算力成本高昂、大模型參數越來越大、多模態模型讓推理成本再提高 2 個數量級、推理效率低、業務場景豐富但落地鏈路長等一系列現實問題,成為制約 AI 套用廣泛落地的關鍵因素。如何降低算力成本,迎接推理算力爆發時代的到來?剛剛結束的 上,王聞宇先生以【 如何做到算力基建和推理最佳化的「軟硬兼施」與創新突破 】為題,對 AI 推理成本高企的原因進行深度剖析,並給出兩個降低推理成本的有效方法。
作者 | 王聞宇
責編 | 王啟隆
出品丨AI 科技大本營(ID:rgznai100)

當前,AI 推理面臨的首要問題是高昂的成本:
以 GPT-4 當前的推理價格為例,如果我們做一個粗略的估算,假設日活躍使用者達到 10 億,每人每天使用 7,000 個token(包含上下文資訊),並且不考慮目前百萬級脫殼的費用,每天產生的費用將高達 2.1 億美金。 若按 365 天計算,年費用將達到驚人的 600 億美金。

GPT-4 推理價格估算 = 使用者數 x 每使用者生成 Token 數 x 單位 Token 推理價格 https://openai.com/pricing
這一數位相當於超過了 40 座世界第一高樓杜拜的哈里發塔(Burj Khalifa)的造價。更值得註意,這還只是今天的情況,還未考慮到多模態套用等更廣泛的普及場景,因此實際使用量可能遠超這一數位。
600 億美金的概念意味著,如果 AI 推理市場的體量再放大十倍,其規模將接近甚至超過當前整個雲端運算產業的總收入。這表明 AI 推理在未來市場的發展潛力巨大,遠遠超過現有的雲端運算產業。因此,從商業角度看,AI 推理無疑是一個具有巨大潛力和前景的市場。

AI 推理成本高昂的原因分析
挑戰 1:生產資料昂貴
導致 AI 推理成本高昂的原因有多種,其中生產資料成本是重要因素之一。例如, 某些頂級芯片制造商的產品毛利率超過了 70% 。
當然,成本不僅僅局限於 GPU, 電力消耗也是重要成本因素 ,特別是在電費較高的地區,電力成本可以顯著影響總體營運成本。
挑戰 2:LLM 參數還在越來越大
近年來,隨著技術的不斷進步, 大型模型的參數規模也在迅速擴張 。例如,今年 Mixtral 推出了具有 8*22 141B 參數的模型,Grok 釋出了擁有 341B 參數的模型。Llama3 也公開了 400B 參數的模型,而傳說中的 GPT-5 的參數規模更是將邁上新的台階,盡管具體數值尚未揭曉。 更大的模型意味著更高的計算需求,從而推高了推理成本 。
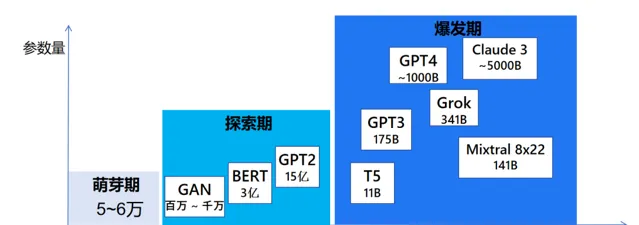
