說在前邊
沒想到大家對於分庫分表的話題會這麽感興趣,可能很多人的工作內容業務量較小很難接觸到這方面的技能。
這個系列在我腦子裏籌劃了挺久的,奈何手說啥也不幹活,就一直拖到了現在。

其實網上關於分庫分表相關的文章很多,但我還是堅持出這個系列,主要是自己學習研究,順便給分享,對於一個知識,不同的人從不同的角度理解的不盡相同。
網上的資料看似很多,不過值得學有價值的得仔細挑,很多時候在篩選甄別的過程中,逐漸的磨滅了本就不高的學習熱情。搬運抄襲雷同的東西太多,而且知識點又都比較零碎,很少有細致的原理實戰案例。對新手來說妥妥的從入門到放棄,即便有成體系的基本上幾篇後就斷更了。
我不太喜歡堆砌名詞概念,熟悉我的朋友不難發現,我的文章從來都是講完原理緊跟著來一波實戰操作。學習技術原理必須配合實操鞏固一下,不然三天半不到忘得幹幹凈凈,純純的經驗之談。
上圖是我初步羅列的
ShardingSphere
提綱,在官網文件基礎上補充了很多基礎知識,這個系列會用幾十篇文章,詳細的梳理分庫分表基礎理論,手把手的實戰
ShardingSphere 5.X
框架的功能和解讀源碼,以及開發中容易踩坑的點,每篇附帶程式碼案例demo,旨在讓新手也能看的懂,後續系列完結全部內容會整理成
PDF
分享給大家,期待一下吧!
話不多說,咱們這就進入正題~
不急於上手實戰
ShardingSphere
框架,先來復習下分庫分表的基礎概念,技術名詞大多晦澀難懂,不要死記硬背理解最重要,當你捅破那層窗戶紙,發現其實它也就那麽回事。
什麽是分庫分表
分庫分表是在海量數據下,由於單庫、表數據量過大,導致資料庫效能持續下降的問題,演變出的技術方案。
分庫分表是由
分庫
和
分表
這兩個獨立概念組成的,只不過通常分庫與分表的操作會同時進行,以至於我們習慣性的將它們合在一起叫做分庫分表。
透過一定的規則,將原本數據量大的資料庫拆分成多個單獨的資料庫,將原本數據量大的表拆分成若幹個數據表,使得單一的庫、表效能達到最優的效果(響應速度快),以此提升整體資料庫效能。
為什麽分庫分表
單機資料庫的儲存能力、連線數是有限的,它自身就很容易會成為系統的瓶頸。當單表數據量在百萬以裏時,我們還可以透過添加從庫、最佳化索引提升效能。
一旦數據量朝著千萬以上趨勢增長,再怎麽最佳化資料庫,很多操作效能仍下降嚴重。為了減少資料庫的負擔,提升資料庫響應速度,縮短查詢時間,這時候就需要進行分庫分表。
為什麽需要分庫?
容量
我們給資料庫例項分配的磁盤容量是固定的,數據量持續的大幅增長,用不了多久單機的容量就會承載不了這麽多數據,解決辦法簡單粗暴,加容量!
連線數
單機的容量可以隨意擴充套件,但資料庫的連線數卻是有限的,在高並行場景下多個業務同時對一個資料庫操作,很容易將連線數耗盡導致
too many connections
報錯,導致後續資料庫無法正常存取。
可以透過
max_connections
檢視MySQL最大連線數。
showvariableslike'%max_connections%'
將原本單資料庫按不同業務拆分成訂單庫、物流庫、積分庫等不僅可以有效分攤資料庫讀寫壓力,也提高了系統容錯性。
為什麽需要分表?
做過報表業務的同學應該都體驗過,一條SQL執行時間超過幾十秒的場景。
導致資料庫查詢慢的原因有很多,SQL沒命中索引、like掃全表、用了函式計算,這些都可以透過最佳化手段解決,可唯獨數據量大是MySQL無法透過自身最佳化解決的。慢的根本原因是
InnoDB
儲存引擎,聚簇索引結構的 B+tree 層級變高,磁盤IO變多查詢效能變慢,詳細原理自行尋找一下,這裏不用過多篇幅說明。
阿裏的開發手冊中有條建議,單表行數超500萬行或者單表容量超過2GB,就推薦分庫分表,然而理想和實作總是有差距的,阿裏這種體量的公司不差錢當然可以這麽用,實際上很多公司單表數據幾千萬、億級別仍然不選擇分庫分表。
什麽時候分庫分表
技術群裏經常會有小夥伴問,到底什麽情況下會用分庫分表呢?
