Python中有非常多用於網路數據采集的庫,功能非常強大,有的用於抓取網頁,有的用於解析網頁,這裏介紹6個最常用的庫。
1. BeautifulSoup
BeautifulSoup是最常用的Python網頁解析庫之一,可將 HTML 和 XML 文件解析為樹形結構,能更方便地辨識和提取數據。
BeautifulSoup可以自動將輸入文件轉換為 Unicode,將輸出文件轉換為 UTF-8。此外,你還可以設定 BeautifulSoup 掃描整個解析頁面,辨識所有重復的數據(例如,尋找文件中的所有連結),只需幾行程式碼就能自動檢測特殊字元等編碼。
from bs4 import BeautifulSoup
# 假設這是我們從某個網頁獲取的HTML內容(這裏直接以字串形式給出)
html_content = """
<html>
<head>
<title>範例網頁</title>
</head>
<body>
<h1>歡迎來到BeautifulSoup範例</h1>
<p class="introduction">這是一個關於BeautifulSoup的簡單範例。</p>
<a href="https://www.example.com/about" class="link">關於我們</a>
</body>
</html>
"""
# 使用BeautifulSoup解析HTML內容,這裏預設使用Python的html.parser作為解析器
# 你也可以指定其他解析器,如'lxml'或'html5lib',但需要先安裝它們
soup = BeautifulSoup(html_content, 'html.parser')
# 提取並打印<title>標簽的文本內容
print("網頁標題:", soup.title.string) # 網頁標題: 範例網頁
# 提取並打印<p>標簽的文本內容,這裏使用 class內容來定位
print("介紹內容:", soup.find('p', class_='introduction').string) # 介紹內容: 這是一個關於BeautifulSoup的簡單範例。
# 提取並打印<a>標簽的href內容和文本內容
link = soup.find('a', class_='link')
print("連結地址:", link['href']) # 連結地址: https://www.example.com/about
print("連結文本:", link.string) # 連結文本: 關於我們
# 註意:如果HTML內容中包含多個相同條件的標簽,你可以使用find_all()來獲取它們的一個列表
# 例如,要獲取所有<a>標簽的href內容,可以這樣做:
all_links = [a['href'] for a in soup.find_all('a')]
print("所有連結地址:", all_links) # 假設HTML中有多個<a>標簽,這裏將列出它們的href內容
# 註意:上面的all_links列表在當前的HTML內容中只有一個元素,因為只有一個<a>標簽
2. Scrapy
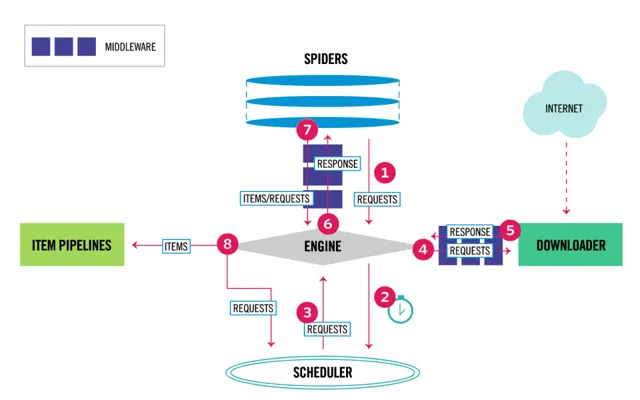
Scrapy是一個流行的高級爬蟲框架,可快速高效地抓取網站並從其頁面中提取結構化數據。
由於 Scrapy 主要用於構建復雜的爬蟲計畫,並且它通常與計畫檔結構一起使用
Scrapy 不僅僅是一個庫,還可以用於各種任務,包括監控、自動測試和資料探勘。這個 Python 庫包含一個內建的選擇器(Selectors)功能,可以快速異步處理請求並從網站中提取數據。
# 假設這個檔名為 my_spider.py,但它實際上應該放在 Scrapy 計畫的 spiders 資料夾中
import scrapy
classMySpider(scrapy.Spider):
# Spider 的名稱,必須是唯一的
name = 'example_spider'
# 允許爬取的網域名稱列表(可選)
# allowed_domains = ['example.com']
# 起始 URL 列表
start_urls = [
'http://example.com/',
]
defparse(self, response):
# 這個方法用於處理每個響應
# 例如,我們可以提取網頁的標題
title = response.css('title::text').get()
if title:
# 打印標題(在控制台輸出)
print(f'Title: {title}')
