點選上方 「 Linux開源社群 」,選擇「 設為星標 」
優質文章,及時送達
☞【幹貨】
☞【幹貨】
☞【幹貨】
☞【幹貨】
執行時指的是程式的生命周期階段或使用特定語言來執行程式 。容器執行時的功能與它類似——它是執行和管理容器所需元件的軟體。這些工具可以更輕松地安全執行和高效部署容器,是容器管理的關鍵組成部份。在容器化架構中, 容器執行時負責從儲存庫載入容器映像、監控本地系統資源、隔離系統資源以供容器使用以及管理容器生命周期。
容器執行時的常見範例是 runC、containerd 和 Docker。容器執行時主要分為三種型別——低階執行時、高級執行時以及沙盒或虛擬化執行時。
在容器技術中,容器執行時可以分為三種型別:低階執行時、高級執行時以及沙盒或虛擬化執行時。
1. 低階執行時 :指的是 負責容器隔離和生命周期管理的基本執行時元件 。在這種執行時中,容器是透過Linux內核的cgroups和namespace機制進行隔離和管理的。常見的低階執行時包括Docker的runc、lxc等。這種執行時通常具有輕量化和高效能的優點,但缺乏高級特性和管理工具。
2. 高級執行時 :是在低階執行時的基礎上,提供了 更豐富的特性和管理工具的容器執行時。這些特性可以包括容器網路、儲存、監控、映像傳輸、映像管理、映像API等功能,以及各種管理工具等 。常見的高級執行時包括Docker、Containerd和CRI-O等。這種執行時通常具有更為豐富的特性和管理工具,但也帶來了更高的復雜性和資源消耗。
3. 沙盒或虛擬化執行時 :是在 容器執行時中使用沙盒技術或虛擬化技術實作容器隔離和管理的執行 時。這種執行時通常具有更強的隔離性和安全性,但也會帶來更高的效能開銷和復雜性。常見的沙盒或虛擬化執行時包括gVisor、 Kata Containers 等。
總的來說,容器執行時的不同型別具有各自的優缺點和適用場景。在選擇容器執行時時,需要根據實際需求和限制進行權衡和選擇。
低階容器執行時
低階容器執行時 (Low level Container Runtime),一般指 按照 OCI 規範實作的、能夠接收可執行檔案系統(rootfs) 和 配置檔(config.json)並執行隔離行程 的實作。
這種執行時 只負責將行程執行在相對隔離的資源空間裏,不提供儲存實作和網路實作 。但是其他實作可以在系統中預設好相關資源,低階容器執行時可透過 config.json 聲明載入對應資源。
低階執行時的特點是底層、輕量、靈活,限制也很明顯:
• 只認識 rootfs 和 config.json,不認識映像 (下文簡稱 image),不具備映像儲存功能,也不能執行映像的構建、推播、拉取等(我們無法使用 runC, kata-runtime 處理映像)
• 不提供網路實作 ,所以真正使用時,往往需要利用 CNI 之類的實作為容器添加網路
• 不提供持久實作 ,如果容器是有狀態套用需要使用檔案系統持久狀態,單機環境可以掛載宿主機目錄,分布式環境可以自搭 NFS,但多數會選擇雲平台提供的 CSI 儲存實作
• 與特定作業系統繫結無法跨平台 ,比如 runC 只能在 Linux 上使用;runhcs 只能在 Windows 上使用
解決了這些限制中一項或者多項的容器執行時,就叫做高級容器執行時 (High level Container Runtime)。
高級容器執行時第一要務
高級容器執行時首先要做的是打通 OCI image spec 和 runtime spec,直白來說就是高效處理 image 到 rootfs 和 config.json 的轉換 。config.json 的生成比較簡單,執行時可以結合 image config 和請求方需求直接生成;較為復雜的部份是 image 到 rootfs 的轉換,這涉及映像拉取、映像儲存、映像 layer 解壓、解壓 layer 檔案系統(fs layer) 的儲存、合並 fs layer 為 rootfs。
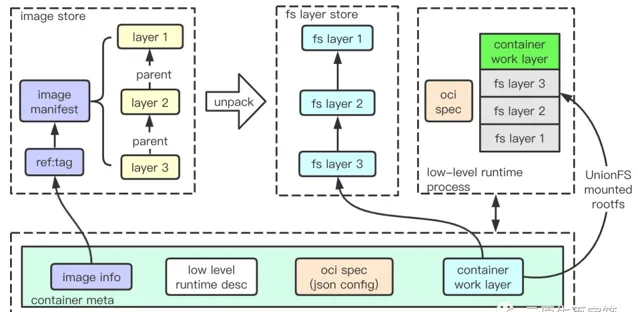
