
點選上方↑↑↑「OpenCV學堂」關註我
來源:公眾號 新智元授權
【導讀】 僅需一張照片加一段音訊,即可生成具有精確唇音同步、逼真面部行為和自然頭部運動的超逼真說話面部視訊,並且生成速度快,512×512分辨率下,生成速率可達40幀,啟動延遲可忽略不計。
在人物說話的過程中,每一個細微的動作和表情都可以表達情感,都能向觀眾傳達出無聲的資訊,也是影響生成結果真實性的關鍵因素。
如果能夠根據特定面容來自動生成一段生動逼真的形象,將徹底改變人類與人工智慧系統的互動形式,例如改善有障礙患者的交流方式、增強人工智慧輔導教育的趣味性、醫療保健場景下的治療支持和社會互動等。
最近,微軟
亞洲研究院的研究人員丟擲了一個重磅炸彈VASA-1框架,利用
視覺情感技巧(VAS,visual affective skills)
,只需要輸入
一張肖像照片+一段語音音訊
,即可生成
具有精確唇音同步、逼真面部行為和自然頭部運動的超逼真說話面部視訊。

論文連結:https://arxiv.org/pdf/2404.10667.pdf
計畫主頁:https://www.microsoft.com/en-us/research/project/vasa-1/
下面為一分鐘視訊演示。
在VASA框架下,首款模型VASA-1不僅能夠產生與音訊完美同步的嘴唇動作,還能夠捕捉大量面部細微差別和自然的頭部動作,有助於感知真實性和生動性。
框架的核心創新點為基於擴散的整體面部動力學和頭部運動生成模型,以及使用視訊來開發出這種富有表現力和解耦的面部潛空間(disentangled face latent space)。
研究人員還使用了一組全新的指標對模型能力進行評估,結果表明該方法在各個維度上都顯著優於之前的方法,可以提供具有逼真面部和頭部動態的高品質視訊,還支持以高達40 FPS的幀速率即時生成512×512視訊,啟動延遲可忽略不計。
可以說,VASA框架為模擬人類對話行為中,使用逼真化身進行即時互動鋪平了道路。
VASA框架
一個好的生成視訊應該具備幾個關鍵點:高保真度、影像幀的解析度和真實性、音訊和嘴唇動作之間的精確同步、表情和情感的面部動態,以及自然的頭部姿勢。

模型在生成過程可以接受一組可選的控制訊號來指導生成,包括主眼凝視方向、頭部到相機的距離和情緒偏移等。
整體框架
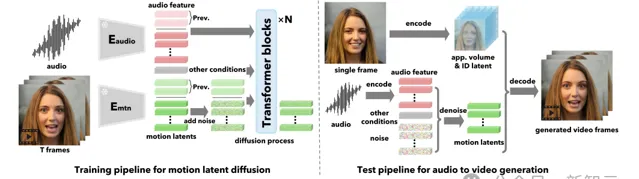
VASA模型並不是直接生成視訊幀,而是在音訊和其他訊號的條件下,在潛空間中生成整體的面部動態和頭部運動。
給定運動潛碼後,VASA使用面部編碼器從輸入影像中提取的外觀和身份特征作為輸入,然後生成視訊幀。
研究人員首先構建了一個人臉潛空間,並使用現實生活中的人臉視訊對人臉編碼器和解碼器進行訓練;然後再訓練一個簡單的擴散Transformer對運動分布進行建模,針對測試期間的音訊和其他條件下,生成運動潛碼。
1. 表情和解耦面部潛空間構建(Expressive and Disentangled Face Latent Space Construction)
給定一組未標註的說話人臉視訊,研究人員的目標是建立一個具有高度解耦和表現力的人臉潛空間。
在主體身份改變的情況下,解耦可以對視訊中的人臉和整體面部行為進行高效的生成建模,還可以實作對輸出的解耦因子控制,相比之下,現有方法要麽缺乏表現力,要麽缺乏解耦。
另一方面,面部外觀和動態運動的表情可以確保解碼器能夠輸出具有豐富面部細節的高品質視訊,潛生成器能夠捕捉細微的面部動態。
為了實作這一點,VASA模型建立在3D輔助人臉再現(3D-aid face reenactment)框架的基礎上,與2D特征圖相比,3D外觀特征體積可以更好地表征3D中的外觀細節,其在建模3D頭部和面部運動方面也很強大。
具體來說,研究人員將面部影像分解為規範的3D外觀體積、身份編碼、3D頭部姿勢和面部動態編碼,每個特征都由獨立的編碼器從人臉影像中進行提取,其中外觀體積需要先透過提取姿勢三維體積,再將剛性和非剛性三維扭曲到規範體積來構建得到。
解碼器將上述潛變量作為輸入,並重建面部影像。
學習解耦潛空間的核心思想是,透過在視訊中不同影像之間交換潛變量來構建影像重建損失,但原版模型中的損失函式無法很好地區分「面部動態」和「頭部姿勢」,也無法辨識「身體」和「運動」之間的關聯性。
研究人員額外添加了成對的頭部姿勢和面部動態來傳遞損失,以改善解耦效果。
為了提升身份和運動之間的纏結,損失函式中引入了面部身份相似性損失。
2. 基於擴散Transformer的整體人臉動態生成(Holistic Facial Dynamics Generation with Diffusion Transformer)
給定構建的人臉潛空間和訓練的編碼器,就可以從現實生活中的人臉視訊中提取人臉動態和頭部運動,並訓練生成模型。
最關鍵的是,研究人員考慮了身份不可知的整體面部動態生成(HFDG),學習到的潛編碼代表所有面部運動,如嘴唇運動、(非嘴唇)表情、眼睛凝視和眨眼,與現有方法中「使用交錯回歸和生成公式對不同因素套用單獨的模型」形成了鮮明的對比。
此外,之前的方法通常基於有限的身份進行訓練,不能對不同人類的廣泛運動模式進行建模,特別是在具有表現力的運動潛空間的情況下。
在這項工作中,研究人員利用音訊條件下的HFDG的擴散模型,在來自大量身份的大量談話人臉視訊上進行訓練,並將Transformer架構套用於序列生成任務。
3. Talking Face視訊生成
在推斷時,給定任意的人臉影像和音訊片段,首先使用訓練的人臉編碼器提取3D外觀體積和身份編碼;然後提取音訊特征,將其分割成相同長度的片段,並使用訓練的擴散Transformer以滑動視窗的方式逐個生成頭部和面部運動序列;最後使用訓練後的解碼器生成最終視訊。
實驗結果
研究人員使用公開的VoxCeleb2數據集,包含大約6000名受試者的談話面部視訊,並重新處理數據集並丟棄「包含多個人物的片段」和低品質的片段。
對於motion latent生成任務,使用embedding尺寸為512、頭編號為8的8層Transformer編碼器作為擴散網路。
模型在VoxCeleb2和收集的另一個高分辨率談話視訊數據集上進行訓練,該數據集包含約3500個受試者。
定性評估
視覺化結果
透過視覺檢查,我們的方法可以生成具有生動面部情緒的高品質視訊幀。此外,它可以產生類似人類的對話行為,包括在演講和沈思過程中眼睛凝視的偶爾變化,以及眨眼的自然和可變節奏,以及其他細微差別。我們強烈建議讀者線上檢視我們的視訊結果,以充分了解我們方法的功能和輸出品質。
生成可控性
在不同控制訊號下生成的結果,包括主眼凝視、頭部距離和情緒偏移,生成模型可以很好地解釋這些訊號,並產生與這些特定參數密切相關的人臉結果。