# 你還可以繼續爬取頁面中的其他連結,這裏只是簡單範例
# 例如,提取所有連結並請求它們
# for href in response.css('a::attr(href)').getall():
# yield scrapy.Request(url=response.urljoin(href), callback=self.parse)
# 註意:上面的程式碼只是一個 Spider 類的定義。
# 要執行這個 Spider,你需要將它放在一個 Scrapy 計畫中,並使用 scrapy crawl 命令來啟動爬蟲。
# 例如,如果你的 Scrapy 計畫名為 myproject,並且你的 Spider 檔名為 my_spider.py,
# 那麽你應該在計畫根目錄下執行以下命令:
# scrapy crawl example_spider
3. Selenium
Selenium 是一款基於瀏覽器地自動化程式庫,可以抓取網頁數據。它能在 JavaScript 渲染的網頁上高效執行,這在其他 Python 庫中並不多見。
在開始使用 Python 處理 Selenium 之前,需要先使用 Selenium Web 驅動程式建立功能測試用例。
Selenium 庫能很好地與任何瀏覽器(如 Firefox、Chrome、IE 等)配合進行測試,比如表單送出、自動登入、數據添加/刪除和警報處理等。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 設定WebDriver的路徑(根據你的系統路徑和WebDriver版本修改)
driver_path = '/path/to/your/chromedriver'
# 初始化WebDriver
driver = webdriver.Chrome(executable_path=driver_path)
try:
# 開啟網頁
driver.get('https://www.example.com')
# 等待頁面載入完成(這裏使用隱式等待,針對所有元素)
# 註意:隱式等待可能會影響效能,通常在指令碼開始時設定一次
driver.implicitly_wait(10) # 秒
# 尋找並輸入文本到搜尋框(假設搜尋框有一個特定的ID或類名等)
# 這裏以ID為'search'的輸入框為例
search_box = driver.find_element(By.ID, 'search')
search_box.send_keys('Selenium WebDriver')
# 送出搜尋(假設搜尋按鈕是一個型別為submit的按鈕或是一個可以點選的輸入框)
# 如果搜尋是透過按Enter鍵觸發的,可以直接在search_box上使用send_keys(Keys.ENTER)
# 這裏假設有一個ID為'submit'的按鈕
submit_button = driver.find_element(By.ID, 'submit')
submit_button.click()
# 等待搜尋結果載入完成(這裏使用顯式等待作為範例)
# 假設搜尋結果頁面有一個特定的元素,我們等待它出現
wait = WebDriverWait(driver, 10) # 等待最多10秒
element = wait.until(EC.presence_of_element_located((By.ID, 'results')))
# 執行其他操作...
finally:
# 關閉瀏覽器
driver.quit()
4. requests
不用多說,requests 是 Python 中一個非常流行的第三方庫,用於發送各種 HTTP 請求。它簡化了 HTTP 請求的發送過程,使得從網頁獲取數據變得非常簡單和直觀。
requests 庫提供了豐富的功能和靈活性,支持多種請求型別(如 GET、POST、PUT、DELETE 等),可以發送帶有參數、頭資訊、檔等的請求,並且能夠處理復雜的響應內容(如 JSON、XML 等)。
import requests
# 目標URL
url = 'https://httpbin.org/get'
# 發送GET請求
response = requests.get(url)
# 檢查請求是否成功
if response.status_code == 200:
# 打印響應內容
print(response.text)
else:
# 打印錯誤資訊
print(f'請求失敗,狀態碼:{response.status_code}')
5. urllib3
urllib3 是 Python內建網頁請求庫,類似於 Python 中的requests庫,主要用於發送HTTP請求和處理HTTP響應。它建立在Python標準庫的urllib模組之上,但提供了更高級別、更健壯的API。