映像拉取模組先從 image registry 獲取清單(manifest)檔,處理過程不僅需要相容 OCI image 規範,考慮到 Docker 生態,也需相容 Docker image 規範(所幸兩者區別並不大)。 執行時實作先從 manifest 獲取 layer list,先檢查對應 layer 在本地是否存在,如果不存在則下載對應 layer 。下載的 layer tar 或者 tar.gz 一般直接儲存磁盤,為實作快速處理,需要建立索引,比如從 reference:tag (如 docker.io/library/redis:6.0.5-alpine) 到 manifest 儲存路徑的對映;當然,layer 的存取比 image 高頻,layer sha256 值到對應儲存路徑也會被索引。因此 ,執行時一般會圍繞 image 索引和 image layer 儲存組織獨立模組對其他模組提供服務。
如果 要轉換 image layers 到 rootfs,就要逐層解壓 layers 為 filesystem layer(fs layer) 再做合並 。這帶來了幾個問題,首先是 fs layer 同樣需要儲存磁盤多次復用,那麽就需要有一個方式從 image 對映到對應 fs layers;接著類似 image layer,需要建立索引維系 fs layers 之間的父子關系,盡可能復用裏層檔,避免重復工作;最後是層次復用帶來的煩惱,隔離行程執行之後會發生 rootfs 寫入,需要以某種方式避免更改發生到共享的 fs layers。
• 第一個問題一般 使用 image config 檔中的 diffID 解決 ,每解壓一層 layer,就使用上一層 fs layer id 和 本層 diffID 的拼接串做 sha256 hash,輸出結果作為本層對應的 fs layer id(最裏層 id 為其 diffID),接著建立 id 到磁盤路徑索引。因此只要透過 image manifest 檔找到 image config 檔,即可找到所有 fs layers,詳細實作方式見 OCI image spec layer chain id 。
• 第二個問題解決方式很簡單,在 每個 fs layer 索引儲存上一層 fs layer id 即可 。
• 第三個問題,一般 透過 UnionFS 提供的 CopyOnWrite 技術解決 ,簡單來說,就是使用空資料夾,在映像對應 fs layer 最外層之上再生成一層 layer,使用 UnionFS 合並(準確來說是掛載 mount)時將其聲明為 work 目錄(或者說 upper 目錄)。UnionFS 掛載出 rootfs 之後,隔離行程所做的任何寫操作(包括刪除)都只體現在 work layer,而不會影響其他 fs layer。(詳細介紹可以參考 陳皓的介紹文章 )
最後,高級執行時需要充當隔離行程管理者角色,而一個低階執行時(如 runC )可能同時被多個高級執行時使用。同時試想,如果隔離行程結束,如何以最快的方式恢復執行? 高級執行時實作一般都會引入 container 抽象(或者說 container meta),meta 儲存了 ID、 image 資訊、低階執行時描述、OCI spec (json config)、 work layer id 以及 K-V 結構的 label 資訊。 因此只要建立出 container meta,後續所有與隔離行程相關操作,如行程執行、行程資訊獲取、行程 attach、行程日誌獲取,均可透過 container ID 進行。
containerd
containerd 是一個高度模組化的高級執行時,所有模組均以 RPC service 形式載入(gRPC 或者 TTRPC) ,所有模組均可插拔。不同外掛程式透過聲明互相依賴,由 containerd 核心實作統一載入,使用方可以使用 Go 語言實作編寫外掛程式實作更豐富的功能。不過這種設計使得 containerd 擁有強大的跨平台能力,並能夠作為一個元件輕松嵌入其他軟體,也帶來一個弊端,模組之間功能互調也從簡單的函式呼叫,變成了更為昂貴的 RPC 呼叫。
註: TTRPC 是一種基於 gRPC 的改良通訊協定。
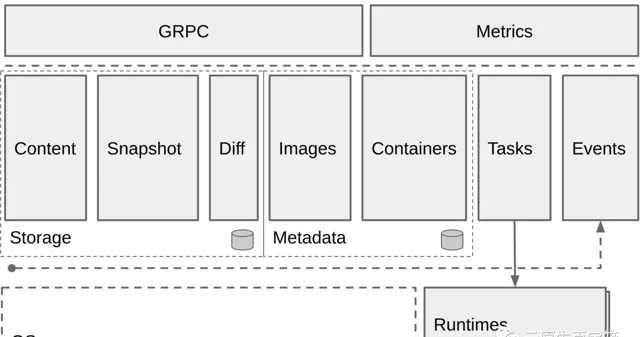
containerd 大多功能模組很容易與上文提到的「第一要務」相聯系 :
