系統中都有很多重復的功能模組,所以針對這些功能模組我們可以將其抽離出來,如圖7所示將告警收斂、告警遮蔽、告警升級等能力統一建設在統一告警服務中。這種架構下統一告警服務與檢測相關服務完全解耦,在能力上具有一定的通用性。例如其它有告警或訊息收斂需求的業務團隊想接入統一告警,統一告警要能滿足訊息收斂發送的需求,同時也要滿足訊息直接發送的需求。統一告警會提供靈活可配置的訊息發送方式,提供簡單、多樣的功能滿足各類需求。
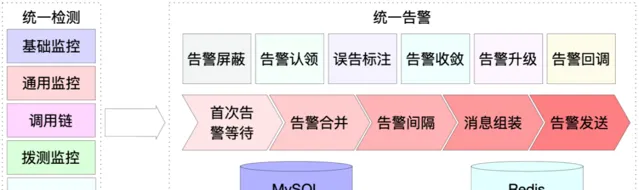
(圖7 統一告警系統結構圖)
4.1 告警收斂
對於告警平台每天會產生數以萬計的告警,這些告警對於運維或開發人員都需要去分析、甄別優先級、並處理故障。數以萬計的告警如果不加收斂每條異常都發送告警,勢必會增大運維人員的工作壓力,當然也不是所有的告警都需要並且有必要發送給運維人員進行處理。所以我們需要對告警透過多種手段進行收斂,下面我們從四個方面介紹一下如何進行告警收斂。
首次告警等待
當一個異常產生之後我們不會立即去做告警,而是透過等待一段時間才會去做告警發送,一般這個時間可以透過系統自訂,這個值如果太大就會影響告警延遲,太小不能提升告警合並效果。例如首次告警等待時間為5s,當一個服務下節點1出現A指標異常,5s內節點2也出現了A指標異常,那麽發送告警時節點1和節點2會被合並到一起發送告警通知。
告警間隔
問題在沒有恢復前,系統會根據告警間隔的配置每隔一段時間發送一條告警資訊,告警間隔用來控制告警發送的頻率。
異常收斂維度
異常收斂維度用來將同個維度下的異常合並在一起。例如同個節點路徑A下,透過同一個檢測規則產生的異常,會在告警發送的時候根據配置的異常收斂維度合並在一起。
訊息合並維度
當多個異常收斂成一個問題,在發送告警的時候會涉及到訊息合並,訊息合並維度就是用來指定哪些維度可以合並。可能這樣理解有些晦澀,我們可以透過圖8看一下從異常到訊息的轉換過程。
假如一個異常有兩個維度名字和性別,當這兩個異常經過統一告警,我們會根據配置的收斂策略進行合並,從圖中我們可以看到性別被定義為異常收斂維度,通常異常收斂維度的選擇一定是兩個或兩個以上具有相同的內容的異常,這樣在訊息合並後只取相同內容的同一個值,對應到範例圖,我們會將${sex}占位符替換成男。而名字是被定義為告警合並維度,就表示所有異常中名字是都要展示在訊息文本中,所以在訊息合並的時候我們會將${name}占位符對應的資訊一一拼接在訊息文本中。
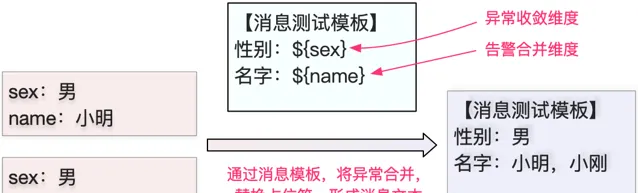
(圖8 訊息文本替換示意圖 )
4.2 告警認領
當出現告警後如果有人認領了該告警,那麽後續相同告警只會發送給告警認領人。告警認領主要是為了解決告警有人跟進後,減少將告警發給其他人員,也能從一定程度上解決告警被重復處理的問題。被認領的告警可以取消認領。
4.3 告警遮蔽