隨著多模態技術的發展,尤其是音視訊數據的處理,進一步增加了推理的復雜度 。雖然據說 Sora 只有 10B 的參數量(沒有得到官方的證明),但是音視訊的生成具有長序列特性(對比 LLM 的 Token 數量大得多得多), 這種長序列特性會使得計算量和視訊記憶體會大大增加,這最終也會使得推理成本的增長更是呈現指數級上升的趨勢。
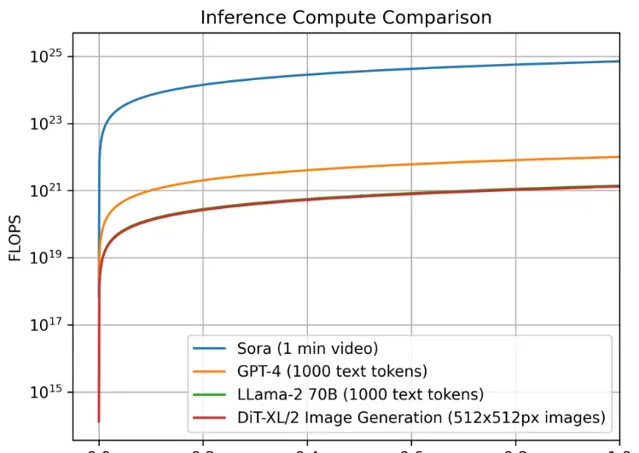
挑戰 3:推理效率低
大模型系統的推理效率低下是行業普遍存在的問題,這主要是由於演算法和硬體兩方面原因導致的。
首先在演算法層面,由於大模型自回歸推理的特性,計算量隨著文本生成長度平方增長,意味著生成的文本序列越長,推理的速度越慢。
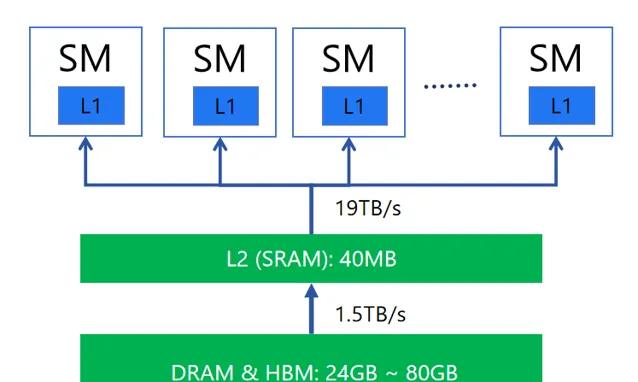
其次經典的 GPU 硬體架構需要在推理過程中頻繁進行數據傳輸和搬運,這會顯著限制推理效率 。比如在推理過程中,大量的資料通訊發生在各級緩存層之間,不僅消耗 GPU 的算力,而且系統需要花費大量時間等待數據的搬運工作完成。
挑戰 4:業務場景豐富,落地鏈路長
業務場景豐富和落地鏈路長會間接導致推理成本過高 。
當業務場景變得越來越多時,為了滿足各種復雜和多樣的需求,通常需要設計和訓練更為復雜和龐大的模型。這些模型往往需要更高的計算資源和儲存資源,導致推理過程中所需的計算成本增加。
落地鏈路長通常意味著從模型訓練到實際部署套用的過程中,需要經過多個階段和環節,包括數據預處理、模型訓練、模型最佳化、模型部署等。這些環節都可能涉及到計算和儲存資源的消耗,導致推理成本增加。
降低推理雲成本兩個有效思路
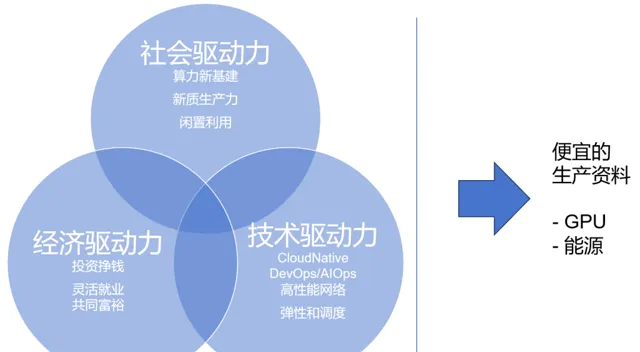
思路 1:分布式雲,充分動員市場,降低生產資料成本
分布式雲方面,充分動員市場的社會、經濟、技術三大驅動力,以獲得更便宜的生產資料,包括 GPU 卡與電力能源等。
以 GPU 為例,雖然高端 GPU 的價格昂貴,但是中低端 GPU/舊 GPU 便宜。我們可以透過分布式雲的方式,利用其強大的市場動員能力,將大量中低端 GPU 匯聚起來(如 RTX 4090 等),形成一個龐大的分布式 GPU 算力網路,從而降低算力成本。同時,透過合理的能源管理和排程,可以降低能源消耗和散熱成本,進一步降低推理成本。
傳統的大型數據中心雖然具備強大的處理能力,但其成本高昂,不僅包括硬體裝置的購置和維護,還包括能源的消耗和散熱的需求。分布式雲透過建立在全球各個位置小型數據中心或邊緣計算節點,充分利用各地的廉價能源和算力資源,降低整體成本。
思路 2:AI 推理加速,提效降本
雖然生產資料的成本是能透過分布雲的方式降低,但是下降空間都是有限的。其實降低推理成本,還有一個大殺器,用得好,其降本空間更大,這就是推理加速技術。
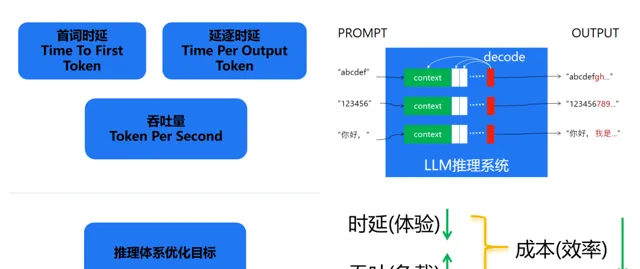