• Content ,以 image layer 哈希值(一般使用 sha256 演算法生成)為索引,支持快速 layer 快速尋找和讀取,並支持對 layer 添加 label。索引和 label 資訊儲存在 boltDB。
• Images ,在 boltDB 中儲存了 reference 到 manifest layer 的對映,結合 Content 可以組織完整的 image 資訊。
• Snapshot ,儲存、處理解壓後的 fs layers 和容器 work layer,索引資訊同樣儲存在 boltDB。Snapshot 內建支持多種 UnionFS(如 overlay,aufs,btrfs)。
• Containers ,以 container ID 為索引,在 boltDB 中儲存了低階執行時描述、 snapshot 檔案系統型別、 snapshotKey(work layer id)、image reference 等資訊。
• Diff ,可用於比對 image layer tar 和 fs layers 差異輸出 diffID,可以校驗 image config 中的 diffID,同樣也能比對 fs layers 之間的差異。
基於以上模組, containerd 提供了 namespace 隔離,實作上是在各模組的內容放置於不同目錄樹,達到資源隔離效果。比如,它可以一邊服務於 Docker,一邊服務 k8s kubelet,做到兩不沖突。
還有重要模組是 Tasks (runtime.PlatformRuntime),它負責容器行程管理和與低階執行時打交道,對上統一了容器行程執行介面。v1 版 Tasks 只支持 Linux,1.2.0 (2018/11) 後 containerd 正式支持 Windows,新引入的 v2 版 Tasks 核心邏輯使用平台無關程式碼實作,因此可以在 Go 語言支持的大部份平台執行(包括 macOS darwin/amd64)。
containerd 執行容器,一般先從 Images 模組觸發,結合 Snapshot 模組建立新的容器 fs layer,加上低階執行時資訊,組合成 container 結構體 。containerd 利用 container 結構體,將之前的所有 Snapshots 轉換為 Mounts 物件(聲明了所有子資料夾的位置和掛載方式),結合低階執行時、OCI spec、映像等資訊在請求體中,向 Tasks 模組送出任務請求。Tasks 模組 Manager 根據任務低階執行時資訊(如 io.containerd.runc.v1),組合出統一的 containerd-shim 行程執行命令,透過系統呼叫啟動 shim 行程,並同步建立與 shim 行程的 TTRPC 通訊。隨後將任務交給 shim 行程管理。shim 行程接到請求後,判知 Mounts 長度大於 0,則會按照 Mounts 聲明的掛載方式,使用 overlay、aufs 等聯合檔案系統將所有子資料夾組成容器執行需要的 rootfs,結合 OCI spec 呼叫低階執行時執行容器行程並將結果返回給 containerd 行程。
使用 shim 行程管理容器行程好處很多 ,containerd clash,containerd-shim 行程和容器行程不會受影響,containerd 恢復後只需讀取執行目錄的 socket 檔及 pid 恢復與 shim 行程通訊即可快速還原 Tasks 資訊(Unix 平台),同一容器行程出現問題,對於其他行程來說是隔離。最重要的是, 透過統一的 shim 介面,同一套 containerd 程式碼可以同時相容多個不同的執行時,也能同時相容不同作業系統平台 。
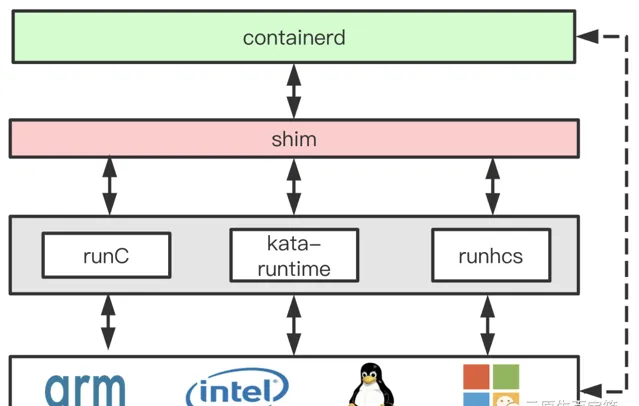
containerd 不提供容器網路和容器套用狀態儲存解決方案,而是把它們留給了更高層的實作。
container 在其 介紹 中提到:其設計目的是成為大系統中的一個元件(如 Kubernetes, Docker),而非直接供使用者使用。
containerd is designed to be embedded into a larger system, rather than being used directly by developers or end-users。
