向量儲存是一種專門用於儲存和管理向量嵌入的資料庫。
向量儲存旨在高效處理大量向量,提供根據特定標準添加、查詢和檢索向量的功能。它可用於支持語意搜尋等應用程式,在這些應用程式中,您可以尋找與給定查詢在語意上相似的文本段落或文件。
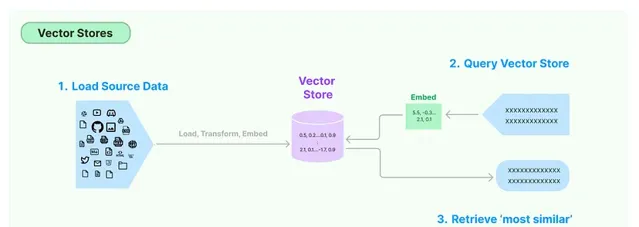
內容和含義相似的文本會具有相似的向量,也就是說,它們在嵌入空間中的向量之間的距離會很小。
例如,「貓在沙發上睡覺」和「小貓在沙發上打盹」這兩個句子的單詞不同,但含義相似。它們的嵌入向量在嵌入空間中彼此接近,反映了它們的語意相似性。嵌入向量的這一特性對於各種自然語言處理任務至關重要,例如語意搜尋、文本聚類和機器轉譯,在這些任務中,理解文本的含義至關重要。
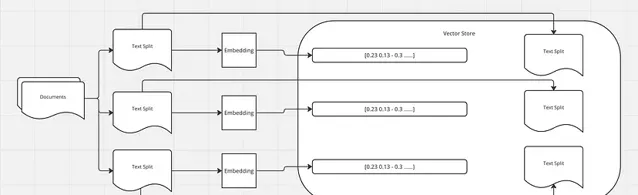
如前所述,我們使用文件載入器載入文件,然後使用文件轉換器將文本分成塊。接下來,我們為每個塊生成嵌入,並將這些嵌入及其相應的拆分儲存在向量儲存中。
將查詢轉換為嵌入後,向量儲存會根據相似度度量(例如余弦相似度)搜尋最相似的向量(即最相似的文本)。然後檢索與這些相似向量相對應的文本作為查詢結果。
在 Langchain 工作流中,這些檢索到的文本可以進一步處理,方法是將它們與原始查詢一起傳遞給大型語言模型 (LLM) 進行進一步分析或處理。例如,LLM 可以根據查詢和檢索到的文本生成響應,或者可以執行一些需要理解類似文本提供的上下文的任務。Langchain 中存在不同的向量儲存實作,每種實作都針對不同的用例和儲存要求進行了最佳化。一些向量儲存可能使用記憶體儲存以實作快速存取,而另一些向量儲存可能使用基於磁盤的儲存以實作可延伸性。完整列表:
https://python.langchain.com/v0.2/docs/integrations/vectorstores/
import os
os.environ["OPENAI_API_KEY"] = "your-key"
from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
embeddings = OpenAIEmbeddings()
llm_model = "gpt-4"
llm = ChatOpenAI(temperature=0.0, model=llm_model)
loader = PyPDFLoader("book.pdf")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500,
chunk_overlap = 150
)
text_splits = text_splitter.split_documents(docs)
print(len(text_splits))
# 6
OpenAIEmbeddings
是為了生成嵌入而建立的,並且 的例項
ChatOpenAI
是為了與
GPT-4
模型互動而建立的。
PyPDFLoader
從名為「book.pdf」的
PDF
檔中載入文本。載入的文本儲存在變量中docs。
RecursiveCharacterTextSplitter
將載入的文本拆分為較小的塊,每個塊的最大大小為
1500
個字元,連續塊之間有
150
個字元的重疊。該
split_documents
方法用於執行拆分,並將生成的文本塊列表儲存在 中
text_splits
。
unset unset Chroma unset unset
Chroma是一個開源向量資料庫,專為高效儲存和查詢向量嵌入而設計。它與 Langchain 整合良好,使其成為在該環境中使用嵌入的開發人員的熱門選擇。
pip install chromadb
Chroma 優先考慮開發人員的易用性。它提供了一個簡單的 API,其中包含添加、獲取、更新和刪除等常見資料庫操作,以及基於相似性的查詢功能。
from langchain.vectorstores import Chroma
persist_directory = "./data/db/chroma"
vectorstore = Chroma.from_documents(
documents=text_splits,
embedding=embeddings,
persist_directory=persist_directory
)
print(vectorstore._collection.count()) # 6
persist_directory
是
Chroma
將持久儲存其數據的路徑。這可確保即使應用程式終止後數據仍然可用。
該
from_documents
方法采用以下參數:
documents
:要儲存在向量儲存中的文本文件(或文本拆分)列表。在本例中,
text_splits
假定為先前從較大文件中拆分出來的文本塊列表。
embeddingOpenAIEmbeddings
:用於為文件生成嵌入的嵌入模型。這應該是可以從文本(例如對話中較早的文本)生成嵌入的類的例項。
persist_directory
:向量儲存將在磁盤上保存其數據的目錄。這設定為
persist_directory
先前定義的變量。
query = "what is the purpose of the book?"