urllib3可以用於處理簡單身份驗證、cookie 和代理等復雜任務。
import urllib3
# 建立一個HTTP連線池
http = urllib3.PoolManager()
# 目標URL
url = 'https://httpbin.org/get'
# 使用連線池發送GET請求
response = http.request('GET', url)
# 檢查響應狀態碼
if response.status == 200:
# 打印響應內容(註意:urllib3預設返回的是bytes型別,這裏我們將其解碼為str)
print(response.data.decode('utf-8'))
else:
# 如果響應狀態碼不是200,則打印錯誤資訊
print(f'請求失敗,狀態碼:{response.status}')
# 註意:urllib3沒有直接的方法來處理JSON響應,但你可以使用json模組來解析
# 如果響應內容是JSON,你可以這樣做:
# import json
# json_response = json.loads(response.data.decode('utf-8'))
# print(json_response)
6. lxml
lxml是一個功能強大且高效的Python庫,主要用於處理XML和HTML文件。它提供了豐富的API,使得開發者可以輕松地讀取、解析、建立和修改XML和HTML文件。

from lxml import etree
# 假設我們有一段HTML或XML內容,這裏以HTML為例
html_content = """
<html>
<head>
<title>範例頁面</title>
</head>
<body>
<h1>歡迎來到我的網站</h1>
<p class="description">這是一個使用lxml解析的範例頁面。</p>
<ul>
<li>計畫1</li>
<li>計畫2</li>
</ul>
</body>
</html>
"""
# 使用lxml的etree模組來解析HTML或XML字串
# 註意:對於HTML內容,我們使用HTMLParser解析器
parser = etree.HTMLParser()
tree = etree.fromstring(html_content, parser=parser)
# 尋找並打印<title>標簽的文本
title = tree.find('.//title').text
print("頁面標題:", title)
# 尋找並打印 class為"description"的<p>標簽的文本
description = tree.find('.//p[@ class="description"]').text
print("頁面描述:", description)
# 尋找所有的<li>標簽,並打印它們的文本
for li in tree.findall('.//li'):
print("列表項:", li.text)
# 註意:lxml也支持XPath運算式來尋找元素,這裏只是簡單展示了find和findall的用法
# XPath提供了更強大的查詢能力
其他爬蟲工具
除了Python庫之外,還有其他爬蟲工具可以使用。
八爪魚爬蟲
八爪魚爬蟲是一款功能強大的桌面端爬蟲軟體,主打視覺化操作,即使是沒有任何編程基礎的使用者也能輕松上手。
官網:https://affiliate.bazhuayu.com/hEvPKU
八爪魚支持多種數據型別采集,包括文本、圖片、表格等,並提供強大的自訂功能,能夠滿足不同使用者需求。此外,八爪魚爬蟲支持將采集到的數據匯出為多種格式,方便後續分析處理。
亮數據爬蟲
亮數據平台提供了強大的數據采集工具,比如Web Scraper IDE、亮數據瀏覽器、SERP API等,能夠自動化地從網站上抓取所需數據,無需分析目標平台的介面,直接使用亮數據提供的方案即可安全穩定地獲取數據。
網站:https://get.brightdata.com/weijun
亮數據瀏覽器支持對多個網頁進行批次數據抓取,適用於需要JavaScript渲染的頁面或需要進行網頁互動的場景。

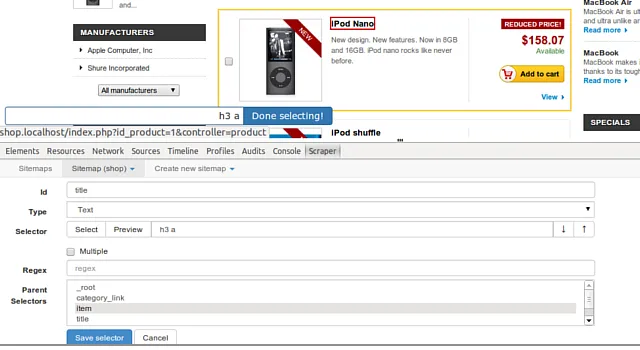
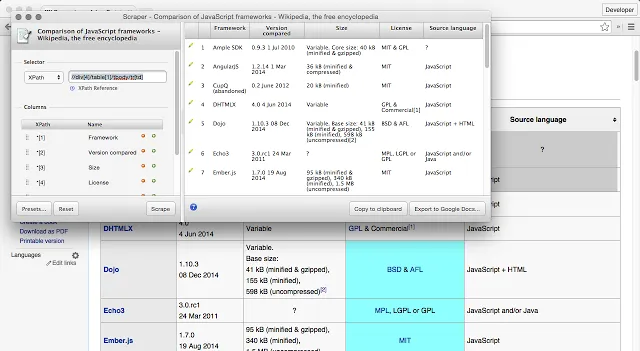
Web Scraper
Web Scraper是一款輕便易用的瀏覽器擴充套件外掛程式,使用者無需安裝額外的軟體,即可在Chrome瀏覽器中進行爬蟲。外掛程式支持多種數據型別采集,並可將采集到的數據匯出為多種格式。
往期文章











