轉自:新智元
編輯: 編輯部
【新智元導讀】 就在剛剛,全新升級4.0的日日新大模型釋出!不僅如此,商湯還搶先OpenAI先發了支持不同模態工具呼叫的Assistants API!現在,超千萬的中文開發者可以輕松玩轉「文生圖」和「圖生文」了。
就在剛剛,商湯新一代「日日新SenseNova 4.0」大模型體系全面升級,多項任務效能超越GPT-4。
與此同時,全球第一個 支 持不 同模態工具呼叫的 Assistants API ,也在今日 釋出!

API申請網址:https://platform.sensenova.cn/
除了 商量大語言模型 、 秒畫文生圖大模型 外,商湯還釋出了 大 語言模型的數據分析版本 、升級了 醫療版本「大醫」 等,將LLM通用能力推向更多領域。同時還有備受期待的 多模態大模型 。
值得一提的是,商湯最新的Assistants API內建多種工具,支持「文生圖」與「圖生文」的工具屬實是全球先發,目前就連OpenAI也還無法做到!
當我們將大模型和各類套用服務工具連線起來,開發者就輕松擁有了強大的AI助手,LLM「大腦」就有了「眼睛」和「手臂」。
現在,到商湯日日新SenseNova4.0平台,國內的開發者和使用者就能在一個系統裏,輕松呼叫圖文多模態能力了。
全新SOTA模型+Assistants API,輕松拿捏各種任務
智慧識圖
影像理解是任何多模態模型必不可少的技能。
比如,給模型一張行車路況圖,乍一看,貌似是一道考驗OCR能力的題目。
實則不然,想要正確回答這道題,它不僅需要將圖中占比較小的多塊指示牌上的字型提取出來,還需要進行推理,最終才能判斷出去黃石東路怎麽走。

再輸入一幅畫,它便一眼認出這是油畫,還可以精準地將作品中的各種細節特征描述出來,比如蝴蝶的動態、昆蟲的顏色。
甚至,基於以上的一些特征總結,它還能進行深入分析,提供自身評價供我們參考。

此外,在海報辨識上,它的表現也是十分出色——透過辨識海報中的文字資訊,便能確定海報主題。
還能快速解析海報主題相關的資訊,結合文字資訊和視覺資訊讀懂整幅海報的氛圍。

服裝穿搭,它也非常拿手,讓你穿著打扮更有範兒。
當你問這件外套,該怎麽搭配?
它會辨識出衣服顏色款式,並會提供合適的穿搭建議,「配一件白色或淺色系的襯衫,下裝選黑色或深棕色的褲子,然後配一雙黑色的皮鞋」。

多模態模型能讀懂的不只是氛圍圖,還有表情包。
比如一只傾頭凝視的貓咪,以及背後傳達的情緒與態度,都能辨識出。

上傳東方明珠的照片,它就會給出詳細介紹。
圖片生成
除了影像理解外,文生圖功能還可以為你畫出剛剛這個場景的夜景。
線上檢索
線上檢索工具,則是讓我們擁有了存取外部知識的能力。
比如,讓它查詢上海各區最新的人口數據,就能給出準確的回應。
數據分析
此外,還可以透過對話進行文件和數據分析。
比如作為一個產品經理,想了解世界範圍內各個APP的使用情況,就只需要上傳一份APP使用數據的excel表格。
勤勤懇懇的小諾古力會立刻在左邊對話方塊生成相應的Python程式碼,以及所要求的圖表,並在右邊給出對應的分析結果。
不管是簡單的折線圖,還是復雜的箱線圖,都可以快速呈現。
除此之外,它還可以分析多個表格之間的關聯關系。比如看一下各地的水資源分布和他的人口數是否有相關性。

不僅可以針對多個表格檔進行關聯分析,還能進行多輪對話。以及如果對圖表呈現感覺不滿意,還能提出修改意見。
商湯日日新4.0釋出
顯然,這些能力的實作,都要靠強大的模型能力來提供支持。
目前,經過最新升級的日日新4.0,在整體表現上已經非常接近GPT-4的水平了。
相比之前版本,日日新 4.0擁有更為全面的知識覆蓋、更加可靠的推理能力,更長文本理解力,及穩定的數位推理能力和程式碼生成能力,並支持跨模態互動。
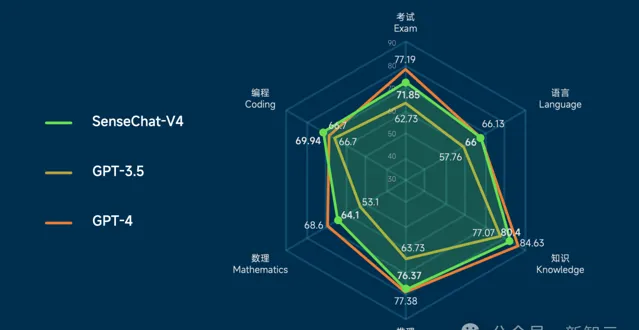
具體來說:
- 程式碼能力在HumanEval Coding評測上斬獲75.6分,超越了GPT-4Turbo的74.4分
- 多模態能力在MMBench評測上,整體效能超越GPT-4V(84.4分 vs 74.4分)
- 程式碼直譯器在數據分析領域以85.71%的正確率超越了GPT-4的84.62%
- 此外還有部份垂直領域能力,也可以實作對GPT-4 Turbo的超越
- 而推理能力則達到了GPT-4 Turbo 99%的水平