docs_resp = vectorstore.similarity_search(query=query, k=3)
print(len(docs_resp))
print(docs_resp[0].page_content)
vectorstore.persist()
"""
Our goal with this book is to provide the guidance and framework for you, the reader, to grow on
the path to being a truly excellent database reliability engineer (DBRE). When naming the book we
chose to use the words reliability engineer , rather than administrator.
Ben Treynor, VP of Engineering at Google, says the following about reliability engi‐ neering:
fundamentally doing work that has historically been done by an operations tea...
"""
該查詢將用於在向量儲存中搜尋類似的文件。
該
similarity_search
方法采用以下參數:
query
:用於搜尋類似文件的文本查詢。
k
:要檢索的最相似文件的數量。在本例中,
k=3
表示將返回前
3
個最相似的文件。結果,
docs_resp
是與查詢最相似的文件列表。
persist
方法使用建立向量儲存時指定的當前狀態保存到vectorstore磁盤的persist_directory`
unset unset Faiss unset unset
FAISS 是Facebook AI Similarity Search的縮寫,是 Facebook 開發的一款功能強大的開源庫,用於對高維向量進行高效的相似性搜尋。
from langchain_community.vectorstores import FAISS
db = FAISS.from_documents(text_splits, embeddings)
print(db.index.ntotal) # 6
docs = db.similarity_search(query)
print(docs[0].page_content)
"""
Our goal with this book is to provide the guidance and framework for you, the reader, to grow on
the path to being a truly excellent database reliability engineer (DBRE). When naming the book we
chose to use the words reliability engineer , rather than administrator.
Ben Treynor, VP of Engineering at Google, says the following about reliability engi‐ neering:
fundamentally doing work that has historically been done by an operations team, but using engineers with software
expertise, and banking on the fact that these engineers are inherently both predisposed to, and have the ability to,
substitute automation for human labor.
...
"""
db.save_local("faiss_index")
可以載入Embedding模型構建Faiss
from langchain_huggingface import HuggingFaceEmbeddings
# from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores.faiss import FAISS
from langchain_core.documents import Document
documents = [
Document(
meta_data={'text': 'PC'},
page_content='個人電腦',
),
Document(
meta_data={'text': 'doctor'},
page_content='醫生辦公室',
)
]
embedding_path = r'H:\pretrained_models\bert\english\paraphrase-multilingual-mpnet-base-v2'
embedding_model = HuggingFaceEmbeddings(model_name=embedding_path)
db = FAISS.from_documents(documents, embedding=embedding_model)
db.save_local('../.cache/faiss.index')
db = FAISS.load_local('../.cache/faiss.index', embeddings=embedding_model, index_name='index',allow_dangerous_deserialization=True)
docs = db.similarity_search_with_score('桌上型電腦電腦')
print(docs)










