點選上方
藍字
關註我們
微信公眾號: OpenCV學堂
關註獲取更多電腦視覺與深度學習知識
深度學習的優勢
自動化程度高:
深度學習演算法能夠自動從大量數據中學習特征,無需人工設計復雜的特征提取規則,從而實作自動化檢測。
檢測精度高:
透過深度神經網路強大的特征提取和分類能力,深度學習能夠準確辨識出產品表面的微小缺陷。
適應力強:
深度學習模型可以針對不同的工業場景和缺陷型別進行訓練和最佳化,具有很強的適應力。
即時性強:
基於深度學習的缺陷檢測系統可以實作即時檢測,滿足生產線對檢測速度的需求。
套用場景
泛半導體和光伏領域:
深度學習演算法被用於檢測芯片、太陽能電池板等產品的表面缺陷,如劃痕、汙漬、裂紋等。
工業視覺檢測:
在工業生產線上,深度學習演算法被用於檢測各種產品的缺陷,包括零件裝配完整性、裝配尺寸精度、位置/角度測量等。
食品檢測:
如食品與包裝的缺陷檢測,深度學習技術可以有效地在復雜影像中找到缺陷位置,提高食品品質和安全性。
醫療器械:
醫療器械生成過程中的產品缺陷檢測、藥片形狀、包裝缺陷檢測。
常用模型與框架
01
Anomalib異常檢測框架
Anomalib 是一個功能強大的深度學習庫,為工業缺陷檢測等場景提供了高效、精確的解決方案。透過利用無監督異常檢測演算法和先進的深度學習技術,Anomalib 能夠幫助企業在提高產品品質、降低生產成本方面取得顯著成效。

Anomalib 包含了多種異常檢測演算法,如 STFPM、PaDiM、PatchCore、EfficientAD 等 。這些演算法在神經網路結構、特征編碼器、自動編碼器、多層特征混合計算、損失評估演算法等方面各有特點。例如,STFPM 模型采用了一種基於特征比對的方法來檢測異常影像,而 PatchCore 模型則透過構建一個包含正常樣本特征的記憶體庫來辨識異常樣本。

Anomalib 在缺陷檢測中的套用優勢
無需大量標註數據:無監督異常檢測在訓練階段完全依賴正常樣本,因此不需要大量的標註數據,這在許多實際工業場景中是非常有利的。 高效且精確:Anomalib 提供的演算法能夠高效地檢測出影像中的異常區域,並且具有較高的精確度,有助於提升工業生產的品質控制水平。 易於部署: Anomalib 支持將模型匯出到多種格式,如 OpenVINO™,從而便於在多種硬體平台上進行快速部署和推理。
02
例項分割網路模型
例項分割在工業缺陷檢測中的套用越來越廣泛,它結合了目標檢測和語意分割的優點,能夠精確辨識並分割出影像中的缺陷區域。
例項分割(Instance Segmentation)是電腦視覺領域的一項技術,它要求在影像中同時辨識出不同類別的物體,並對每個物體進行像素級的分割。
與語意分割不同,例項分割能夠區分同一類別的不同個體。
例項分割演算法的的優勢