那麽什麽叫推理加速技術,拿 LLM 來舉例,我們重點關註以下三個指標:
Time To First Token (TTFT) : 首 Token 延遲,即從輸入到輸出第一個 token 的延遲。在線上的流式套用中,TTFT 是最重要的指標,因為它決定了使用者體驗。
Time Per Output Token (TPOT) : 每個輸出 token 的延遲(不含第一個Token)。在離線的批次處理套用中,TPOT 是最重要的指標,因為它決定了整個推理過程的時間。
Throughput :吞吐量,即每秒針對所有請求生成的 token 數。以上三個指標都針對單個請求,而吞吐量是針對所有並行請求的。

這是為了確保使用者能夠更快地獲得系統的反饋,從而提升使用者體驗。同時,我們還努力增加系統的吞吐量,這意味著系統能夠在單位時間內處理更多的數據,讓系統推理的效率更高。
降低時延和增加吞吐量不僅關乎使用者體驗,更直接關系到推理成本。最佳化後的系統能夠更高效地利用計算資源,如 CPU、GPU 和記憶體,從而降低單位推理任務的成本。這種成本降低不僅體現在硬體資源的消耗上,還體現在時間成本上,因為更高效的推理過程意味著更短的任務完成時間。
當同樣的 GPU,如果更短的時間能夠完成一個任務,就說明單位時間內能完成更多的任務,這樣單任務的時間變短了,生產資料不變,那就說明單任務的推理成本降低了(例如,之前 10s 生成一張圖片,現在 1s 生成一張圖片,相當於 10s 生成了 10 張圖片,也就時每張圖片的推理成本降低了 10 倍)。
推理加速的本質在於解決制約效能的三要素:視訊記憶體、算力和頻寬。
想象一下,如果有一塊固定的視訊記憶體,能不能像打理家務一樣精打細算,讓這塊視訊記憶體存下更多的東西? 這就是一個值得考慮的點。 同樣的,對於算力,我們是不是也能在執行時更精細地管理,讓更多的計算任務同時跑起來呢? 說到頻寬,其實它就像是數據在顯卡和其他儲存裝置之間傳遞的「道路」。 如果我們能想辦法減少數據在這條「道路」上的擁堵,比如降低通訊量,那也是一種最佳化的思路。
推理最佳化實踐:演算法、系統、硬體的協同創新
針對制約效能的視訊記憶體、算力和頻寬三要素,我們進行了諸多推理最佳化實踐, 形成了演算法、系統、硬體的協同創新,結合了一些最新的研究,探索了一些有效的方法。總體上可以分為演算法最佳化、統一推理框架以及硬體適配這三個層次的綜合最佳化。

無失真最佳化系列
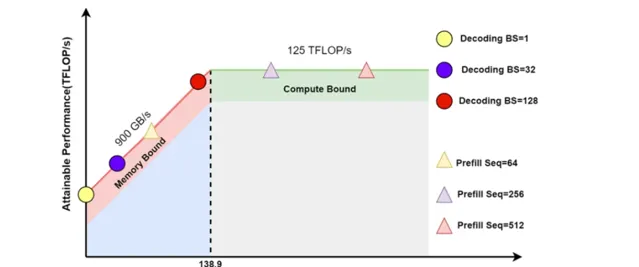
當前主流 LLM 基本都是 Decoder Only 的 Transformer 模型,其推理過程可以分為兩個階段。
