【導讀】GPT-4o 的問世再次驚艷了世界, 本文深入探討了 GPT-4o 在語音互動領域的突破性進展,揭示了其在即時性和表現力方面的優勢,並對實作這一技術所面臨的挑戰進行了詳細分析。除此之外,作者還對 OpenAI 的發展策略進行了評估,指出了 GPT-4 在邏輯嚴密性和上下文處理能力上的局限性,並對未來 GPT-5 的發展方向和潛在挑戰提出了見解。
作者 | 盧威
責編 | 唐小引
出品丨AI 科技大本營(ID:rgznai100)

GPT-4o 在語音互動的突破
GPT-4o 令人驚艷之處首推語音互動的即時性和表現力。 有關如何實作 OpenAI 僅透露了寥寥數句。此前的 Voice Mode 與大家能想到並且有所實作的方式一樣,透過三個模型的串聯來實作,①一個「簡單」(相對 GPT-3.5/4 的規模而言)音訊轉文字的模型,無疑應是用 OpenAI 開放的 Whisper 模型。得到的文字輸入②GPT-3.5 或 GPT-4,後者輸出的文字再經由③一個較「簡單」的文字轉語音(TTS)模型得到語音輸出。多種腔調的表現力方面主要由③實作,市面很多產品都可以做到,本文不做贅述。此處先關註延遲問題。
Voice Mode 在三步的流水線上能實作平均 2.8(GPT-3.5)到 5.4(GPT-4)秒的延遲(latencies),這有多難呢?要看 Whisper 的一些基本指標,如下圖。
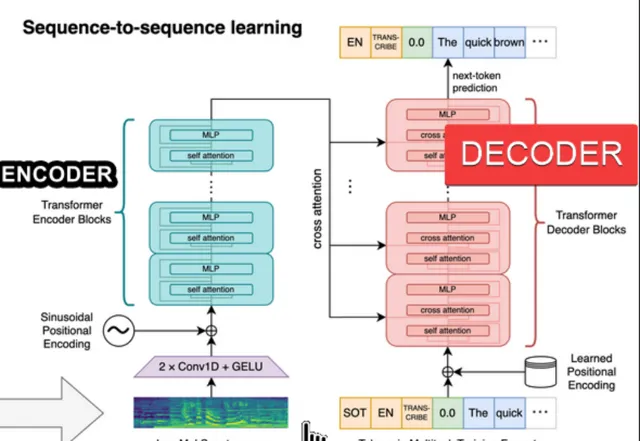
音訊是切分為 30 秒的片段,轉化為頻譜數據輸入 Transformer 模型來做辨識的,不足 30 秒的語音可以填充空白。模型預訓練時都是這樣的 30 秒語音片段及其對應的文字。 30 秒的標準應該是平衡了訓練語料的特點和計算量的考量。 片段太短則資訊不足,正確率降低,太長則計算量過大。
顯然這樣訓練出來的模型適合沒有延遲要求的離線轉錄。在需要即時辨識的場景下會遇到挑戰。即時的對話不太可能一方說 30 秒才輪到對方,往往一次說話只有幾秒鐘。最好是接收到多少語音,比如一個詞或 1 秒,就呼叫一次模型。經過最佳化的 Whisper 模型,比如 Hugging Face 實作的 Insanely Fast Whisper large-v3 和 Faster whisper large v3 在 Nvidia 2080Ti GPU 上轉錄一秒鐘音訊大約需要 50 毫秒。那麽主要的延遲應該是來自於第②步的大語言模型推理。
但是 1 秒的語音與 30 秒的預訓練數據差異太大,準確性必然是較低的,需要盡可能增加一次辨識的語音長度,這與降低延遲是矛盾的。目前通常采取的辦法是以單詞、句子或固定短時間的片段進行漸進式辨識,比如片段 1+空白填充辨識一次,片段 1+片段 2+空白填充辨識一次,片段 1+片段 2+片段 3+空白填充(不超過 30 秒)辨識一次……後一次或幾次辨識的結果與前一次辨識的有相同的字首部份,說明字首部份的辨識很可能是正確的,那就把對應的片段,比如片段 1,視為已經完成,不需要再保留到後續的辨識呼叫中了。
一個開源實作的例子可以參考:
https://github.com/luweigen/whisper_streaming
這種方式下,一個片段經歷多次重復計算,多個片段一起辨識提高正確率也導致更長的延遲。實測 在 NVIDIA A40 GPU 上能實作 3 秒左右的高品質語音到文字即時轉錄延遲是學術和開源屆的水平。
Voice Mode 在加了 GPT-3.5 的文字到文字生成和文字到語音合成兩步之後仍能達到 2.8 秒的延遲,必然進行了更深度的軟硬體系統最佳化。同時要保持 Whisper 標準的離線轉錄正確率,可能要用更小的語音片段對模型進行微調(Fine-tune)或者再訓練。
GPT-4o 進一步實作了最小 232 毫秒,平均 320 毫秒的響應時間(「respond time」)。雖然這有可能有一些「技巧」在裏面,比如對絕大多數的問題,可以都先響應一個禮貌的短語「當然」、「好的」之類實際上不需要理解和推理的部份,實作盡可能短的「響應時間」,但在 2.8 秒上繼續提高仍是困難的。
有關如何實作, OpenAI 只給出一句話說 GPT-4o 是單個同時處理文字、聲音和視訊的端到端模型,與 Google 等其他家的多模態原理並無二致。 即便直接從語音輸入預測語音輸出,以上討論的語音切片問題仍然存在。
輝達研究科學家 Jim Fan 猜測 GPT-4o 是對 Voice Mode 式的三步流水線的端到端結果進行知識蒸餾。 那麽它適應的場景廣泛性和溝通內容的多樣性和復雜度可能是不及文字到文字的 GPT-4 的。上述分析的語音片段微調或再訓練問題,Jim 重點討論了訓練數據,可能來自於網路上的多媒體記錄的對話,或者用 Voice Mode 式的三步流水線來合成數據,後者顯然是 OpenAI 具備優勢可以繼續發揮的。
GenAI 發展策略
GPT-4 之後,OpenAI 釋出了 GPTs、GPT-4V、GPT-Turbo、Sora 和 GPT-4o,每一次都引起媒體和部份使用者的追捧。但始終沒有觸及 GPT-4 本身的問題,比如很多時候不能保證結果符合嚴密的邏輯,上下文視窗不足以滿足相對復雜的任務需要等。
相反,在學術和開源社群中得到了成果的範圍內,比如更高效的 Transformer 實作、更好的 RAG 和 Agent 實作、多模態的原理、更好的媒體生成控制方法等, 雖然沒有證據表明 OpenAI 直接使用了開源的技術,但 OpenAI 的新產品並沒有超出這些能力範圍,只是進行了更成熟的產品化。 越來越更偏向對正確性和可控性要求不那麽高的趣味、情感方面的需求滿足。結果每次都導致開發者一片哀鴻遍野。
考慮到競爭者與 GPT-4 仍有實際表現上的差距,OpenAI 這樣的策略在情理之中。站在現在這個時間點上我們可以這麽分析 OpenAI 的強項:
人才優勢 , 相信在 AI 領域它目前有最大的機率吸引人才,最大的機率能做好各種 AI 的工程實作和最佳化。但是它能涉及的領域必然是極其有限的。
「數據飛輪」 ,作為最多使用者的 AI 產品能夠獲得最多的數據,但是考慮到使用者的使用行為表現,數據的實際效果有多好,可能並沒有想象中的重要。
「智力飛輪」 ,體現在上述討論的合成數據方面,現有的模型智力可以生成更有效的訓練數據,用於進一步提升模型的智力,形成正反饋。OpenAI 擁有智力最高的 GPT-4 模型,因此在這點上是毋庸置疑的優勢。
但是要進一步提高 GPT-4 本身的基礎能力問題,如果沿著 OpenAI 自己探索出來的 Scaling Law 路徑,很可能需要 100 倍 GPT-4 規模。可能是 100 倍的模型參數量,或者 100 倍的訓練數據量,或者兩者組合,這應該才是真正的 GPT-5。 以 OpenAI 的營收水平,做 GPT-5 應該是有財務壓力的,並沒有足夠的優勢保證搶先 Google 等對手實作這樣的嘗試。 而這樣的 GPT-5 能比 GPT-4 提高多少,比如能否可靠地生成復雜軟體計畫的程式碼?能把 SWE-bench 這樣的任務成績提高多少?還是未知數。
因此在這樣的情況下,借鑒 OpenAI 的策略應是有效的,錯開直接的競爭也是可能的。例如我們關註的輔助軟體開發領域,在模型智慧獲得突破性提高之前,可以嘗試將目前對標人類中上水平的評測和訓練數據進行更細致的分層,使模型以超越人類的成功率的完成特定層次的工作,獲得「驚艷」和實用的表現。在此基礎上,領域專家的深入參與會帶來數據品質的提高。「智力飛輪」方面,StarCoder2-Instruct (Wei et al., 2024)等開放研究也初步發現用開源模型也能實作高品質合成數據和模型自我提高。
在翹首以盼 GPT-5 的現在,或許未來我們可能會發現 GPT-5(或者某種被定義為 AGI 的產品)也並不能在所有領域和場景中完全解決現在 GPT-4 的問題。將生成式 AI 在特定用途中做得更可靠和方便,仍有很多發揮人類聰明才智和汗水的空間。












