出品丨咖哥 AI
作者|黃佳
AI Agent,最近火得一塌糊塗。
Sam Altman 曾這樣描述未來的AI Agent:「今天的AI模型是它們將會是的最‘笨’狀態,未來只會越來越聰明!」 吳恩達在AI Ascent 2024會議上也不吝贊美:「這是AI發展的黃金時代,生成式AI和AI Agent將徹底改變我們工作的方式!」。這些業界領袖的話讓人感受到未來AI與人類生活、工作的深度融合正在加速到來。
Agent之所以能成為Agent,是因為它具有了判斷的能力,因而能夠做成決策。那麽它的判斷能力是從哪裏得到的,是從海量的人類語言中提煉出來的智慧。因為我們人類的自然語料中指定了場景A中應該這樣做,場景B中應該那樣做。因此大語言模型也就能夠做出判斷。這就是大語言模型成為Agent的基礎。

一個可愛的Agent
不過,願景雖好,現實並不理想。公眾號「產品二姐」的一篇文章就指出——Agent開發者坦白,大家正在窘境中前行。Agent的開發現狀是既沒有什麽有體系的理論指導,有沒有什麽優秀的範例來啟發並模仿。
那麽,在大模型套用開發時代,大家都在討論的Agent到底應該如何設計實作。本文作者黃佳(代表作:GPT圖解,動手做AI Agent)將以幹貨的方式,全面解析 7 大認知框架的設計模式和實作方式。
Agent認知框架的4種設計模式
吳恩達教授在紅杉資本的人工智慧峰會(AI Ascent)上談到了自己對於AI Agent認知框架設計模式的四種分類,包括反思、工具使用、規劃、多智慧體協作。

吳恩達教授提出的Agent認知框架的4種設計模式
這四種基本的思維框架設計模式分別是:
反思(Reflection):Agent透過互動學習和反思來最佳化決策。
工具使用(Tool use):Agent 在這個模式下能呼叫多種工具來完成任務
規劃(Planning):在規劃模式中,Agent 需要規劃出一系列行動步驟來達到目標。
多Agent協作(Multiagent collaboration):涉及多個Agent之間的協作。
Agent認知框架的技術架構
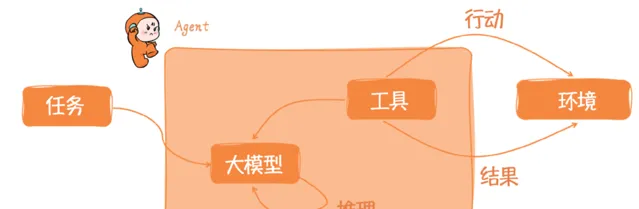
OpenAI公司的安全系統主管Lilian Weng也提出了一個由大模型驅動的自主Agent系統的架構,其中包含規劃(Planning)、記憶(Memory)、工具(Tools)、執行(Action)四大要素。

在這個架構中,Agent位於中心位置,它透過協同各種元件來處理復雜的任務和決策過程。
規劃 :Agent需要具備規劃(同時也包含決策)能力,以有效地執行復雜任務。這涉及子目標的分解(Subgoal decomposition)、連續的思考(即思維鏈,Chain of thoughts)、自我反思和批評(Self-critics),以及對過去行動的反思(Reflection)。
記憶 : 包含了短期記憶和長期記憶兩部份。短期記憶與上下文學習有關,屬於提示工程的一部份,而長期記憶涉及資訊的長時間保留和檢索,通常是透過利用外部向量儲存和快速檢索。
工具 :這包括了Agent可能呼叫的各種工具,如行事曆、小算盤、程式碼直譯器和搜尋功能,以及其他可能的工具。由於大模型一旦完成預訓練,其內部能力和知識邊界基本固定下來,而且難以拓展,那麽這些工具顯得異常重要。它們擴充套件了Agent的能力,使其能夠執行超出其核心功能的任務。
執行 (或稱行動):Agent基於規劃和記憶來執行具體的行動。這可能包括與外部世界互動,或者透過工具的呼叫來完成一個動作(任務)。
圍繞著這個架構,一系列的Agent認知框架開始落地。接下來,我們將重點介紹幾種具有代表性的Agent認知框架設計模式及其實作思路。
7種Agent認知框架的具體實作
下面,我們就來說一說主流的7種Agent認知框架的基本思想,並簡明扼要的闡述如何具體實作這些框架。
框架 1 思維鏈(Chain of Thought)
在Agent認知框架領域,開一代風氣之先的就是Chain-of-Thought Prompting這篇論文,這篇論文的出現甚至是早於ChatGPT。
