出品丨AI 科技大本營(ID:rgznai100)
台北時間 3 月 11 日,龍擡頭之日,零一萬物宣布成功研發出基於全導航圖的新型向量資料庫 「笛卡爾(Descartes)」,已包攬權威榜單 ANN-Benchmarks 6 項數據集評測第一名。
在國際權威評測平台 ANN-Benchmarks 離線測試中,零一萬物笛卡爾(Descartes)向量資料庫登頂 6 份數據集評測第一名,比之前榜單上同業第一名有顯著效能提升,部份數據集上的效能提升甚至超過 2 倍以上。
零一萬物表示,笛卡爾向量資料庫將用在近期即將正式亮相的 AI 產品中,未來也將結合工具提供給開發者。
解決大模型四大缺陷,向量資料庫成 AI 2.0 基礎設施
向量資料庫,又被稱為 AI 時代的資訊檢索技術,是檢索增強生成( Retrieval-Augmented Generation,RAG )內核技術之一。隨著大模型為代表的 AI 2.0 時代到來,圖片、視訊、自然語言等多模態的非結構化數據量陡增,區別於用來處理結構化數據的傳統資料庫。 向量資料庫專門用來儲存、管理、查詢和檢索向量化的非結構化數據。 它就像一塊外接的記憶盤,可供大模型隨時呼叫,以形成「長期記憶」,也被昵稱為大模型記憶的「海馬體」。對大模型套用開發者來說,向量資料庫是非常重要的基礎設施,在一定程度上影響著大模型的效能表現。

圖源:DALL·E 生成
大模型天然有 4 個缺陷,向量資料庫仿佛量身客製的「特效藥」,能精準解決每個痛點。
即時資訊: 大模型訓練時間長、更新慢,無法反應最新的資訊,其知識存在「截止期」的挑戰。向量資料庫采用輕量化更新機制,可以快速補充最新資訊。
私密保護: 使用者的安全私密數據不宜直接提供給大模型訓練,否則會有泄密風險,向量數據透過在推理階段扮演資訊傳遞的中間載體,破解了私密保護的難關。
幻覺矯正: 大模型常表現出的推理失真或產生幻覺的現象,可以透過向量資料庫提供的豐富知識參照,有效矯正和減輕此類問題。
推理效率: 大模型推理成本高,向量資料庫能夠作為一種緩存機制,避免每一次查詢請求都需要重新執行復雜的推理計算,極大地節省了計算資源。
AI 2.0 掀起的科技變革和平台變革,進一步強化了向量資料庫的作用。Google、微軟、Meta 等大廠的相關產品先後問世,Zilliz、Pinecone、Weaviate、Qdrant 等創業公司也異軍突起。2023 年,OpenAI 的向量資料庫合作方 Pinecone 完成了 B 輪 1.38 億美元融資,國內初創企業 Fabarta ArcNeural 也完成了上億元 Pre-A 輪融資。
挑戰權威向量資料庫效能評測, 笛卡爾包攬 6 項第一
ANN-Benchmarks 是當下業界最權威的向量資料庫效能測試工具,它可以展示不同演算法在不同真實數據集下的表現。
下面 6 份評測數據集涵蓋 glove-25-angular、glove-100-angular、sift-128-euclidean、nytimes-256-angular、fashion-mnist-784-euclidean、gist-960-euclidean,橫座標代表召回、縱座標代表 QPS( 每秒內處理的請求數 ),曲線位置越偏右上角意味著演算法效能越好,零一萬物笛卡爾向量資料庫在 6 項數據集評測中都處於最高位。
