【編者按】2024年3月5日,Stability AI 釋出了研究論文【Scaling Rectified Flow Transformers for High-Resolution Image Synthesis】,詳細地介紹了 Stable Diffusion 3 的底層技術。Stable Diffusion 3采用了與 Sora 相同的 DiT(Diffusion Transformer)架構,在排版和提示遵守方面表現優於 DALL·E 3、Midjourney v6 和 Ideogram v1等最先進的文本到影像生成系統。
原文連結:https://stability.ai/news/stable-diffusion-3-research-paper
整理 | 夢依丹
出品 | AI 科技大本營
繼 2 月份釋出 Stable Diffusion 3 預覽版之後, Stable Diffusion 官方團隊直接給出了這一版本背後的研究論文,跟大家分享技術細節。
Stable Diffusion 3 模型套件的參數範圍在 800M 和 8B 之間, 使用了分離權重集合的 多模態擴散變換器(MMDiT)架構, 相比之前的 SD3 版本,它改善了文本理解和拼寫能力。
基於人類偏好的評估結果顯示, Stable Diffusion 3 在 排版和提 示遵循方面要比 DALL·E 3、Midjourney v6 和 Ideogram v1 強大,在使用 50 個采樣步驟時,生成分辨率為 1024x1024 的影像需要 34 秒。

Prompt: A beautiful painting of flowing colors and styles forming the words "The SD3 research paper is here!"the background is speckled with drops and splashes of paint
效能
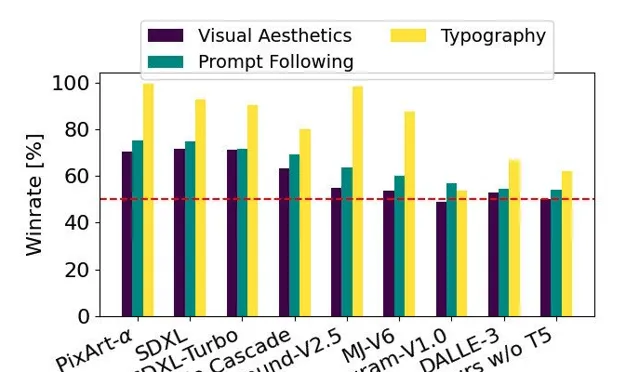
該圖表以 SD3 為基準,基於人類偏好評估,展示了 SD3 在視覺美學、提示遵循和排版等方面相對於其他競爭模型的優勢
他們將 Stable Diffusion 3 的輸出影像和其他開放模型, 包括 SDXL、SDXL Turbo、Stable Cascade、Playground v2.5 和 Pixart-α 以及閉源系統,如 DALL·E 3、Midjourney v6 和 Ideogram v1 進行 效能評估和 人類反饋,要求每位評估人員提供 每個模型的範例輸出,並要求他們根據模型輸出與給定提示內容的一致性程度("prompt following"),根據提示內容對文本的渲染效果("typography") 以及哪個影像具有更高的美學品質("visual aesthetics")來選擇最佳結果。
結果發現,Stable Diffusion 3 在與上述模型進行對比之後,要麽與當前最先進的文本到影像生成系統持平,要麽表現更好。
在早期未經最佳化的消費級硬體推理測試中, 擁有 80 億個參數的最大 SD3 模型適配 RTX 4090 的 24GB VRAM,使用 50 個采樣步驟生成 1024x1024 分辨率的影像需要 34 秒。 此外,Stable Diffusion 3 初步釋出時會有多個版本,包括 8 億到 80 億個參數的模型,以進一步消除硬體限制。

架構細節
在文本到影像生成中,模型需要同時考慮文本和影像兩種資訊。這種新架構稱為 MMDiT,意味著它可以處理多種不同的資訊。與之前的穩定擴散版本一樣,SD 3 團隊使用預訓練模型來獲取適當的文本和影像表示。具體來說,他們使用了三種不同的文本嵌入器 - 兩個 CLIP 模型和 T5 模型 - 來編碼文本資訊,並使用了改進的自編碼模型來編碼影像資訊。
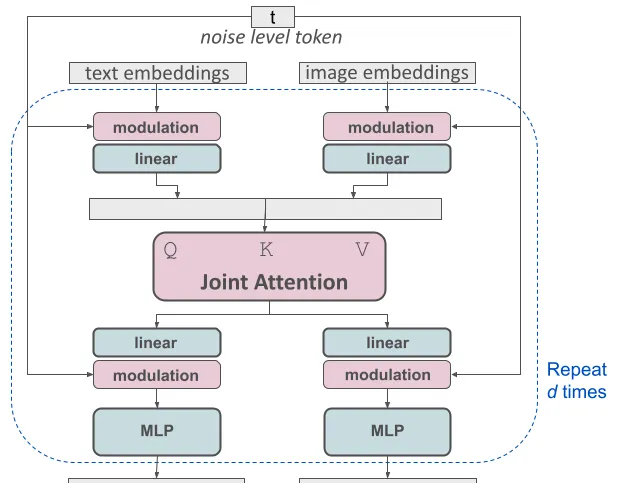
修改後的多模態擴散變壓器(MMDiT)的一個塊進行概念視覺化
SD3 架構建立在擴散變壓器("DiT",Peebles & Xie,2023年)的基礎上。由於文本和影像的嵌入概念上有很大的差異,他們為這兩種模態使用了兩套獨立的權重。如上圖所示,這相當於每個模態都有兩個獨立的變壓器,但在註意力操作中,他們將兩種模態的序列連線在一起,使得兩種表示可以在各自的空間中工作,同時考慮到對方的資訊。
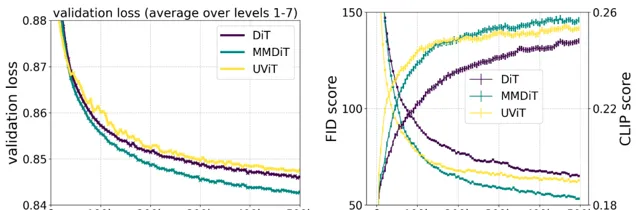
在訓練過程中,SD3 創新的 MMDiT 架構在視覺保真度和文本對齊度方面表現優於已有的文本到影像的骨幹架構,如 UViT(Hoogeboom 等,2023 年)和DiT(Peebles&Xie,2023年)。
透過采用這種方法,可以在影像和文本標記之間允許資訊的流動,以提高生成的輸出的整體理解度和排版效果。這種架構還可以輕松擴充套件到多種模態,例如視訊,我們在論文(https://arxiv.org/pdf/2403.03206.pdf)中進行了討論。