下文會展示這意味著什麽。
CRI-O
相比 containerd,CRI-O 的高級執行時功能基於若幹開源庫實作,不同模組之間為純粹 Go 語言依賴,而非通訊協定 :
• containers/image 庫用於 Image 下載,下載過程類似 2 階段送出。不同來源的映像(如 Docker, Openshift, OCI)先被統一為 ImageSource 通用抽象,接著被分為 3 部份進行處理:blob 被放置在系統臨時資料夾,manifest 和 signature 緩存在記憶體(Put*)。之後,映像內容 Commit 至 containers/storage 庫。
• CRI-O 大部份業務邏輯集中在 containers/storage 之上
• LayerStore 介面統一處理 image layer(不包括 config layer) 和 fs layer ,映像 Commit 儲存時,LayerStore 先呼叫 fs 驅動實作(如 overlay)在磁盤建立 fs layer 目錄並記錄層次關系,接著呼叫 ApplyDiff 方法,解壓內容被存放在 layer 目錄(經驅動實作),未解壓內容被存放在 image layer 目錄,fs layer 層次關系儲存在 json 檔。
• ImageStore 介面處理 image meta ,包括 manifest、config 和 signature,meta 與 layer 關聯索引儲存在 json 檔。
• ContainerStore 介面管理 container meta ,建立 container 的步驟和儲存 image layer 程式碼路徑近乎重合,只不過前者被限制為 read 模式,後者為 readWrite,且沒有 ApplyDiff(diff 送空),meta 與 layer 關聯索引也儲存在 json 檔。
containers/storage 庫 container meta 沒有 namespace 概念,但提供一個 metadata 欄位(string 型別)可以儲存任意內容,CRI-O 便是將包括 namespace 在內的業務資訊序列化為 json string 儲存其中。微信搜尋公眾號:架構師指南,回復:架構師 領取資料 。
CRI-O 執行容器行程時,先確保對應 image 存在(不存在則嘗試下載),隨之基於 image top layer 建立 UnionFS,同時生成 OCI spec config.json,之後,根據請求方提供的低階執行時資訊(RuntimeHandler),使用不同包裝實作操作容器行程。
• 如果 RuntimeHandler 為非 VM 型別,建立並委托監視行程 conmon 操作低階執行時建立容器 。之後,conmon 在特定路徑提供一個可與容器行程通訊的 socket 檔,並負責持續監視容器行程並負責將其 stream 寫入指定日誌檔。容器行程建立成功之後,CRI-O 直接與低階執行時互動執行 start、delete、update 等操作,或者透過 socket 檔直接與容器行程互動。
• 如果 RuntimeHandler 為 VM,則建立並委托 containerd-shim 行程處理間接容器行程(請求包含完整 rootfs,Mounts 為 空)。與非 VM 型別不同,此後所有容器行程相關操作均透過 shim 完成。
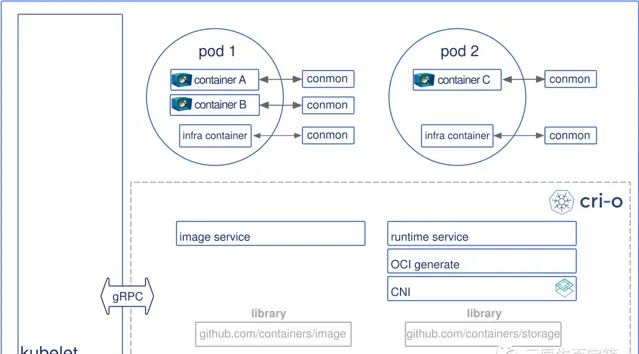
CRI-O 依靠 CNI 外掛程式(預設路徑 /opt/cni/bin)為容器行程提供網路實作 。其邏輯一般在低階執行時建立完隔離行程返回後,獲取 pid 後將對應的 network namespace path(/proc/{pid}/ns/net)交給 CNI 處理,CNI 會根據配置會往對應 namespace 添加好網卡。一般地,容器行程會在 cni 網橋 上獲得一個獨立 IP 地址,這個 IP 地址能與宿主機通訊,如果 CNI 配置了 flannel 之類的 overlay 實作,容器甚至能夠與其他主機的同一網段容器行程通訊,具體視配置而定。細節方面可以參考 這篇介紹 。