商量大語言模型-通用版本(SenseChat V4):4K/32k/128k全面升級,測試成績比肩GPT-4
我們看到,研究團隊新增了包括業務通用、數學能力、K12考試和文學期刊數據的約600B tokens的中英文預訓練語料,從而讓模型的理解能力和輸出品質有了質的提高。
此外還對模型進行了4次超強的預訓練,使得模型在閱讀理解、綜合推理、程式碼能力等任務上實作了5%-10%的定向性提升。
針對不同的使用場景,他們分別升級了4k、32k、128k三種上下文視窗模型的效能,拓展了套用範圍。
其中SenseChat-32k可支持約三萬字以上的中文長文本總結,整體能力平均達到了GPT-4-32K 90%以上水平,並在理解能力上實作了超越。
而「旗艦級」的SenseChat-128k,更是可以支持約十二萬以上的中文長文本總結,並且同樣在理解能力方面實作了對GPT-4的超越。
在「大海撈針」實驗中128k、32k都實作了近乎完美的召回率,整體表現超過GPT-4。

日日新· 商量大語言模型-數據分析版本(SenseChat-DataAnalysisCode V4)
除此之外,商湯 還新增了商量大語言模型-數據分析版本 以及數據分析工具「辦公小諾古力」,能理解多種表格和檔型別以及復雜表格處理。
可支持多種格式的本地數據檔上傳(如xls、xlsx、csv、txt、json等),以及單表格、多表格、多文件型別、復雜表格等不同數據場景。
結果顯示,模型在1000+測試集上的精度超越GPT-4(85.71% vs 84.62%),並且在強大的中文理解能力加持下,更能夠滿足國內數據分析的需求。
日日新· 商量大語言模型-醫療版本「大醫」(SenseChat-Medical V4)
醫療場景下,「大醫」在多輪對話與上下文理解能力上面實作了效能的大幅提升。
它還可以有效實作專業醫學問答以及復雜醫學任務的推理,配合上豐富的工具呼叫能力,還能支持更多模態醫學檔的智慧解讀和互動問答。
在兩項行業權威評測——2023年職業藥劑師考試大模型評測和中文醫療大語言模型開放評測平台MedBench中,「大醫」均躋身綜合評分排名第二,效能接近GPT-4。
成績超越了多個通用及醫療垂類開源大語言模型,體現了非常高的專業垂直領域的落地效能。