Prefill:根據輸入 Tokens(I,like,natural,language) 生成第一個輸出 Token(Processing),透過一次 Forward 就可以完成,在 Forward 中,輸入 Tokens 間可以並列執行(類似 Bert 這些 Encoder 模型),因此執行效率很高,通常都會位於 Compute Bound 區域。
Decoding : 從生成第一個 Token(Processing) 之後開始,采用自回歸方式一次生成一個 Token,直到生成一個特殊的 Stop Token(或者滿足使用者的某個條件,比如超過特定長度) 才會結束,假設輸出總共有 N 個 Token,則 Decoding 階段需要執行 N-1 次 Forward,這 N-1 次 Forward 只能序列執行,效率很低,通常都會位於 Memory Bound 區域。
無失真最佳化的本質,從一定程度上講,是將 Memory Bound 轉化為 Compute Bound。
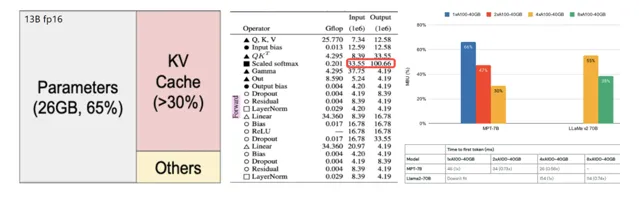
方法 1:算子融合,重點最佳化註意力計算和 KV-Cache
算子融合主要是針對 Transformer 模型中的兩大核心元件—— 註意力(Attention)機制 與前饋神經網路(FFN)進行最佳化,旨在顯著提升推理速度 。在此最佳化策略中,我們引入了一項被稱為「KV 緩存」(KV-Cache)的關鍵技術,該技術使得 AI 模型在執行期間無需頻繁多載數據,大振幅提升了執行效率。
具體而言,算子融合等同於將原本分離的運算步驟整合為單一的綜合性操作,從而規避了數據在各操作間傳輸的開銷,並允許這些操作直接在 GPU 的共享記憶體中高效執行。這一轉變有效減少了 GPU 與外部記憶體之間的數據交換需求,進而增強了整體處理效能。尤其在配備非高速 HBM 記憶體的高端顯卡如 RTX 4090 上,此類最佳化顯得尤為關鍵,因為這類硬體配置在沒有高速記憶體支持的情況下,更依賴於高效的記憶體使用策略。
在實施算子融合策略時, 我們側重於註意力計算及其伴隨的 KV-Cache。KV-Cache 的概念根植於 Attention 機制 ,該機制涉及 Query、 K ey 和 V alue 三個基本元素。其中,透過 Query 與 Key 的矩陣乘積並經由 Softmax 函式處理後,選擇相應的 Values 進行後續計算。鑒於在 Attention 計算過程中,Key 和 Value 會被反復存取,采用 KV-Cache 策略能夠保留這些中間結果,避免了重復載入的耗時操作,從而在每個計算周期內顯著增強了數據處理與傳輸的效率,這是 K V-Cache 技術的核心所在。
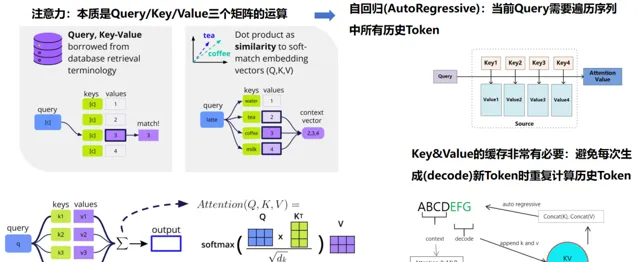