缺陷辨識與定位:
例項分割能夠精確辨識出工業產品表面的各種缺陷,如裂紋、劃痕、凹坑等。 透過像素級的分割,可以準確標出缺陷的位置和形狀,為後續的處理和分析提供基礎。
提高檢測精度:
相比於傳統的基於灰度閾值、邊緣檢測等方法的缺陷檢測,例項分割具有更高的精度和魯棒性。 它能夠處理復雜背景下的缺陷檢測問題,並有效區分缺陷與正常區域。
目前,大多數例項分割技術都是基於深度學習模型實作的,如Mask R-CNN、YOLOv8-seg等。這些模型透過訓練大量的缺陷影像數據,能夠學習到缺陷的特征表示和分割方法。
03
Vit網路模型
基於Vision Transformer(ViT)網路的工業缺陷檢測是近年來深度學習領域的一個重要套用方向。ViT網路以其獨特的自註意力機制,在影像分類、目標檢測、語意分割等視覺任務中展現出了強大的效能,為工業缺陷檢測提供了新的解決方案。Vit網路實作工業缺陷檢測優勢
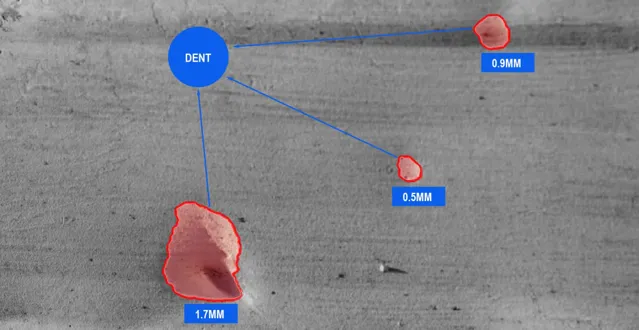
全域資訊捕捉能力強:
ViT透過自註意力機制,能夠在處理影像時捕捉到全域範圍內的資訊,這對於辨識工業產品表面的微小缺陷尤為重要。相比傳統的摺積神經網路(CNN),ViT更擅長於建模影像中的長距離依賴關系。
靈活性高:
ViT網路結構相對靈活,可以根據不同的任務需求進行調整和最佳化。例如,可以透過改變Transformer的層數、嵌入維度等參數來適應不同的數據集和檢測任務.
預訓練模型可用:隨著ViT在影像分類等任務上的廣泛套用,已經有許多預訓練的ViT模型可供使用。這些預訓練模型包含了豐富的視覺知識,透過微調可以快速地適應到工業缺陷檢測任務中。
在PCB(印刷電路板)缺陷檢測中,RT-DETR等基於ViT的即時目標檢測框架被證明具有較高的精度和速度。
04
SAM網路模型
目前,關於SAM直接套用於工業缺陷檢測的具體案例可能相對較少,但可以參考類似技術在工業領域的套用。例如,一些基於深度學習的影像分割方法已經被成功套用於工業產品表面的缺陷檢測中,如裂紋檢測、劃痕檢測等。這些方法透過構建深度學習模型,對工業產品影像進行特征提取和分類,從而實作缺陷的自動辨識和分割。

SAM是一種基於Vision Transformer(ViT)的影像分割模型,由Meta AI開發並釋出。該模型能夠透過互動式點選等操作實作影像物體的分割,並且具有模糊感知能力,能夠解決分割過程中產生的歧義問題。SAM在零樣本學習表現上成績優秀,使得其能夠套用於多種下遊任務中。
SAM在工業缺陷檢測中的優勢
高效性: SAM模型能夠快速對影像中的缺陷進行分割,提高檢測效率。
準確性: 透過深度學習訓練,SAM能夠學習到缺陷的特征表示,從而準確辨識並分割出缺陷區域。
靈活性: SAM模型可以針對不同的工業場景和缺陷型別進行訓練和最佳化,具有很強的適應力。
SAM在工業缺陷檢測中的套用挑戰
復雜場景: 工業缺陷檢測場景通常較為復雜,涉及多種不同型別的缺陷和背景。SAM模型在處理這些復雜場景時可能會遇到一定的困難。
缺陷多樣性: 工業產品中的缺陷型別多樣,包括裂紋、劃痕、凹坑等。這些不同型別的缺陷在形態、大小、顏色等方面存在差異,對SAM模型的分割精度提出了更高的要求。
樣本不平衡: 在實際套用中,正常樣本的數量通常遠多於缺陷樣本。這種樣本不平衡問題可能會影響SAM模型的訓練效果和分割精度。
未來發展趨勢
最佳化影像采集品質:提高缺陷檢測的精度,更加全面、準確地提取特征進行學習以及小尺寸目標的特征提取。 減少訓練樣本需求: 使用較少的圖片樣本訓練出表現優異的檢測模型。 基於DiT模型實作自動缺陷生成。 全方位缺陷檢測: 利用三維建模等技術對物體進行全方位的缺陷檢測。 模型小型化技術與無監督或者提示學習技術會在缺陷檢測領域不斷發展。
OpenCV4系統化學習

深度學習系統化學習

推薦閱讀