在大模型推理能力普遍較弱的時代,這篇論文透過引入連貫的思考過程來引導模型進行更深入的邏輯推理,極大地提高了模型處理復雜問題的能力。這種方法不僅最佳化了模型的推理過程,還改善了輸出的可解釋性,使得模型的決策過程對於使用者來說更加透明和易於理解。
論文中的Chain of Thought簡稱CoT,即思維鏈,是指在解決問題過程中形成的一系列邏輯思考步驟。在AI領域,尤其是在自然語言處理和機器理解任務中,CoT方法透過模擬人類的思考過程來提高模型的理解和推理能力。透過明確展示解決問題的邏輯步驟,CoT有助於增強模型的透明度和可解釋性。
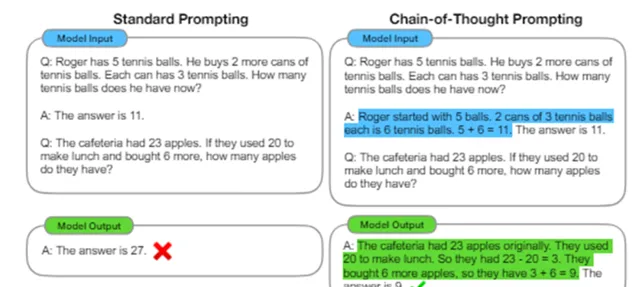
Chain-of-Thought論文中的思維鏈範例
其實,我們設計Agent時,需要參照的就是其方法論中的思想精華,參悟了思想,我們就可以透過精心設計的提示工程樣版,來實作CoT框架。
舉例來說,假設我們需要建立一個模型,用於評估個人的信用等級。這是一個典型的金融服務場景,其中涉及多個變量和邏輯判斷。
在CoT框架下,我們可以設計以下提示,以幫助AI模型透過邏輯推理來評估信用等級:
考慮到申請人的以下資訊:
- 年齡:35歲
- 年收入:$50,000
- 信用歷史:無違約記錄
- 負債:$10,000的信用卡債務
- 資產:無房產,有一輛值$15,000的汽車
步驟1:評估信用歷史。申請人沒有違約記錄,這是一個積極的信用因素。
步驟2:考慮年收入與負債的比例。申請人的年收入為$50,000,而負債為$10,000,債務收入比為20%,這表明申請人有足夠的收入來覆蓋債務。
步驟3:考慮資產情況。雖然申請人沒有房產,但有一輛汽車,可以作為貸款的擔保。
步驟4:基於以上分析,綜合評估申請人的信用等級。
最終判斷:根據以上邏輯推理,申請人的信用等級應該是中等偏上。
下面是一個使用OpenAI API呼叫CoT框架的範例,這裏使用Python語言進行編程。該程式碼透過發送一個包含邏輯推理步驟的詳細問題描述到模型,從而獲得關於個人信用評估的決策推理。
from openai import OpenAIclient = OpenAI()completion = client.chat.completions.create( model="gpt-4", # 使用GPT-4模型 messages=[ {"role": "system", "content": "你是一個專門處理信用評估的智慧助手,能夠透過邏輯推理來分析申請人的信用狀況。"}, {"role": "user", "content": """ 考慮以下申請人的資訊: - 年齡:35歲 - 年收入:50,000美元 - 信用歷史:無違約記錄 - 負債:10,000美元的信用卡債務 - 資產:無房產 分析步驟如下: 1. 根據年齡、收入和信用歷史來評估違約風險。 2. 考慮負債與收入的比率,判斷負債水平是否合理。 3. 評估無房產的風險因素,考慮是否會影響申請人的償債能力。 根據上述分析步驟,請評估這位申請人的信用等級。 """} ])print(completion.choices[0].message)
這裏,我們構造了一個詳細的提示,引導模型沿著設定的思維鏈路進行邏輯推理。這種方式不僅有助於生成更可解釋的答案,而且能夠提高決策的準確性。
CoT這篇文章是一石激起千層浪,後面研究大模型推理認知的文章就逐漸豐富了起來。
框架2 自問自答(Self-Ask)
順著Chain-of-Thought的思路,就有了Self-Ask是對CoT的進一步擴充套件。
Self-Ask它允許模型自我生成問題,進行自查詢來獲取更多資訊,然後再結合這些資訊生成最終答案。這種方法使模型能夠更深入地探索問題的各個方面,從而提高答案的品質和準確性。

Self-Ask這種認知框架在需要深入分析或創造性解決方案的套用中非常有用,例如創意寫作或復雜查詢。
假設我們正在設計一款新的智慧型手錶,需要考慮使用者的多樣化需求和技術可能性。我們可以設定如下的 Self-Ask 框架