如果指定由其管理 network namespace 生命周期(配置 manage_ns_lifecycle),則會在建立 sandbox 容器時采用類似 理解 OCI#給 runC 容器繫結虛擬網卡 的方式建立虛擬網卡,隨後透過 OCI json config 傳遞對應路徑給低階執行時。同樣地,當 sandbox 容器銷毀時,CRI-O 會自動回收對應 namespace 資源。這部份邏輯的網路相關程式碼使用 C 語言實作,在 CRI-O 中以名為 pinns 的二進制程式發行。
需要指出的是, CRI-O 使用檔掛載方式配置容器 hostname, dns server 等,而非 CNI 外掛程式 。
Docker
Docker 是一個大而完備的高級執行時,其使用者端核心叫做 Docker Engine ,由 3 部份構成:Docker Server (docker daemon, 簡稱 dockerd)、REST API 和 Docker cli。借助 Docker Engine 既能便捷地執行容器行程進行整合開發、也能快速構建分發映像。
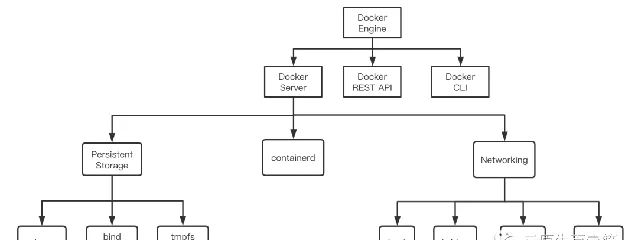
如上圖所示, Docker Engine 的核心是 dockerd,既驅動映像的構建分發,也為容器執行提供成熟的持久實作和網路實作。Docker cli 使用 REST API 與 dockerd 互動 。
與上文其他執行時不同,dockerd 以 image config 為核心,使用 config layer 的 sha256 hash 值索引 image 抽象,而不是 manifest。實際上,dockerd 根本不儲存 manifest。dockerd 也不儲存 image layers(tar, tar.gz 等),而只儲存解壓後的 layer fs 和一些必要的索引。
• 映像下載時,dockerd 先自 registry 獲取 manifest 檔,隨後並列下載儲存 image layers 和 config layer。與 containers/storag 類似,image layer 解壓內容由 fs 驅動實作(如 overlay) 儲存至新建的子目錄中(如 /var/lib/docker/overlay2/{new-dir}),不同的是,隨後 dockerd 只是以 layer chainID 為索引,儲存 fs new-dir、diffID、parent chainID、size 等必要資訊,並不儲存未解壓 tar 或 tar.gz。image layers 和 config layer 均儲存完成後,再以 image reference 為索引,建立 reference 至 image ID 對映。作為映像分發模組的一部份,dockerd 還會以 manifest layer digest 為索引,建立 digest 至 diffID 對映;以 diffID 為索引,建立 diffID 至 repository 和 digest 對映。
• 映像推播不過是映像下載的逆過程。dockerd 先使用 reference 獲取 imageID(也即 image config),隨後以 imageID 為中心組織出目標 manifest,對應的 layer fs 開始被壓縮成目標格式(一般是 tar.gz)。layers 開始上傳時,自分發模組獲取 diffID 至 repository 和 digest 資訊,發起遠端請求確認對應 layer 是否已存在,存在則跳過上傳,最終以 manifest 為中心的映像被分發至對應 Registry 實作。
Docker Engine 配套了成熟的映像構建技術,它使得開發者只需提供一個目錄、一份
Dockerfile
,外加一行
docker build
命令即可構建映像。簡單來看,映像構建過程即是把套用依賴的檔案系統和執行環境轉化為 image layers 和 config 的過程,構建結果是能夠索引到構建結果的 reference,即我們熟悉的 tag。但簡單的介面後面隱藏著非常多的考量,比如怎樣提高映像構建速度,比如怎樣檢查構建期錯誤。我們已經知道一份映像包含多份 layers,基於什麽映像構建新映像就會在之前的 layers 上構建新 layers。實際上,dockerd 會將 Dockerfile 中的每一行命令轉化為一個構建子步驟,每執行一步,都可能產生中間映像和中間容器。
