整理 | 王軼群
責編 | 王啟隆
出品丨AI 科技大本營(ID:rgznai100)
與 OpenAI 對齊失敗後,Jan Leike 選擇與 Anthropic 對齊。
當地時間5月28日午間,OpenAI 的前首席安全研究員 Jan Leike 釋出 X 動態宣布,他已加入曾經的競爭對手公司 Anthropic。
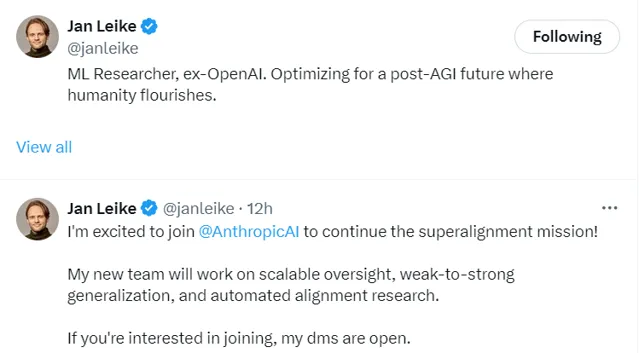
Jan Leike 表示:「我很高興加入 Anthropic,繼續超級對齊任務!我的新團隊將致力於可延伸監督、弱到強泛化和自動對齊研究。如果您有興趣加入,我的 DMS 是開放的。」
此前,Jan Leike 曾是 OpenAI 旗下 Super Alignm ent(超級對齊)團隊的安全主管。該團隊成立於2023年,專註於人工智慧的長期風險,其超級對齊技術旨在協助提升大模型的安全性。
Leike 加入競爭對手的團隊,並非背叛,而是無奈之舉。
太難了,在 OpenAI 搞不下去
兩周前,Jan Leike 剛剛從 OpenAI 離職,緊跟著 OpenAI 聯創兼 Super Alignment 首席科學家 Ilya Sutskever 宣布離職之後。僅在 Ilya Sutskever 和 Jan Leike 兩員大將離職的幾日後, OpenAI 便宣布解散該安全團隊。
而在安全團隊大變動的前一天,OpenAI 剛剛釋出了震動 AI 界的「旗艦級」生成式人工智慧模型 GPT-4o,該幾乎覆寫了大模型互動定義,可以即時對音訊、視覺和文本進行推理,語音響應時間短至232毫秒,與人類反應速度一致。
「光鮮的產品」背後,在 OpenAI 內部,安全的推進曾變得異常艱難。
在離職前,Leike 共同領導的超級對齊團隊曾有一個雄心勃勃的目標,即在未來四年內解決控制超級智慧 AI 的核心技術挑戰,但經常發現自己受到 OpenAI 領導層的束縛。
Leike 在離職後曾爆料稱,最近幾年OpenAI已經不惜內部文化,把「吸引眼球的產品」放在安全準則之前,並表示超級對齊團隊「在計算資源方面捉襟見肘」,完成這項關鍵研究「變得越來越困難」。
在 Ilya Sutskever 和 Jan Leike 之後掀起的 OpenAI 離職潮風波中,多位離職員工已爆料了 OpenAI 內部忽視 AGI 風險、超級對齊團隊算力分配嚴重讓位於新產品研發、忽視安全原則、超級對齊業務走投無路等狀況。
此情此景,與一年前OpenAI 開300萬+年薪招超級AI研究員、投20%總算力成立超級對齊團隊的高調官宣,形成鮮明對比。
實際上,自從OpenAI發生第一輪宮鬥、Sam Altman被罷免以來,整個OpenAI的情緒就開始不對勁。顯然,Altman在合作夥伴關系和產品重點方面的發展方向,已經超出了大多數人能接受的程度。他的危險面目,正隨著時間線的推移,逐漸暴露。
據 OpenAI 前董事會成員 Helen Toner 在「The Ted AI Show」播客節目中再次曝光的OpenAI宮鬥細節,Sam Altman 在多場合提供了關於公司安全流程的不準確資訊。這意味著董事會基本上不可能知道這些安全流程的運作情況如何,或者可能需要改變什麽。
而與 Ilya Sutskever 相似, Helen Toner 本身也是倡導安全的離開 OpenAI 的前董事之一,目前 Toner 任喬治城大學安全與新興技術中心戰略總監。
2023年7月, 還在OpenAI 任職的 Ilya Sutskever 與 Jan Leike 撰寫了一份 OpenAI 公告,涉及超級對齊的計畫,警示道:雖然超級智慧可以幫助解決世界上許多最重要的問題,但它也可能非常危險,並可能導致人類喪失權能,甚至導致人類滅絕。
對於在 OpenAI 離職,Leike 表示:「離開這份工作是我做過的最艱難的事情之一,因為我們迫切需要弄清楚如何引導和控制比我們聰明得多的人工智慧系統。」
而目前,OpenAI 又在訓練新的光鮮產品了。就在Leike宣布加入 Anthropic 繼續超級對齊任務的當日,OpenAI 宣布其正在訓練新的旗艦級人工智慧大模型,這款模型將接替目前廣泛用於ChatGPT的GPT-4技術。OpenAI 表示期望新模型能夠「邁向下一個層次的能力」,並致力於構建AGI——一種能夠執行人類大腦所有功能的機器。新模型預期將成為推動各種AI產品的核心,包括聊天機器人、類似於蘋果Siri的數位助理、搜尋引擎及影像生成器。