from openai import OpenAIclient = OpenAI()completion = client.chat.completions.create( model="gpt-4", # 使用GPT-4模型 messages=[ {"role": "system", "content": "你是一個專門處理產品設計創新的智慧助手,能夠自我生成問題來探索創新的設計解決方案。"}, {"role": "user", "content": """ 我們正在開發一款新的智慧型手錶。請分析當前市場上智慧型手錶的主要功能,並提出可能的創新點。 """}, {"role": "system", "content": "首先,考慮目前市場上智慧型手錶普遍缺乏的功能是什麽?"}, {"role": "system", "content": "接下來,探討哪些新增功能可能吸引健康意識強的消費者?"}, {"role": "system", "content": "最後,分析技術上可行的創新功能,這些功能如何透過可穿戴技術實作?"} ])print(completion.choices[0].message)
在這個範例中,透過系統自我生成的問題和回答,不僅引導了深入的市場和技術分析,還激發了對潛在創新點的思考。這種方法有助於在產品設計初期階段就辨識和整合創新的元素。
你可以透過Few-shot的方式,以這個樣板為例,讓大模型自己進行更多有創造性的思考,往往能激發我們開始並沒有想到的創意點子。

更多細節可以了解我的課程
框架3 批判修正(Critique Revise)或 反思(Refection)
Critique Revise(批判修正)這個認知框架也叫做Self-Refection,是一種在人工智慧和機器學習領域中套用的框架,主要用於模擬和實作復雜決策過程。這種架構基於「批判」和「修正」兩個核心步驟,透過不斷叠代改進來提高系統的效能和決策品質。
批判(Critique):在這一步驟中,系統會評估當前的決策或行為產出,並辨識出其中的問題或不足之處。這一過程通常涉及與預設目標或標準的比較,以確定當前輸出與期望結果之間的差距。
修正(Revise):基於批判步驟中辨識的問題,系統在這一步驟中會調整其決策過程或行為策略,以期改進輸出的品質。修正可以是對現有演算法參數的調整,也可以是采用全新的策略或方法。
Critique Revise 認知架構的目標是透過不斷自我評估和調整,使系統能夠學習並改進決策過程,從而在面對復雜問題時做出更加有效的決策。
假設一家公司正在評估其最近的數位行銷活動效果,以便制定未來的行銷策略。使用 Critique Revise 框架,可以透過以下步驟來最佳化決策過程:
批判(Critique):系統首先分析現有行銷活動的數據,包括廣告點選率、轉化率、消費者互動情況等,並與既定的目標或行業標準進行比較。在這一階段,系統辨識出當前策略的不足之處,例如目標受眾定位不準確、廣告內容不吸引人或預算分配不合理。
修正(Revise):基於批判階段的分析結果,系統提出改進方案。這可能包括調整目標受眾、重新設計廣告內容、或最佳化預算分配策略。此外,系統還可能推薦測試新的行銷渠道或技術,以提高整體行銷效果。
程式碼實作如下:
from openai import OpenAIclient = OpenAI()# 執行 Critique 階段critique_completion = client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": "你是一個市場行銷分析助手。"}, {"role": "user", "content": "分析最近一次行銷活動的效果,並指出存在的問題。"} ])# 執行 Revise 階段revise_completion = client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": "你是一個市場策略最佳化助手。"}, {"role": "user", "content": "根據之前的批判,提出具體的改進措施。"} ])print("Critique Results:", critique_completion.choices[0].message)print("Revise Suggestions:", revise_completion.choices[0].message)