對於同一個問題,可以設定告警遮蔽,後續如果有該問題對應的告警產生,那麽將不會被發送出去。告警遮蔽能減少故障在定位解決過程中,或者服務在發版變更過程中造成的告警,能有效減少無效告警對運維人員造成的困擾,遮蔽可以設定為周期性的,也可以設定為遮蔽某一時段,當然也可以取消遮蔽。
4.4 告警回呼
當告警規則配置了回呼,那麽當產生告警,就會呼叫回呼介面,使服務或業務恢復正常。告警回呼的目的是當某個服務有告警產生,希望系統能夠透過一些自動化的配置,使服務恢復到正常狀態,縮短故障恢復的時間,也能夠緊急情況下第一時間快速恢復服務。
4.5 誤告標註
對於一個問題,使用者可以透過誤告標註備註該異常是否為誤告警。誤告標註的主要目的是透過標註讓系統開發人員知道異常檢測過程中,哪些點還需要提升最佳化,提高告警的準確性,為使用者提供真實有效的告警提供保障。
4.6 告警升級
當告警發生一定時間仍沒有恢復,那麽系統就會根據配置自動進行告警升級處理,然後將告警升級資訊透過配置發送給對應的人員。告警升級一定程度上是為了縮短MTTA,當告警長時間未恢復,可以認為故障沒有及時得到響應,這時就需要更高級別的人員介入處理。
如圖9所示,每天告警系統會發送大量的告警,當然這些告警會分別發送給不同服務的告警接收人。告警並不是越多越好,而是應該第一時間準確反映出服務的異常情況,所以如何提升有效告警,提高告警準確性,減少告警量至關重要。透過以上系統設計和功能設計能夠有效減少重復告警發送。
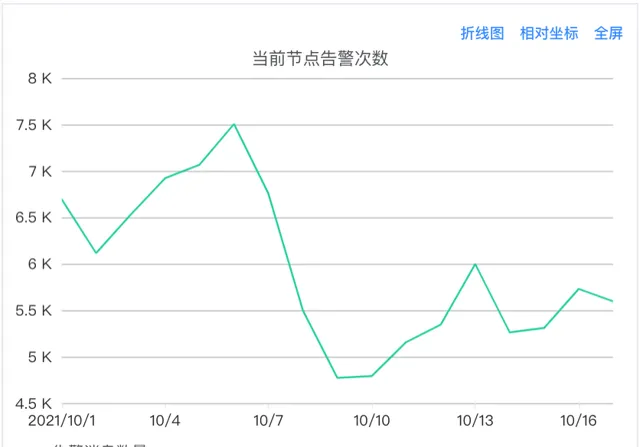
(圖9 主機監控告警次數圖)
五、架構設計
上面我們從系統和功能層名講解了如何針對老架構下存在的各種問題進行解決,那麽對於這個構想我們應該用一套什麽架構來實作。
下面我們看下如何設計這套架構。統一告警作為整個監控最後一環,既要滿足告警發送能力也要滿足業務服務發送通知的需求,所以統一告警的各種能力要具有通用性。統一告警服務要做到與其它服務低耦合,尤其是與已有監控系統做到解偶,這樣才能真正把通用能力釋放出來。服務要能做到根據業務場景的不同適配不同的業務邏輯,比如有的業務需要做告警收斂,有的業務不需要,那麽服務要提供靈活的接入方式以適用業務需要。
如圖10所示,統一告警核心邏輯由收斂服務實作,收斂服務可以消費kafka中的異常,也可以透過RestFul介面接收推播過來的異常,異常會先經過例外處理生成一個問題,然後將問題和異常存入MySql庫,經過告警收斂模組問題會被推播到Redis延時佇列中,延時佇列會用來控制訊息出隊時間,訊息從佇列取出之後會進行文本組裝等操作,最後會透過配置發送出去。
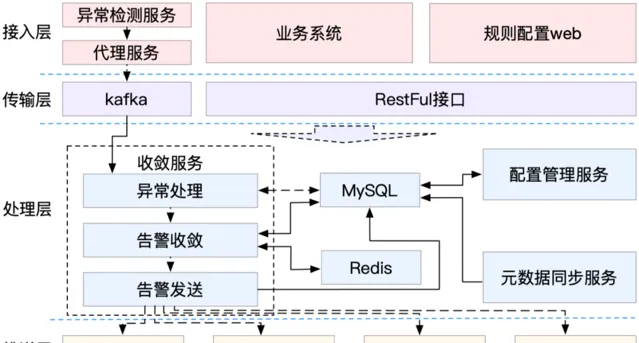
(圖10 統一告警架構圖)
配置管理服務用來管理套用、事件、告警等配置資訊,後設資料同步服務用來從其它服務同步告警收斂所需的後設資料。
六、核心實作
統一告警的核心是告警收斂,收斂的目的就是減少發送重復的告警訊息,避免因為大量的告警對於告警接收人造成告警麻痹。