解耦face latents
當將相同的運動潛在序列套用於不同的受試者時,方法有效地保持了不同的面部運動和獨特的面部特征,表明了該方法在解耦身份和運動方面的有效性。

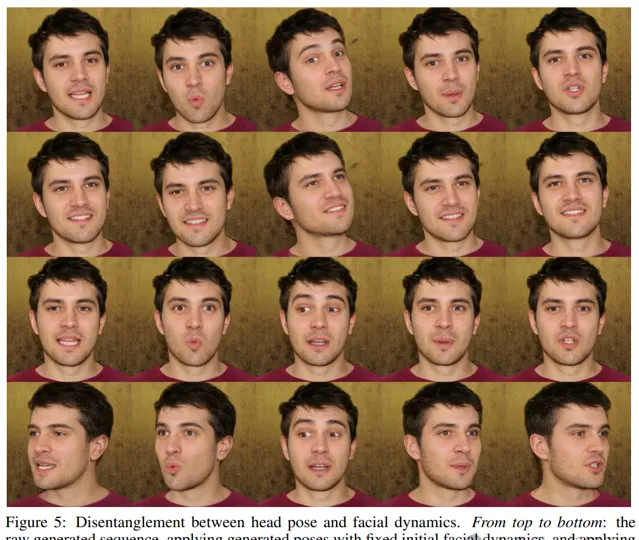
下圖進一步說明了頭部姿勢和面部動態之間的有效解耦,透過保持一個方面不變並改變另一個方面,得到的影像忠實地反映了預期的頭部和面部運動,而不會受到幹擾,展示了處理訓練分布之外的照片和音訊輸入的能力。
模型還可以處理藝術照片、歌唱音訊片段(前兩行)和非英語演講(最後一行),並且這些數據變體不存在於訓練數據集中。

定量評估
下表給出了VoxCeleb2和OneMin-32基準測試的結果。

在這兩個基準測試中,該方法在所有評估指標上都取得了所有方法中最好的結果。
在音訊嘴唇同步分數(SC和SD)方面,該方法遠遠優於其他方法,比真實視訊產生更好的分數,是由於音訊CFG的影響。
從CAPP分數上反映的結果來看,模型生成的姿勢與音訊的匹配效果更一致,尤其是在OneMin-32基準上。
根據∆P,頭部運動也表現出最高的強度,但仍然與真實視訊的強度仍有差距;並且FVD得分明顯低於其他模型,表明該結果具有更高的視訊品質和真實性。
參考資料:
https://arxiv.org/pdf/2404.10667.pdf