COPY
,
ADD
等檔傳輸命令一般直接產生中間映像,
RUN
、
ENV
、
EXPOSE
等執行命令會產生中間容器。每成功一步,該步驟產生的中間映像或者 config 就會成為下一步的基礎,產生的中間容器隨之被移除,產生的中間映像會被保存供後續復用。構建結束時,最後一步產生的映像會被關聯到 tag(如果指定了)。dockerd 維護了映像構建過程產生的 parent-child 關系,使用
docker image ls
命令羅列映像時,沒有 tag 且存在 child 的映像會被過濾,如此便過濾了中間映像。此外,docker cli 會將中間結果輸出到控制台,這樣如果構建出錯,使用者可以利用間映像和中間容器排查問題。
Docker 容器建立執行相較 containerd 和 CRI-O 有更多高層的儲存和網路抽象,如使用
-v,--volume
命令即可聲明執行時需掛載的檔案系統,使用
-p,--publish
即可聲明 host 網路至容器網路對映,這些聲明資訊會被持久在 docker 工作目錄下的 containers 子目錄。
執行執行命令之際,dockerd 首先生成容器讀寫層並透過 UnionFS 與 fs layers 一道轉化為 rootfs。接著,image config 中的環境、啟動參數等資訊被轉化為 OCI runtime spec 參數。同時類似 CRI-O,dockerd 會為容器生成一些特殊的檔,如 /etc/hosts, /etc/hostname, /etc/resolv.conf, /dev/shim 等,隨之這些特殊檔與 volume 聲明或者 mount 聲明一起作為 dockerd Mount 抽象轉化為 OCI runtime spec Mount 參數。最後,rootfs、OCI runtime spec 和低階執行時資訊透過 RPC 請求傳遞給 containerd,劇情變得和 containerd 執行容器一致。
不難發現,雖然持久掛載驅動各異,但對執行時而言,本質都是將宿主機某型別的檔目錄對映到容器檔案系統中。因此對於低階執行時而言,掛載邏輯可以統一。dockerd 在此之上發展了豐富的持久業務層,以便於使用者使用。mount 用於直接將宿主機目錄掛載至容器檔案系統;volume 相對 bind mounts 優勢是對應檔持久在 dockerd 的工作目錄,由 dockerd 管理,同時具有跨平台能力。tmpfs 則由作業系統提供容器讀寫層之外的臨時儲存能力。
dockerd 支持多種網路驅動,其基礎抽象叫做 endpoint,可以簡單將 endpoint 理解為網卡背後的網路資源。對於每一 endpoint,dockerd 都會透過 IPAM 實作在 docker0 網橋上分配 IP 地址,接著透過 bridge 等驅動為容器建立網卡,如果使用
publish
參數配置了容器至宿主機的 port 對映,dockerd 會往宿主機 iptable 添加對應網路規則,同時還可能會啟動 docker proxy 服務 forward 流量到容器。容器的所有 endpoints 被放置在 sandbox 抽象中。準備好網路資源後,dockerd 呼叫 containerd 執行容器時,會在 OCI spec 中設定 Prestart Hook 命令,該命令包含了設定網路的必要資訊(容器ID,容器行程ID,sandbox ID)。低階執行時實作如 runC 會在容器行程被建立但未被執行前呼叫該命令,該命令最終將容器ID,容器行程ID,sandbox ID 傳遞給 dockerd,dockerd 隨即將 sandbox 中的所有 endpoint 資源繫結到容器網路 namespace 中(也是 /proc/{ctr-pid}/ns/net)。
總結
上文簡述了 containerd, CRI-O 和 Docker 執行時的基本原理和其基於低階執行時提供的高級功能。Docker 作為提供功能最多最高層實作,放在最後是方便漸進式理解容器技術構成。