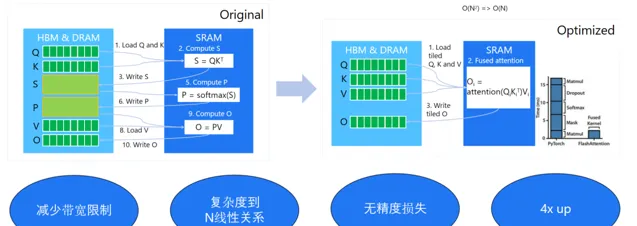
對於比 較耗時的註意力計算,其涉及多次矩陣場乘和 Softmax 計算,如果可以將這些算子融合為一個大算子,同時減少慢速片外視訊記憶體到高速的片上視訊記憶體的傳輸次數,則可以將復雜度從平方降低到線性,讓推理效率大幅提升,這是面向註意力計算的算子融合演算法的核心思想。
方法 2:以虛擬記憶體的方式管理視訊記憶體,減少視訊記憶體碎片,提升視訊記憶體使用效率
傳統的推理方案中,系統由於無法精確估算每個生成的序列需要多少視訊記憶體,非常簡單粗暴的按配額為每個序列預分配一大段儲存空間,這種做法一方面造成大量的視訊記憶體空間浪費,另一方面也限制了並行處理序列的最大數量。 因此,我們在推理過程中借鑒作業系統的「虛擬記憶體」概念,實作了動態視訊記憶體管理技術,把邏輯和實體記憶體分開,用一個指標的方式去對映。
當處理多個序列時,這種方式能更靈活地利用視訊記憶體碎片,讓視訊記憶體使用得更高效。 這就像是把一堆小碎片重新組合起來,變成有用的東西一樣。 總的來說,這些技術都是為了讓 AI 模型執行得更快、更高效。
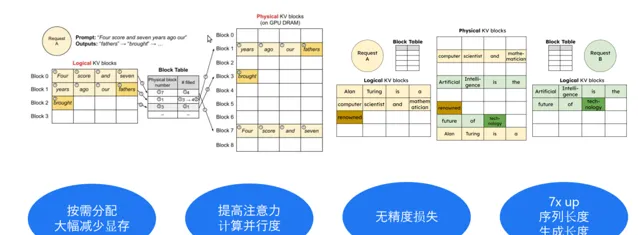
方法 3:Continuous Batching,減少無效視訊記憶體占用,提高視訊記憶體利用率
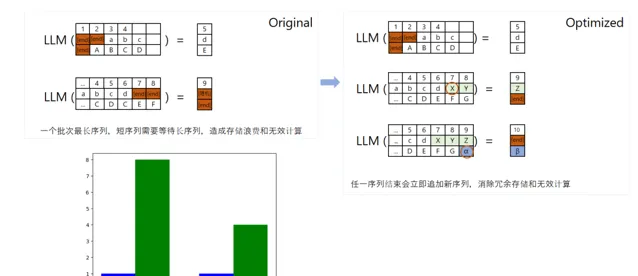
當我們進行模型訓練時,我們通常會分配一個固定的記憶體區域給模型。 但問題是,使用者輸入的數據長度可能各不相同。 有些人可能只輸入幾個字,而有些人可能會輸入一大段文字。 如果我們不進行最佳化,那麽當較短的輸入完成後,剩余的記憶體空間就會被浪費掉。
為 了解決這個問題,我們采用了「 Continuous Batching 」方案。 簡單來說,就是當一個輸入序列結束後,我們不會讓剩余的記憶體空間閑置,而是會接著填充下一個輸入序列的數據。 這樣一來,記憶體的使用就更加高效了。 但這個方法也有個缺點,那就是在處理序列對齊時可能會增加一些額外的開銷。 所以,是否使用這個方法,還需要根據具體的套用場景來決定。
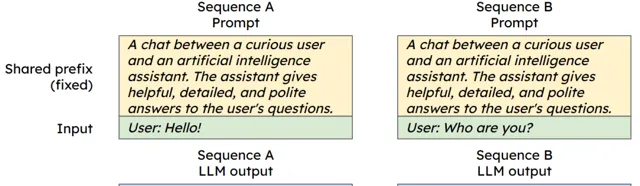
與此同時,我們創新了「 共享 Context 」概念,用以減少計算量和視訊記憶體開銷減少計算量和視訊記憶體開銷。 在實際套用中,很多時候使用者會使用相同的提示詞或問題來咨詢。
為了避免重復儲存這些相同的內容,我們可以將它們放在共享記憶體中。 這樣,當有多個使用者使用相同的提示詞時,我們就可以直接從共享記憶體中讀取,而不需要重復載入,從而節省了記憶體和計算資源。
