點選上方 藍字 關註我們
微信公眾號: OpenCV學堂
關註獲取更多電腦視覺 與深度學習知識
前言
在計算成像和電腦視覺領域,影像變形(IMAGE warping)至關重要,它是眾多套用的基礎,包括影像校正、影像矩形化、相機標定以及三維重建等。透過縮放、旋轉和傾斜等過程對影像數據進行操作,可以實作不同視覺元素的無縫整合以及光學缺陷的校正。此外,在開發增強現實(AR)和虛擬現實(VR)套用時,影像變形也是不可或缺的,它有助於透過將紋理和影像精確對映到3D模型上,從而建立出沈浸式且逼真的環境。
MOWA
我們提出了一種名為 MOWA(Multiple-in-One影像變形模型)的模型 ,以解決實踐中的各種任務,如圖1所示。具體來說,我們考慮了計算攝影領域的六種代表性型別,即拼接影像、校正的廣角影像、去卷簾影像、旋轉影像、魚眼影像和人像照片,這些型別涵蓋了主流的實際影像變形任務。

MOWA模型結構
MOWA模型貢獻主要有以下三點,分別是:
• 作者提出了MOWA,這是第一個實用的多合一影像變形框架。盡管該模型的規模適中,但它仍明顯優於大多數最先進的方法。
• 我們提出透過解耦區域級和像素級的運動估計來緩解多工學習的難度。此外,我們還設計了一個由輕量級基於點的分類器引導的快速學習模組,以促進任務感知的影像變形。
• 我們展示了透過多工學習,我們的框架發展出了一種魯棒的通用變形策略,該策略在各種任務上均表現出色,甚至能夠泛化到未見過的任務上。
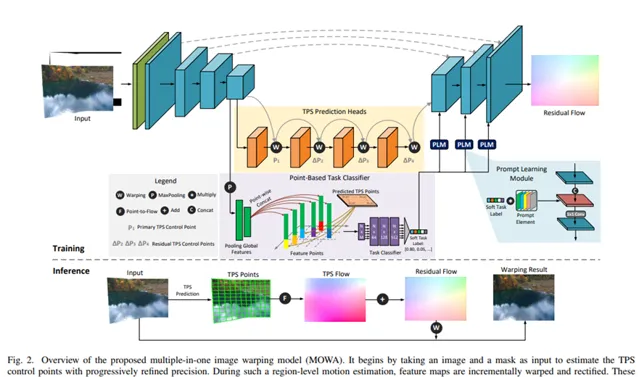
模型基於編碼器-解碼器架構設計,實作了區域級控制點回歸和像素級殘余流預測。具體來說,在編碼器和解碼器中(除了輸入投影層和輸出投影層外),都使用了帶有移動視窗的Transformer塊。編碼器網路中通道的基本維度設定為32,並隨著層數的增加而線性增加,而在解碼器網路中則相反,逐漸減少到2。此外,每個Transformer塊的深度設定為2,多頭自註意力機制的頭數在整個層中設定為[1, 2, 4, 8, 16, 16, 8, 4, 2]。在TPS預測頭中,我們采用具有不同摺積核的摺積層來預測逐漸增加數量的控制點,數量分別設定為10×10、12×12、14×14和16×16。這些回歸頭的配置細節列於表I中。與全連線層相比,這種設計顯著減少了參數。對於輕量級的基於點的分類器,我們使用了三個通道維度分別為256、256、512的1D摺積層來提取輸入特征,然後使用三個單元數分別為512、256、6的全連線層來分類任務型別。

它接收影像和掩碼作為輸入,並估計出數量逐漸增加的TPS(薄板樣條變換)控制點。在這種區域級運動估計中,特征圖逐漸被扭曲和校正。隨後,將扭曲後的特征輸入到解碼器中,以預測像素級的殘余運動。為了實作任務感知和可延伸的能力,我們設計了一個輕量級的基於點的分類器和即時學習模組。

程式碼與使用
作者已經開原始碼,參見這裏:
https://github.com/KangLiao929/MOWA
論文地址
https://arxiv.org/pdf/2404.10716
C++ 推理
https://github.com/hpc203/MOWA-onnxrun
OpenCV4系統化學習

深度學習系統化學習

推薦閱讀