2023年職業藥劑師考試大模型評測
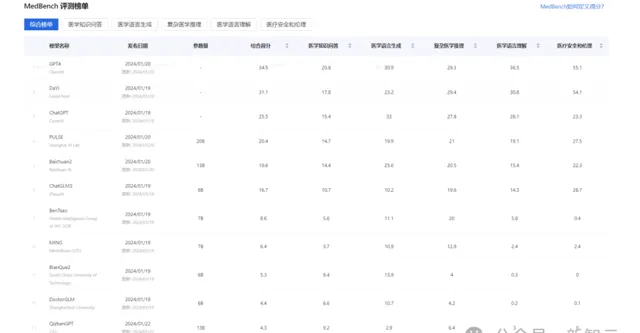
中文醫療大語言模型的開放評測平台MedBench
日日新·商量多模態大模型(SenseChat-Vision V4):不止「看」到,還能 「讀」懂
多模態大模型作為大模型發展的最前沿,它的能力直接決定了大模型在各行各業中落地後解決實際問題的能力。
而商湯的圖文多模態大模型,不僅在開放世界視覺理解、描述、常識理解、抽象推理、多模態知識等方面表現卓越,而且視覺感知力已經無限接近人類水平。
可以看到,在權威綜合基準測試MME Benchmark中,綜合得分排名全球第一,表現出了全世界獨一份的視覺感知能力。
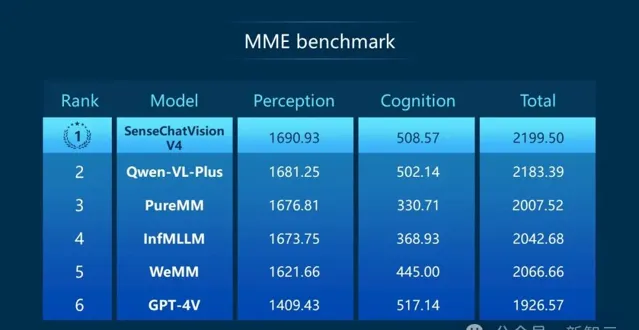
在分別評測中英文多模態能力的MMB-CN與MMB-EN中,均超過GPT-4V總分位列第一,在處理中文和英文場景的圖文感知需求方面都具備強勁優勢。
其中,測評集共包含20個評測維度,透過從細粒度感知、單例項感知、跨例項感知、內容推理、關系推理、邏輯推理等方面來全面評估模型的多模態能力。
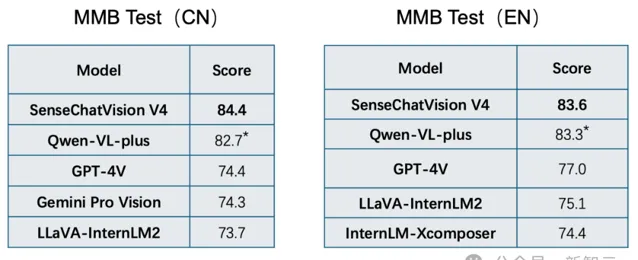
而在覆蓋認知、知識、OCR、空間定位、語言生成、數學六大核心多模態視覺問答能力評價榜單MM-Vet中,也處於國內領先的位置。
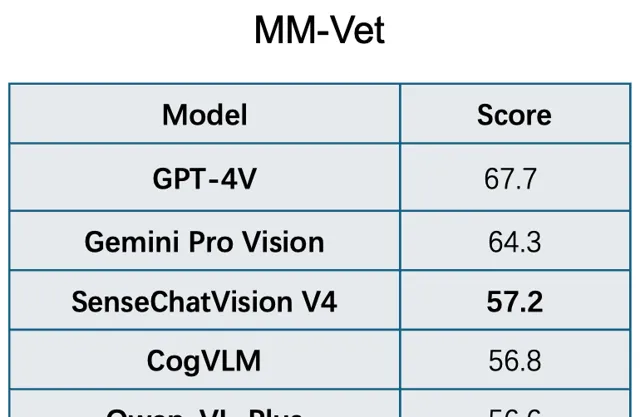
之所以能夠取得如此出眾的多模態綜合能力,首先是基於領先的單項能力。
首先,視覺基礎模型擁有60億參數,效能與業界領先的谷歌ViT 22B持平,在多個任務上達到業界SOTA。
其次,還融合了大語言模型的優勢,強化了圖文跨模態領域的能力。

具體在模型的訓練上,研究團隊不僅開發了用於處理經典視覺任務(如分類、檢測、分割、Grounding等)的通用視覺任務解碼器。
而且,對於開放式的長尾任務,還提出了通用長尾任務控制器,進一步拓展了多模態大模型的能力邊界。
日日新·秒畫文生圖大模型(SenseMirage V4):細節品質大幅提升,實作電影級質感
在頂級的影像繪制能力基礎之上,秒畫文生圖大模型結合了語言模型對於提示詞的超強理解能力。
使用者不用描述出畫面所有的細節,只要提供畫面的主要資訊和基本用途,就能生成電影海報級的精美影像。

這樣,不但大大降低生圖模型的使用門檻,還能有效保證Assistant API呼叫時能做到「精準分割,所問即所得」。
具體來說,相對於之前的版本,秒畫文生圖大模型在高效的數據清理策略下,圖文對增至10億+對,模型的參數量也提升至百億量級。
他們還進一步最佳化了模型的Turbo版本,結合Adversarial Distillation,達到了10倍的加速效果。
模型采用了Mixture of text experts、Spatial-aware CFG等演算法,大振幅提升語意理解與影像質感和細節表現。
Assistants API首次支持不同模態工具呼叫
對於開發者使用者來說,這次更新升級還帶來了超越OpenAI的工具能力——
最新的⽇⽇新·商量大語言模型Function call & Assistants API版本內建圖片生成(文生圖)、智慧識圖(圖生文)、數據分析(程式碼直譯器)、線上檢索工具。
如此一來,大大降低了開發者想要在自己的套用中實作各種AI功能的門檻,使得API的呼叫效率產生了質的提高。
Assistants API的概念最早是OpenAI提出的。去年11月在首屆開發者大會上,Sam Altman重磅釋出面向開發者的全新產品Assistants API,開啟了測試階段。任何擁有OpenAI API的使用者都能夠使用。
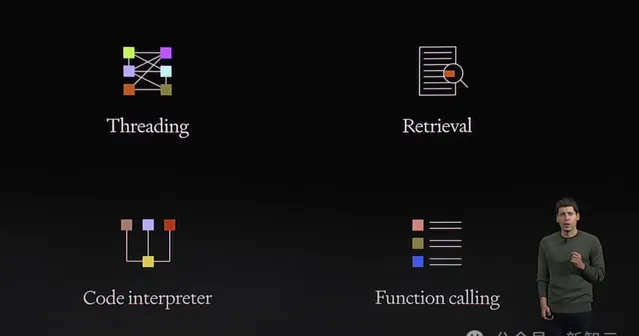
現場,Altman介紹了Assistants API具備的能力有:
- 持久對話,意味著開發者不用再為如何處理長歷史會話而煩惱
- 支持對檢索(Retrieval)、程式碼直譯器(Code Interpreter)等OpenAI托管工具的存取
- 支持第三方工具的函式呼叫(Function Call)
函式呼叫是可以讓Assistants API與外部工具和API連線的新方式。它可以讓模型輸出一個請求呼叫函式的訊息,其中就包括呼叫的函式資訊,以及參數資訊。
然而遺憾的是,OpenAI助手API沒有多模態能力,目前不支持DALL-E模型。