在這個過程中,AI系統首先執行 Critique 階段,分析和辨識問題;然後在Revise 階段,根據辨識的問題提出具體的改進措施。這種方法幫助企業深入理解市場動態,精確調整行銷策略,從而實作更有效的市場應對。
框架 4 函式(工具)呼叫(Function Calling/Tool Calls)
Function Calling是由OpenAI提出的一種AI套用開發框架。在這種架構中,大語言模型被用作呼叫預定義函式的引擎,負責判斷根據使用者的需要,自動呼叫哪些工具。
OpenAI Assistant中的支持的工具有程式碼直譯器(數據分析)、函式呼叫、檔檢索工具等等。對於需要與現有系統整合或執行具體技術任務的套用,如自動化指令碼或數據分析,此方法非常合適。
當然,工具呼叫這種框架並不僅僅屬於OpenAI API所專有,LangChain中的Agent也整合了大量的可用工具。

LangChain中的工具和工具箱
關於Agent的工具呼叫,目前的常見大模型開發框架,都已經形成了非常完備的解決方案。
框架 5 ReAct(Reasoning-and-Acting)
那麽,有了CoT的逐步推理, 有了Refection的反思,又有了工具呼叫,我們就終於來到了Agent認知框架的集大成者—— ReAct框架。
這個框架整合了先前的CoT和Reflection方法,並引入了工具呼叫功能,進一步增強了模型的互動能力和套用範圍,代表了在Agent認知框架開發中的一個新的裏程碑。
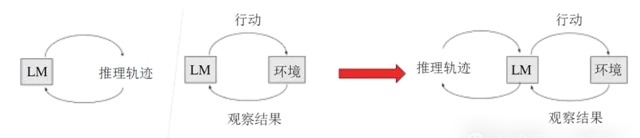
ReAct論文中指出,既要有推理,又要有行動
ReAct框架是推理和行動的整合,Reasoning and Acting, ReAct框架的核心思想在於在思考,觀察和行動 反復迴圈,叠代,不斷最佳化解決方案,知道問題最終解決位置,這就不僅使Agent能夠進行復雜的內部推理,還能即時反應並調整其行為以適應不斷變化的環境和需求。
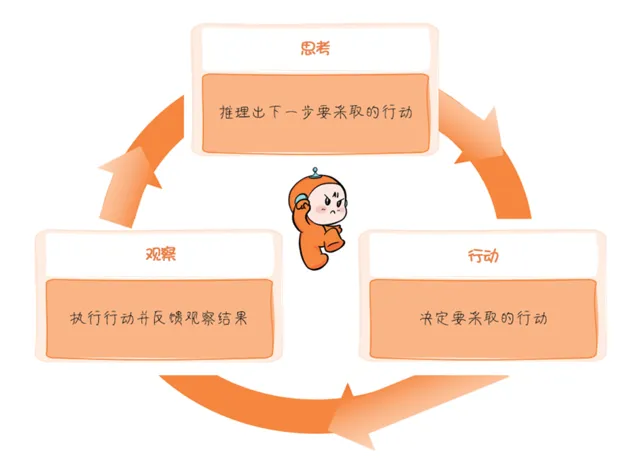
目前,ReAct框架已經被無縫整合至LangChain,開發者可以非常輕松地建立ReAct Agent來完成具體任務。
更多細節可以了解我的課程
框架 6 計劃與執行(Plan-and-Execute)
Plan-and-Execute可以轉譯為計劃與執行架構。這種架構側重於先規劃一系列的行動,然後執行。它使LLM能夠先綜合考慮任務的多個方面,然後按計劃行動。在復雜的計畫管理或需要多步驟決策的場景中尤為有效,如自動化工作流程管理。

Plan-and-Solve論文中的範例
目前,LangChain的Experiment(實驗包)中支持Plan-and-Execute框架,開發者可以嘗試建立Plan-and-Execute Agent,對任務先計劃,再具體執行。
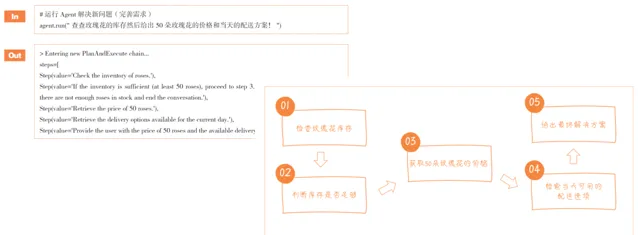
Plan-and-Solve的實作範例
框架 7 多Agent協作(Multi-Agents Collaboration)
多Agent系統(Multi-Agent System)的確是一個新的研究熱點。這類研究關註如何使多個Agent協同工作,實作復雜的任務和目標。這包括合作、競爭以及協商策略的研究。
這類多Agent協作框架的代表性作品是AutoGen和MetaGPT。
AutoGen框架中的Agent客製(Agent Customization)功能允許開發者對Agent進行客製,用以實作不同的功能。
MetaGPT的框架,它將標準操作程式(SOPs)與基於大模型的多智慧體系統相結合,使用SOPs來編碼提示,確保協調結構化和模組化輸出。這種框架允許智慧體在類似流水線方法的範式中扮演多樣化的角色,透過結構化的智慧體協作和強化領域特定專業知識來處理復雜任務,提高在協作軟體工程任務中解決方案的連貫性和正確性。