以上這些方法都屬於基礎的推理加速技術,它們的特點是不會對模型本身造成任何損害。 但僅僅依靠這些無失真的最佳化方法,我們可能無法達到理想的加速效果。 所以,在實際套用中,我們還需要結合其他更高級的技術來進一步提升推理速度。
失真最佳化系列
我們在提升推理速度時,真正的挑戰並不在之前提到的無失真最佳化上,而是在接下來要講的失真最佳化上。 那麽,什麽是失真最佳化呢?
所謂失真最佳化是針對模型的結構特點,對模型進行壓縮,透過小型化減少推理過程中的計算負載和數據傳輸量,進而提高推理效率。 模型壓縮可能會導致輕微的精度損失,但這些損失是可控且可接受的,帶來的推理效率提升非常顯著, 本質 是用少量的精度損失換取更大的推理加速 。
方法 1:量化
首先,我們要理解 AI 模型中的浮點數。在 AI 模型中,浮點數是由符號位、指數位和小數位組成的。我們經常聽到的 FP32、FP16、FP8,其實就是在這些位數上做了不同的取舍。這些浮點數的位數越來越少,其實是 AI 硬體發展的一個趨勢。
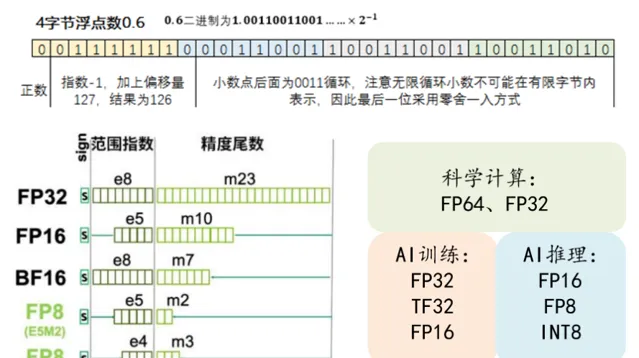
下面這個圖展示的是輝達最近幾代 GPU 的架構,從 Ampere 架構到今天的 Hoper/Ada Lovelace 和 Blackwell 架構,你可以看到它們的浮點運算能力在逐漸增強,從 FP16->FP8->FP6/FP4,為什麽要這麽做呢? 其實,這就是在進行能夠更好地做量化。

量化就是將模型本身浮點數型別(FP16)轉換成整數(INT8/INT4等)或者更低位數類(FP8 等)的方法,從而提高計算速度。
我們經常聽到的 INT8 量化就是這樣一種技術。 但是,INT8 量化的一個問題在於,它不能對所有的內容都進行量化。 對於一些復雜的操作, 如 SoftMax 操作,可能需要先還原到 FP16 或 FP32 再進行計算。
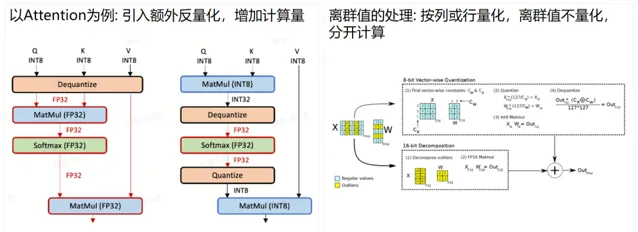
傳統的顯卡,包括一些國產顯卡,在量化時主要使用 INT8,並結合反復的量化和反量化來達到最終的效果。 但是,INT8 有一個問題,就是當有大量接近於零的數據時,它們可能會被直接清零,導致精度損失。
FP8 和 INT8 的值分布
而 FP8 則不同。 即使在數據接近於零的情況下,FP8 也能很好地保持精度,不會出現直接清零的情況。 這就是為什麽現在的 4090 顯卡以及 A100 等顯卡會成為大家的主力選擇。 它們能夠更好地支持 FP8 等低位數的浮點數運算,從而在保持精度的同時,提高計算速度。
FP8 和 INT 的量化對比
現在 A100 和 B100 等高效能計算平台之所以成為大家的主力,主要是因為它們支持全內容量化,特別是 FP8 全鏈路量化。 這種量化方式能在保持精度損失在可接受的 1% - 2% 範圍內,顯著提升計算速度,有時甚至能達到 4 倍以上的加速效果。 這種最佳化對於需要高效推理的 AI 套用來說,是極具吸重力的。
FP8:全鏈路量化,儲存和計算的全面提升
方法 2:稀疏化的硬體最佳化
除了全鏈路量化,稀疏化也是另一種重要的最佳化技術。 對 Transformer 來說,其註意力層的精確計算導致了序列長度二次的運算和記憶體復雜性,稀疏化可以理解為將矩陣中接近於零的值直接置為零,從而降低計算量。
其中,有一種叫做 HyperAttention 的方法,尋找對角矩陣 D , 一個矮胖矩陣 S, 將有價值的數據集中在斜對角線上,從而透過稀疏化計算實作約等於序列長度一次的運算和記憶體復雜性。
稀疏化的硬體最佳化
稀疏化加速
除了 HyperAttention 這種 attention 的近似方 法之外,啟用稀疏和 KV 緩存稀疏也是非常有效的最佳化方法,透過啟用稀疏的預測方法,可以將熱的神經元放入 GPU,冷的神經元放入 CPU,再透過即時預測的方法,動態計算當前輸入對應的熱神經元,不計算當前輸入的冷神經元,從而大大降低神經元的計算量。
稀疏化計算:權重稀疏,減少計算量
KV 緩存儲存的是歷史 token 列表,大模型的推理當中,實際只有少部份的熱 token 對最終的輸出起到決定作用,KV 緩存稀疏正是基於這門一種策略,透過計算不同 token 的累積貢獻度,刪除掉貢獻度最低的 token,從而降低 KV 的輸入長度,最終達到加速的目的。
稀疏化計算:KV Cache 稀疏,減少儲存,支持長視窗
在有限 長度的 KV Cache 中,驅逐與 Query 相關度低的 KV 值。 永久保留 KV Cache 中靠前的 KV 值, Decoding 時用較少的 KV 實作較長 KV 的效果。
總的來說,這些推理加速方案為我們提供了更多的選擇和可能性,讓我們能夠根據不同的套用場景和需求來客製最優的 AI 計算解決方案。
但這些原理聽起來簡單,但在實際套用中卻需要針對每個模型進行細致的分析和最佳化。 因為不同的模型對最佳化的敏感度和需求是不同的。 而且,在進行失真最佳化後,還需要透過評測工具來評估精度損失和效能提升之間的平衡。 只有當精度損失在可接受的範圍內,且效能提升顯 著時,這樣的最佳化方案才是有效的。
開發者正在迎接新一輪的技術浪潮變革。由 CSDN 和高端 IT 咨詢和教育平台 Boolan 聯合主辦的 2024 年度「全球軟體研發技術大會」秉承幹貨實料(案例)的內容原則,將於 7 月 4 日-5 日在北京正式舉辦。大會共設定了 12 個大會主題:大模型智慧套用開發、軟體開發智慧化、AI 與 ML 智慧運維、雲原生架構……詳情👉: http://sdcon.com.cn/