前文已經說到使用延時佇列做告警收斂,延時佇列在電商和支付計畫中使用較多,比如商品下單後10分鐘未支付就要自動取消訂單。在告警系統中使用延時佇列主要目的是,在一定的時間內盡可能多的將同一個問題對應的異常合並在一起,減少告警發送的數量。舉個例,如果一個服務A有三個節點,當發生異常時,一般情況下每個節點的異常都會生成一條告警發送出去,但是經過告警收斂時候我們可以將三個節點的告警合並,由一條告警做通知。
延時佇列有很多種方式實作,這裏我們選擇了Redis實作延時佇列,選用 Redis 延時佇列主要的原因就是其支持高效能的 score 排序,同時 Redis 的持久化特性,保證了訊息的消費和存貯問題。
如圖11所示,一個問題透過一系列校驗去重之後放入redis延時佇列,佇列中到期時間最小的問題會被排到最前面,同時有一個監聽任務不斷檢視佇列中是否有過期的任務,如果有過期的任務會被取出,取出的訊息會經過訊息組裝等操作最終形成一條訊息文本,然後根據配置透過不同的通道發送出去。
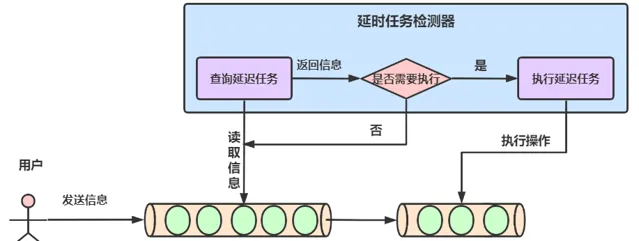
(圖11 延時任務執行原理圖[6])
七、未來展望
基於統一告警服務定位來看,告警服務要能簡單、高效、準確的告訴運維或者開發人員,哪裏有故障需要去處理。所以對於後續服務的建設,應該考慮如何進一步減少人為的配置,增強告警智慧化收斂的能力,同時還要增強根因定位的能力,以上透過AI的加持能夠很好的解決此類問題。目前各大廠商都在向著AIOps探索前進,並且已經有一些產品投入使用,但是AIOps何時大規模落地,就目前來看還需要一段時間。相較於AI的使用,當前最緊迫的就是讓統一告警串聯起上下遊服務,從而打通數據,為數據流轉鋪平道路,增強服務的自動化程度,並且支持從更高維度實作告警發送,為故障的發現和解決提供更準確的資訊。
八、參考資料
[1]What are MTTR, MTBF, MTTF, and MTTA? A guide to Incident Management metrics
[2]平均修復時間[Z].
[3]運維不容錯過的4個關鍵指標!
[4]PIGOSS TOC 智慧服務中心讓告警管理更智慧
[5]大規模智慧告警收斂與告警根因技術實踐[EB/OL].
[6]你知道Redis可以實作延遲佇列嗎?
如喜歡本文,請點選右上角,把文章分享到朋友圈
如有想了解學習的技術點,請留言給若飛安排分享
因公眾號更改推播規則,請點「在看」並加「星標」 第一時間獲取精彩技術分享
·END·
相關閱讀:
作者:Chen Ningning
來源:vivo互聯網技術
版權申明:內容來源網路,僅供學習研究,版權歸原創者所有。如有侵權煩請告知,我們會立即刪除並表示歉意。謝謝!
架構師
我們都是架構師!

關註 架構師(JiaGouX),添加「星標」
獲取每天技術幹貨,一起成為牛逼架構師
技術群請 加若飛: 1321113940 進架構師群
投稿、合作、版權等信箱: [email protected]