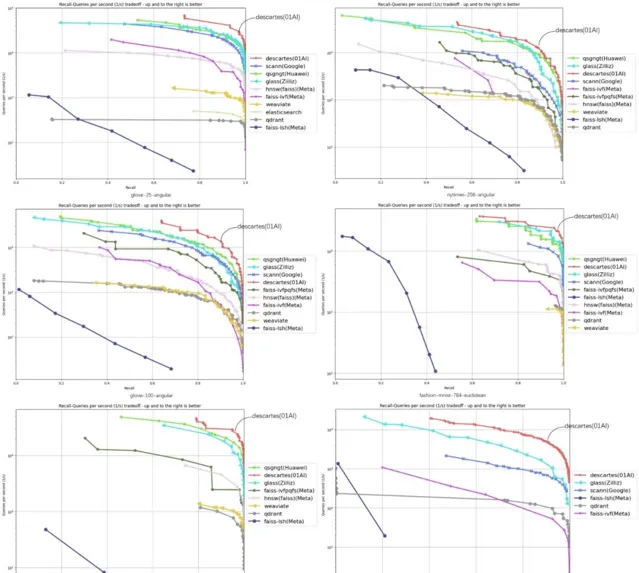
圖註:截至 3 月 10 日,ANN-Benchmarks 6 項評測中,笛卡爾(Descartes)向量資料庫位居 TOP1
眾所周知,「吞吐量 QPS」 是衡量資訊檢索系統( 例如搜尋引擎或資料庫 )查詢處理能力的重要指標。在原榜單 TOP1 基礎上,零一萬物笛卡爾向量資料庫實作了顯著效能提升,部份數據集上的效能提升超過 2 倍以上,在 gist-960-euclidean 數據集維度更大幅領先榜單原 TOP1 286%。
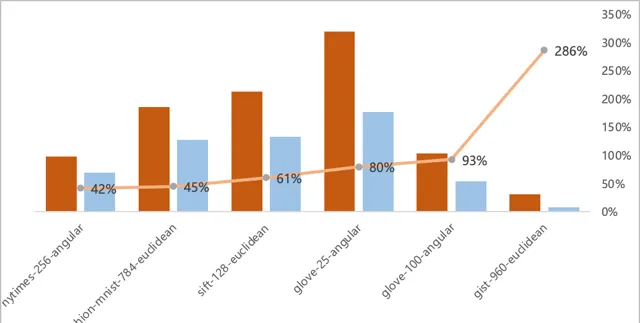
圖註:零一萬物笛卡爾向量資料庫與原榜單 TOP1 QPS 效能對比
笛卡爾向量資料庫背後的技術揭秘
RAG 是一種結合了檢索和生成的技術,它透過從海量數據中檢索查詢到的資訊,來增強語言模型的生成能力。和傳統檢索方法類似, 從本質上講,RAG 向量檢索主要解決兩大問題,分別是 透過建立某種索引結構,減少檢索考察的候選集;以及降低單個向量計算的復雜度。
針對針對第一個問題,零一萬物團隊采用兩大策略予以解決:
全導航圖技術。目前業內現狀主要透過哈希、KD-Tree、VP-Tree 等方式,導航效果不夠精確,裁剪力度不夠,零一萬物研發的全域多層縮圖導航技術,圖上座標系導航,既能保證精度,又能裁剪大量無關向量。
自適應鄰居選擇策略,填補業界空白。零一萬物自研的自適應鄰居選擇策略,突破了以往僅依賴真實 topk 或固定邊選擇策略的局限,新策略使每個節點可以根據自身及鄰居的分布特征動態地選取最佳鄰居邊,更快收斂接近目標向量,從而讓 RAG 向量檢索效能提高 15%-30%。
針對第二個問題,零一萬物采用了兩級量化方案增強 RAG。透過用兩級量化降低計算復雜度,同時列式儲存充分利用 SIMD 的並行能力,進一步發揮硬體能力,相比傳統 PQ 查表,效能得到大幅提升到 2-3 倍。
除此之外,還有索引結構最佳化、環通度保障等全棧向量技術方案提高笛卡爾向量資料庫的效能。
向量資料庫將成為決定大模型天花板的關鍵要素
零一萬物笛卡爾向量資料庫目前聚焦於高效能向量資料庫,在實際套用場景中具備精度更高、效能更強等核心優勢。高效能向量資料庫通常是指向量數據集規模在千萬級及以下(如 2000 萬 128 維浮點型向量),通常而言,高效能向量資料庫可以輕松應對百分之八九十的日常場景,比如幫助企業客戶構建私域知識庫、智慧客服系統;在自動駕駛領域,使用高效能向量資料庫可來加速自動駕駛模型訓練等。
以電商推薦場景為例,上架商品數量可能千萬級,每個商品可以由一個向量表達。即使庫中向量數不算很大,如果電商使用者基數非常龐大,高峰時每秒使用者請求數非常大,可能達到幾十萬甚至上百萬的 QPS。使用高效能向量資料庫可以有效提升電商場景裏面搜尋、廣告業務的推薦效果,讓大家忍不住一直買買買。
零一萬物表示,笛卡爾向量資料庫是團隊基於 RAG 的初步嘗試,將在近期釋出的 AI 生產力產品中得到有效套用。 未來各家大模型最佳化到一定程度後,向量資料庫的能力可能決定各家大模型的天花板。
推薦閱讀:












