unset unset Embedding介紹 unset unset
詞向量是 NLP 中的一種表示形式,其中詞匯表中的單詞或短語被對映到實數向量。它們用於捕獲高維空間中單詞之間的語意和句法相似性。
在詞嵌入的背景下,我們可以將單詞表示為高維空間中的向量,其中每個維度對應一個特定的特征,例如「生物」、「貓科動物」、「人類」、「性別」等。每個單詞在每個維度上都分配有一個數值,通常在 -1 到 1 之間,表示該詞與該特征的關聯程度。
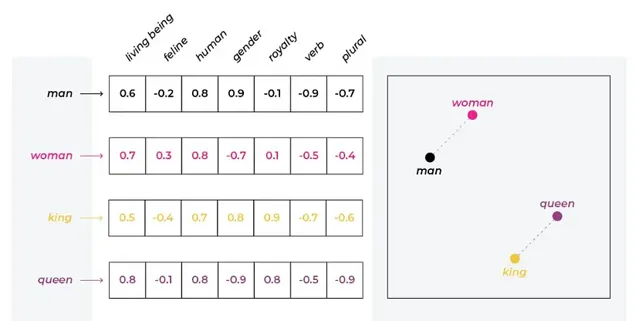
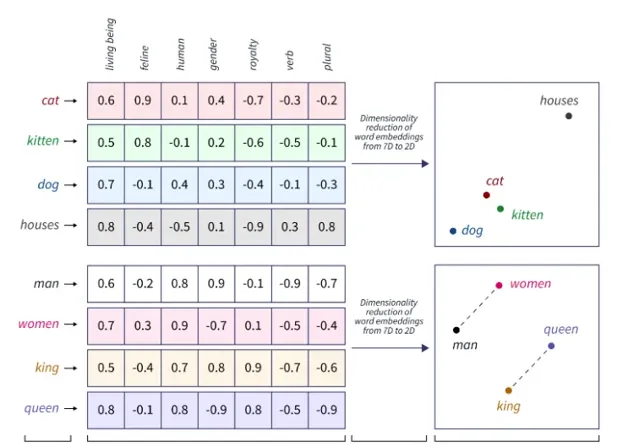
LangChain 可容納來自不同來源的多種嵌入。
unset unset OpenAI unset unset
import os
os.environ["OPENAI_API_KEY"] = "your-key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text = "Text"
text_embedding = embeddings.embed_query(text)
print(text_embedding)
"""
[-0.0006077770551231004,
-0.02036312831034526,
0.0015661947077772864,
-0.0008398058726938265,
0.00801365303172794,
0.01648443640533639,
-0.015071485112588635,
-0.006794635682304868,
-0.009232670381151012,
-0.004512441507728793,
0.00296615975583046,
0.02781575545470095,
-0.004290802116650396,
0.009204965399058554,
-0.007286398183123463,
0.01896402857732122,
0.03457576177203527,
0.01469746878566298,
0.03812199202928964,
-0.033024282774857694,
-0.014143370075136358,
-0.0016640276929606461,
-0.00023289462736494386,
-0.009856030615586264,
-0.018867061139997622,
...
-0.0007159994667987885,
-0.024920590413974295,
0.009017956769934473,
0.005336663327995613,
...]
"""
print(len(text_embedding))
"""
1536
"""
unset unset HuggingFace unset unset
from langchain_community.embeddings import HuggingFaceEmbeddings
embedding_path = r'H:\pretrained_models\bert\english\paraphrase-multilingual-mpnet-base-v2'
embeddings = HuggingFaceEmbeddings(model_name=embedding_path)
text = "This is a test document."
text_embedding = embeddings.embed_query(text)
print(len(text_embedding)) # 768
unset unset Google unset unset
from langchain_google_genai import GoogleGenerativeAIEmbeddings
os.environ["GOOGLE_API_KEY"] = "your-key"
embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001")
text_embedding = embeddings.embed_query("hello, world!")
print(text_embedding) # 768
更多Embedding可以檢視https://python.langchain.com/v0.2/docs/integrations/text_embedding/
unset unset 計算相似性 unset unset
我們可以使用嵌入來計算文本的相似度。
word_list = ["Cat", "Dog", "Car""Truck","Computer","Laptop","Apple","Orange", "Music","Dance"]
embedding_model = OpenAIEmbeddings()
embeds = [embedding_model.embed_query(word) for word in word_list]
embeds
"""
[[-0.008174207879591734,
-0.007511803310590743,
-0.00995655437174355,
-0.024788951157780095,
-0.012790553094547429,
0.006654775143594856,
-0.0015151649503578363,
-0.03783217392596492,
-0.014422662356334227,
-0.026250339680779597,
0.017154227704543168,
0.046327340706031526,
0.0035646922858117093,
0.004240754467349556,
-0.032287098019987186,
-0.004592443287070655,
0.03955306057962428,
0.005261676778755394,
0.00789422251521935,
-0.015501631209043845,
-0.023723641081760536,
0.0053197228543978925,
0.014873371253461594,
-0.012141805905252653,
-0.006781109980413554,
...
0.00566348496318421,
0.01855802589283819,
0.00531267762533671,
0.02393075147421956,
...]]
"""
我們引入另一個單詞並計算相似度。
input_word = "Lion"
input_embed = embedding_model.embed_query(input_word)
import numpy as np
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
similarity = cosine_similarity(embeds[0], input_embed)
print(similarity) #0.8400893968591456
from sklearn.metrics.pairwise import cosine_similarity
similarity = cosine_similarity(np.array([embeds[0]]), np.array([input_embed]))
print(similarity) #array([[0.8400894]])
sims = [cosine_similarity(np.array([emb]), np.array([input_embed])) for emb in embeds]
"""
[array([[0.8400894]]),
array([[0.80272758]]),
array([[0.79536215]]),
array([[0.81627175]]),
array([[0.82762581]]),
array([[0.81705796]]),
array([[0.82609729]]),
array([[0.78917449]]),
array([[0.79970112]])]
"""
考慮文本儲存在 CSV 檔中,我們計劃將其用作評估輸入相似性的參考。
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path='data.csv', csv_args={
'delimiter': ',',
'quotechar': '"',
'fieldnames': ['Words']
})
data = loader.load()
data
"""
[Document(page_content='Words: Words', metadata={'source': 'data.csv', 'row': 0}),
Document(page_content='Words: Cat', metadata={'source': 'data.csv', 'row': 1}),
Document(page_content='Words: Dog', metadata={'source': 'data.csv', 'row': 2}),
Document(page_content='Words: CarTruck', metadata={'source': 'data.csv', 'row': 3}),
Document(page_content='Words: Computer', metadata={'source': 'data.csv', 'row': 4}),
Document(page_content='Words: Laptop', metadata={'source': 'data.csv', 'row': 5}),
Document(page_content='Words: Apple', metadata={'source': 'data.csv', 'row': 6}),
Document(page_content='Words: Orange', metadata={'source': 'data.csv', 'row': 7}),
Document(page_content='Words: Music', metadata={'source': 'data.csv', 'row': 8}),
Document(page_content='Words: Dance', metadata={'source': 'data.csv', 'row': 9})]
"""
CSVLoader 類用於從 CSV 檔載入數據。我們將在系列後面介紹裝載機。我們可以利用FAISS結合LangChain來建立一個向量儲存。
embeddings = OpenAIEmbeddings()
from langchain_community.vectorstores import FAISS
db = FAISS.from_documents(data, embeddings)
user_input = "Lion"
results = db.similarity_search(user_input)
results
"""
[Document(page_content='Words: Cat', metadata={'source': 'data.csv', 'row': 1}),
Document(page_content='Words: Apple', metadata={'source': 'data.csv', 'row': 6}),
Document(page_content='Words: Dog', metadata={'source': 'data.csv', 'row': 2}),
Document(page_content='Words: Orange', metadata={'source': 'data.csv', 'row': 7})]
"""