實際上, 目前容器生態的技術和 OCI 標準,大都源自 Docker。Docker 抽離其容器管理邏輯發展出了 containerd 計畫,並隨後使用它作為自己的低層執行時。
libnetwork 庫 賦能了 docker (19.03) 網路實作,也演化自 Docker。
上文提到,Docker 映像構建過程會產生中間映像和中間容器,這類中間產物提升了構建速度,但是也帶來了使用負擔(看著莫名其妙,清理費勁)。同時,很多公司有持續、大規模構建映像的需求,他們往往希望負責構建映像系統能夠以 HTTP 或者 gRPC 的方式對其他系統暴露服務,而 dockerd 在設計上只是一個本地服務。因此在 2017 後,dockerd 中的構建功能逐步發展成了 buildkit 計畫 ,對應考量見 docker issuse 32925 。 Docker 在 18.06 版本後開始支持 buildkit,使用此種方式構建映像有著相近的效能且不會產生中間映像和中間容器。
從 Docker 業務層越變越薄的情況可以看出,隨著社群對 OCI 規範的靠攏,容器技術模組朝著越來越精細化的方向發展,同時模組的復用程度變得越來越強。如果某家公司想要加強容器的隔離能力,只需關心如何結合作業系統技術實作低階執行並基於 containerd 提供 shim 實作即可迅速將自家技術整合進 Docker 或者 Kubernetes,這樣就沒有必要把高級執行時提供的能力再實作一遍。這種類比可以推廣到網路、儲存、映像分發等方面。
CRI-O 計畫初衷是嫌棄 Docker 功能太多,打算做一個 Kubernetes 專用執行時,不需要映像構建、不需要映像推播、不需要復雜的網路和儲存。但它的業務層同樣很薄,程式碼多復用社群的 containers/storage 庫和 containers/image 庫,同時會利用 containerd-shim 執行 vm container。執行 Linux container 情況下,純 C 的 conmon 守護行程實作相較 Go 實作的 containerd-shim 有更少的記憶體消耗。
另外兩個執行時 PouchContainer 和 frakti 社群的日趨死寂在另一面反映了這種演進趨勢。PouchContainer 最近一次釋出還在 2019 年 1 月,frakti 是 2018 年 11 月。隨著 containerd 跨平台能力的加強和其對 Kubernetes 的直接支持(2018/11 1.2.0 引入 shim-v2、CRI 外掛程式),很多低階執行時,如 gvisor、kata-runtime,更趨向於直接提供 containerd-shim 實作以整合進容器生態,而不是再造一邊輪子。PouchContainer 試圖打造一個映像分發速度更快(利用 P2P),強隔離(利用 vm container、lxcfs 等),隨著 containerd 和 Docker 的演進,這些 feature 優勢變得越來越小,開源社群對 PouchContainer 的興趣越來越弱實屬當然。frakti 目的是打造一個支持 runV(kata-runtime 前身)的 Kubernetes 執行時,隨著 runV 和 Clear Containers 合而為 kata-containers 計畫,而後者可利用 containerd-shim 直接整合進生態,frakti 便變得越來越無意義。
參考
• 理解 OCI
• containerd , containerd-CRI
• CRI-O
• Docker , Docker Networking overview , Docker Storage overview , buildkit , libnetwork
本文轉載自:「陳少文的部落格」,原文:https://tinyurl.com/y2sbcrau,版權歸原作者所有。
-End-
讀到這裏說明你喜歡本公眾號的文章,歡迎 置頂(標星)本公眾號 Linux技術迷,這樣就可以第一時間獲取推播了~
在本公眾號,後台回復:Linux,領取2T學習資料 !
推薦閱讀
1.
2.
3.
4.