與單個模型API呼叫(比如Images API,GPT-4 Turbo、Audio API)不同,可以看到Assistants API已經擁有模型、工具、檢索等功能的整合,能為開發者節省大量的時間。
根據Altman的設想,「隨著時間的推進,GPTs和Assistants API將作為智慧體的前身,未來能夠為我們做越來越多的事情。它不僅能規劃我們的生活,還能執行更為復雜的任務」。
商湯此次釋出了全球第一個支持不同模態工具呼叫的Assistants API,先OpenAI一步讓理想照進了現實。
與基礎的Chat Completion介面相比,商湯Assistants API的突出優勢在於,支持圖文結合的多模態互動,和程式碼執行結果的直觀呈現。
這些內建工具的綜合運用,使得Assistants API能夠透過多輪對話和多輪工具呼叫,解決更加復雜的問題。
Assistants API不僅賦予了大型模型以辨識影像、編寫程式碼、執行互聯網搜尋和繪制影像的能力,還允許使用者自訂工具,進一步擴充套件了這個LLM「大腦」的操作範圍。
Assistants API的創新,將推動商業技術格局發生巨變。這一突破性的工具,不僅是一項技術進步,還為客戶互動、流程自動化和決策提供了一種新的可能性。
- 超長上下文,重新定義對話
Assistants API的一個核心特點是它提供了一個更加結構化的方法,來處理使用者與大模型之間的互動。
這是透過建立一個「執行緒」——代表一場對話——來實作的。在這個執行緒上,可以傳遞特定於使用者的上下文和檔,從而使對話更加個人化和連貫。
這個執行緒沒有大小限制,可以向執行緒傳遞任意多的訊息,而API會使用相關最佳化技術,確保對模型的請求適合最大上下文視窗。
對於企業來說,每次客戶的互動都可以保留成歷史會話,可以擁有完整的持續對話的能力。
這樣的設計,可以確保每個查詢都能在上下文中被理解,從而產生更相關和更有洞察力的回答。
- 建立量身訂制AI助手,改變互動方式
此外,Assistants API的核心就是增強企業與客戶、數據的互動方式。
使用者可以根據需求客製一個AI助手——能夠進行對話響應、執行復雜的數據分析,或提供個人化客戶支持。
最重要的是,它提供了一個簡化的流程來建立AI助手,能夠以前所未有的準確性,理解和響應復雜查詢。
- 程式碼直譯器解決即時問題
對於需要處理數據,或分析復雜數據的開發者和企業,程式碼直譯器能夠讓AI助手安全地執行Python程式碼,將其轉換為即時解決問題的強大工具。
- 透過檢索擴充套件套用知識
而檢索工具可以讓AI助手存取外部知識,提供在預訓練數據之外的內容,豐富特定資訊的回應。
由此可以看出,Assistants API不僅僅是一種AI工具,更是一種商業戰略資產。
它提供了一個靈活、高度可客製的框架,開發者可以透過結構化的執行緒處理使用者請求,並結合多種多模態工具和模型來提供響應。
它可以徹底改變客戶服務,自動化復雜任務,並可以推動企業富有洞察力的決策和創新。
隨著商湯「日日新模型」升級到4.0,不論是在大語言模型、多模態大模型,還是在文生圖大模型,全部完成了新一輪前進演化。
超強模型大腦,外加工具呼叫能力,能夠為開發者和企業建立客製的開套用,開辟了全新的視野。
面向未來,大模型的根本就在於重塑生產力模式,商湯正在做的,就是用全新工具為技術研發賦能。
參考資料:
https://platform.sensenova.cn/