Stable Diffusion 3 提示跟隨功能的改進使得模型能夠創造出聚焦於不同主題和特征的影像, 並且在影像風格上保持高度的靈活性。

透過重新加權調整矯正流
Stable Diffusion 3 采用矯正流(Rectified Flow,RF)的思想(Liu等,2022年;Albergo & Vanden-Eijnden,2022年;Lipman等,2023年),在訓練過程中,數據和雜訊按照線性軌跡相互關聯。這種方法能夠獲得更加直接的推理路徑,從而減少采樣所需的步驟。同時,我SD 3 團隊還引入了一種新穎的軌跡采樣計劃。這個計劃更註重軌跡中間部份的采樣,因為他們認為這些部份對於預測任務更具挑戰性。他們透過與其他 60 種擴散軌跡(如 LDM、EDM 和 ADM)進行比較,使用了多個數據集、評估指標和采樣設定。
結果顯示,雖然之前的矯正流方法在少量采樣步驟時表現出改進的效能,但隨著步驟增加,效能相對下降。相反地,他們提出的重新加權矯正流方法在各種步驟下都能持續提升效能。
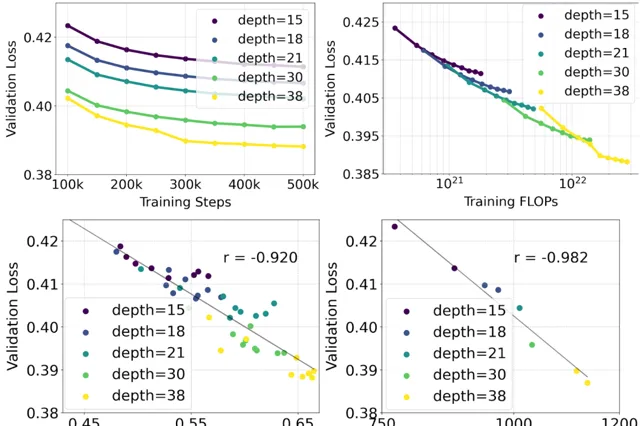
他們對采用重新加權的矯正流公式和 MMDiT 骨幹網路進行了文本到影像合成的規模化研究。他們訓練了不同規模的模型,從小到大,觀察到隨著模型大小和訓練步驟的增加,驗證損失逐漸減小(頂部行)。 為了測試這是否能夠帶來模型輸出的實質性改進,他 們還進行了自動影像對齊度量(GenEval)和人類偏好評分(ELO)的評估(底部行)。
研究結果顯示,這些評估指標與驗證損失之間存在明顯的相關性,驗證損失可以很好地預測模型的整體效能。 此外,還 發現模型的效能隨著規模的增加並未達到飽和狀態,這讓他們對未來能夠進一步提升模型效能持有積極的態度。
靈活的文本編碼器
他們 透過在推理過程中移除龐大的 4.7B 參數的 T5 文本編碼器,可以顯著減少 SD3 的記憶體需求,只會帶來輕微的效能損失。移除該文本編碼器不會影響視覺美感(無T5時的勝率:50%),僅會導致略微降低的文本一致性(勝率46%),如上圖所示的「效能」部份。然而,團隊建議在生成書面文本時使用T5,以充分發揮 SD3 的能力,因為他們觀察到在沒有 T5 的情況下排版生成的效能下降更為明顯(勝率 38%),如下面的範例所示。

僅在生成過程中移除 T5 會導致效能顯著下降,特別是在處理涉及許多細節或大量書面文本的復雜提示時。上圖展示了每個範例的三個隨機樣本。
要了解更多關於 MMDiT、矯正流(Rectified Flows)以及 Stable Diffusion 3 背後的研究,可以閱讀他們的完整論文:https://arxiv.org/pdf/2403.03206.pdf。
隨著 AI 大模型研究與套用領域地不斷擴充套件,越來越多的電腦人才加入這一浪潮變革之中。 由 CSDN 和 Boolan 打造的【基於大語言模型的套用開發】課程讓開發者深入理解大模型背後的核心技術,吃透其原理與套用,緊跟時代潮流。