同時,頗具戲劇性的是,這一次的大模型訓練伴隨著一次所謂的安全動作。僅在 Leike 宣布離職後的兩個小時後,OpenAI 宣布其董事會成立了安全與保障委員會。

OpenAI 在官網發文稱,該安全與保障委員會,由董事 Bret Taylor(主席)、Adam D'Angelo、Nicole Seligman 和 Sam Altman(執行長)領導。該委員會將負責就 OpenAI 計畫和營運的關鍵安全與保障決策向全體董事會提出建議,以探索如何處理新模型和未來技術可能帶來的風險。該公司表示:「我們為能夠打造並推出在能力和安全性上均處於行業領先的模型感到自豪,同時,我們歡迎在這一重要時刻展開充分的討論。」該委員會將進行 90 天的評估,並將結果報告給董事會。OpenAI 計劃采納合適的建議,並在董事會審查後公開分享更新。
這一舉動,是 OpenAI 在內部爆料和輿論壓力下在安全問題上的及時轉向,還是內部醞釀已久的另一種策略顯露,90天後或授權以略見端倪。
意見不合成就 Anthropic
Jan Leike 的快速入職 Anthropic,並非匆忙之策,而是早有機緣。
扒一扒 Anthropic 的成立背景,就能看到,其創始人與 OpenAI的意見不合,一定程度上成就了今日的 Anthropic。
Anthropic 執行長 Dario Amodei ,之前曾擔任 OpenAI 的研究副總裁。
Dario Amodei 在 OpenAI 成立之初,就被其「實作安全的通用人工智慧(AGI)」這一初衷吸引。當時探索AI的可操縱、可解釋性是OpenAI的研究方向之一,這正是Dario Amodei 所擅長的領域。
在OpenAI期間,Dario Amodei作為GPT-2、GPT-3的核心研發成員,在訓練AI模型的過程中便著眼於在AI迅猛發展的過程保證其安全可控性,包括AI能反映了人類的價值觀,能夠解釋AI決策背後的邏輯以及AI能夠在不傷害人類的情況下學習。
然而,與此同時,大量的人力成本與訓練成本開支消耗著這家公司的理想主義。當非盈利性的 OpenAI 在2019年接受了微軟註資後,內部團隊也逐漸出現了分裂。以 Dario Amodei 為代表的部份核心成員認為,隨著 AI 模型的增大、算力的增強,AI 的安全性、可操縱、可解釋性變得更加重要,而不是盲目叠代比GPT-3 更大的 AI 模型,應該把解決神經網路的「黑盒」問題放到更重要的位置。
在微軟註資後,OpenAI 很快將上述問題還未解決的 GPT-3 交給微軟來使用,OpenAI 的逐漸商業化以及對創始初心的背離。 以 Dario Amodei 為代表的一群技術理想主義者不願再與微軟及商業化方向捆綁,想要重現 OpenAI 創始初衷。
2021年2月,Dario Amodei 和妹妹 Daniela 聯手創立了 Anthropic,同時帶走了10名前 OpenAI 員工。

這10名員工,包括 GPT-3 論文第一作者Tom Brown、OpenAI 前政策負責人 Jack Clark,以及Gabriel Goh、Jared Kaplan、Sam McCandlish、Kamal Ndousse等。Anthropic 創始核心成員大部份來自於OpenAI原有團隊,並在AI可解釋性、AI 模型安全設計事故分析、引入人類偏好的強化學習等方面有頗深的造詣。
當時曾有媒體預測,面臨安全核心成員出走的OpenAI可能在這些領域會遜色於Anthropic。而前 OpenAI 超級對齊團隊領導者 Jan Leike 的加入,更會加劇這一傾向。
Anthropic旨在創造可操縱、可解釋的人工智慧系統,「當今的大型通用系統可以帶來顯著的好處,但也可能無法預測、不可靠和不透明:我們的目標是在這些問題上取得進展。」Dario Amodei曾對外表示,「Anthropic的目標是推進基礎研究,讓我們能夠構建更強大、更通用、更可靠的人工智慧系統,然後以造福人類的方式部署這些系統。」
承接創始人的意願,Anthropic 經常將自己定位成為比 OpenAI 更註重安全的 AI 公司。目前,多個層面顯示出, Leike 的團隊與 OpenAI 最近解散的超級對齊團隊的使命很相似。
Amodei 在與 OpenAI 發展方向產生分歧時,想要先解決的解決神經網路的「黑盒」問題,可以理解為能夠將數據轉變成其它東西一個演算法,其中的問題在於,黑盒子在發現模式的同時,經常無法解釋發現的方法。
此前,谷歌 AI Overviews 提供的「披薩上塗上膠水」「人每天應該至少吃一塊小石頭」等奇怪搜尋答案,也是基於互聯網數據輸入的轉化造成的輸出失控。
而超級對齊是一種確保人工智慧系統的行為與人類價值觀和目標高度一致的技術和方法論。隨著 AI 技術的發展,尤其是在決策能力和自主性方面,確保它們的行動不會偏離人類的最佳利益變得尤為重要。
目前,超級對齊的研究主要集中在如何透過演算法和政策確保 AI 系統在接受訓練和執行任務時能夠理解並遵循人類的倫理標準。研究人員和工程師們正在探索多種機制,包括強化學習的修正、決策框架的倫理整合,以及互動式機器學習,這些方法都旨在提高 AI 系統對人類指導的響應性和適應力。
而Anthropic 公司的英文單詞意思,就是有關人類的。技術如何在安全可控的條件下良性發展、造福人類,AI 理想如何不受制於商業利益,將是Anthropic 創始團隊和新加入的 Leike 的重要課題。
AI 安全首當其沖,超級對齊前路漫漫
安全、監管,顯然已成為 AI 行業的熱點議題和首要批判點。
超級智慧的機器可以替代人類執行一些復雜的職業任務,提高效率,最佳化決策。然而,正如所有強大的工具一樣,AI 也引發了一系列擔憂,其中最引人註目的可能就是關於它們是否會引發所謂的「技術奇異點」——即AI超越人類智慧,可能帶來不可預測的後果,甚至是災難性的全球風險。
在追求技術突破的同時,我們如何確保這些智慧系統不僅遵循我們的價值觀,還能促進社會整體的福祉?這就是超級對齊的用武之地,旨在引導 AI 的發展方向,確保技術進步能夠在安全和倫理的框架內推進,從而避免潛在的負面影響。
而就在上周末,馬斯克與 AI 領域先驅楊立昆就 AI 的安全監管問題在社交媒體 X 上發生了爭吵,暴露了在人工智慧風險上的關鍵分歧可能會導致科技界分裂。
兩人截然不同的立場凸顯了業界對 AI 未來發展監管路徑的深刻分歧:
楊立昆表示,現在憂慮 AI 帶來「生存風險」並急於監管還為時尚早。他認為,人工智慧的安全性在於人類的設計與控制,並以渦輪噴射發動機為例,指出在確保高度可靠性後才廣泛部署,AI 亦應遵循類似路徑。楊立昆重申了他的「開放而非監管」立場,倡導開源和共享以促進技術的透明度與安全性。
而馬斯克則以他特有的幽默風格回應:「Prepare to be regulated」(準備接受監管),暗示監管的必要性。作為一位積極的監管支持者,馬斯克雖然對 AI 失控持有深切憂慮,但他並未放慢建立個人 AI 帝國的步伐。他強調,盡管監管「並不有趣」,但在 AI 可能「掌控一切」之前建立規則至關重要。隨後,這場罵戰逐漸上升到人身攻擊的層次,火藥味頗重。
人類大佬之間,尚有激烈分歧,技術如何辨識並對齊人類價值觀?
在要求 AGI 與人類價值觀對齊之前,首先要在人類自身形成統一共識 ,找到萬物的底層邏輯,並套用與技術標準。 這一共識,也包括對技術發展的認知以及對監管所持有的態度。
由此可見,在構建安全的 AGI 之前,還有諸多倫理及技術問題需要解決。
實作安全的AGI,道阻且長,然而如 Ilya Sutskever、Jan Leike、Dario Amodei 等先鋒,正在各自的領域全力以赴。
參考連結:
https://m.thepaper.cn/newsDetail_forward_27495059
https://baijiahao.baidu.com/s?id=1757259268935283497&wfr=spider&for=pc
開發者正在迎接新一輪的技術浪潮變革。由 CSDN 和高端 IT 咨詢和教育平台 Boolan 聯合主辦的 2024 年度「全球軟體研發技術大會」秉承幹貨實料(案例)的內容原則,將於 7 月 4 日-5 日在北京正式舉辦。大會共設定了 12 個大會主題:大模型智慧套用開發、軟體開發智慧化、AI 與 ML 智慧運維、雲原生架構……詳情👉: http://sdcon.com.cn/