MetaGPT的Demo中,構建了一個軟體公司場景下的多Agent軟體實體,它能夠處理復雜的任務,模仿軟體公司的不同角色。其核心理念是"程式碼等同於團隊的標準操作程式(Code = SOP(Team))",將標準操作程式具體化並套用於由大模型組成的團隊。
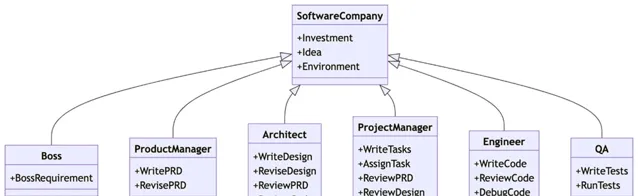
軟體公司組織角色圖
這個軟體公司的組織角色圖突出了公司內的不同角色及其職責。
老板(Boss):為計畫設定總體要求。
產品經理(Product Manager):負責編寫和修訂產品需求文件(PRD)。
架構師(Architect):編寫和修訂設計,審查產品需求文件和程式碼。
計畫經理(Project Manager):編寫任務,分配任務,並審查產品需求文件、設計和程式碼。
工程師(Engineer):編寫、審查和偵錯程式碼。
品質保證(QA):編寫和執行測試,以確保軟體的品質。
你只要輸入一行具體的軟體開發需求。經過幾輪協作,MetaGPT的假想軟體工程團隊就能夠開發出真正可用的簡單APP。
當然MetaGPT的功能不僅限於此,還可以用於其他場景構建應用程式。
各種認知框架的組合運用
上述認知框架當然是可以的組合的比如說,ReAct框架中,就一定應該配置Tool Calls,透過工具的呼叫+Tool Calls 才能夠改變環境的狀態,繼續觀察,才能夠進一步的思考。
當然,每種Agent認知架構都有自己獨特的優勢,至於選擇哪一種,如何組合起來更實用,取決於具體需求、套用場景和期望的使用者體驗。選擇適合套用的認知架構是大語言模型套用開發的一個關鍵步驟。
好吧,今天的幹貨分享就到這裏。我試圖用比較簡短的篇幅,從理論到實踐,全面系統地分析了Agent技術的發展現狀,希望能夠為你的Agent套用開發提供了參考和啟發。未來,Agent技術的進一步發展將深刻影響人工智慧在各領域的套用,推動人機協同邁上新台階。
上述所有範例,我的課程中,均有程式碼實作和詳細講述!從小白到專家,一起入群學習大模型。
更多細節可以了解我的課程
參考資料
1.https://36kr.com/p/2716201666246790 - 吳恩達最新演講:AI Agent工作流的未來
2.https://lilianweng.github.io/posts/2023-06-23-agent/ - LLM Powered Autonomous Agents
3.Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , 36th Conference on Neural Information Processing Systems (NeurIPS 2022).
4.Press, O., Zhang, M., Min, S., Schmidt, L., Smith, N. A., & Lewis, M. (2022).
Measuring and Narrowing the Compositionality Gap in Language Models. arXiv preprint arXiv:2212.09551.
5.Wang, L., Xu, W., Lan, Y., Hu, Z., Lan, Y., Lee, R. K.-W., & Lim, E.-P. (2023). Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models. arXiv.
6.Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv preprint arXiv:2210.03629.
7.https://github.com/geekan/MetaGPT - MetaGPT: The Multi-Agent Framework