分庫分表要解決的是
現存海量數據
存取的效能瓶頸,對
持續激增
的數據量所做出的架構預見性。
是否分庫分表的關鍵指標是數據量
,我們以
fire100.top
這個網站的資源表
t_resource
為例,系統在執行初始的時候,每天只有可憐的幾十個資源上傳,這時使用單庫、單表的方式足以支持系統的儲存,數據量小幾乎沒什麽資料庫效能瓶頸。
但某天開始一股神秘的流量進入,系統每日產生的資源數據量暴增至十萬甚至上百萬級別,這時資源表數據量到達千萬級,查詢響應變得緩慢,資料庫的效能瓶頸逐漸顯現。
以MySQL資料庫為例,單表的數據量在達到億條級別,透過加索引、SQL調優等傳統最佳化策略,效能提升依舊微乎其微時,就可以考慮做分庫分表了。
既然MySQL儲存海量數據時會出現效能瓶頸,那麽我們是不是可以考慮用其他方案替代它?比如高效能的非關系型資料庫
MongoDB
?
可以,但要看儲存的數據型別!
現在互聯網上大部份公司的核心數據幾乎是儲存在關系型資料庫(MySQL、Oracle等),因為它們有著
NoSQL
如法比擬的穩定性和可靠性,產品成熟生態系完善,還有核心的事務功能特性,也是其他儲存工具不具備的,而評論、點贊這些非核心數據還是可以考慮用
MongoDB
的。
如何分庫分表
分庫分表的核心就是對數據的分片(
Sharding
)並相對均勻的路由在不同的庫、表中,以及分片後對數據的快速定位與檢索結果的整合。
分庫與分表可以從:垂直(縱向)和 水平(橫向)兩種緯度進行拆分。下邊我們以經典的訂單業務舉例,看看如何拆分。
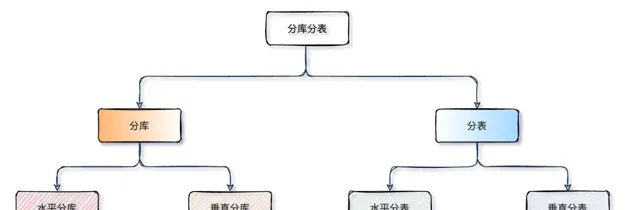
垂直拆分
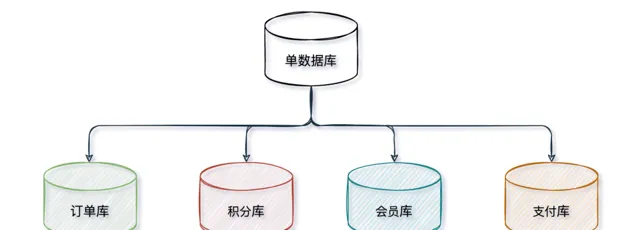
1、垂直分庫
垂直分庫一般來說按照業務和功能的維度進行拆分,將不同業務數據分別放到不同的資料庫中,核心理念
專庫專用
。
按業務型別對數據分離,剝離為多個資料庫,像訂單、支付、會員、積分相關等表放在對應的訂單庫、支付庫、會員庫、積分庫。不同業務禁止跨庫直連,獲取對方業務數據一律透過
API
介面互動,這也是微服務拆分的一個重要依據。
垂直分庫很大程度上取決於業務的劃分,但有時候業務間的劃分並不是那麽清晰,比如:電商中訂單數據的拆分,其他很多業務都依賴於訂單數據,有時候界線不是很好劃分。
垂直分庫把一個庫的壓力分攤到多個庫,提升了一些資料庫效能,但並沒有解決由於單表數據量過大導致的效能問題,所以就需要配合後邊的分表來解決。
2、垂直分表
垂直分表針對業務上欄位比較多的大表進行的,一般是把業務寬表中比較獨立的欄位,或者不常用的欄位拆分到單獨的數據表中,是一種大表拆小表的模式。
例如:一張
t_order
訂單表上有幾十個欄位,其中訂單金額相關欄位計算頻繁,為了不影響訂單表
t_order
的效能,就可以把訂單金額相關欄位拆出來單獨維護一個
t_order_price_expansion
擴充套件表,這樣每張表只儲存原表的一部份欄位,透過訂單號
order_no
做關聯,再將拆分出來的表路由到不同的庫中。
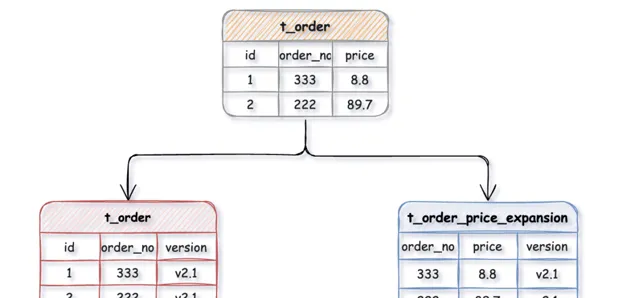
資料庫它是以行為單位將數據載入到記憶體中,這樣拆分以後核心表大多是存取頻率較高的欄位,而且欄位長度也都較短,因而可以載入更多數據到記憶體中,減少磁盤IO,增加索引查詢的命中率,進一步提升資料庫效能。
水平拆分
上邊垂直分庫、垂直分表後還是會存在單庫、表數據量過大的問題,當我們的套用已經無法在細粒度的垂直切分時,依舊存在單庫讀寫、儲存效能瓶頸,這時就要配合水平分庫、水平分表一起了。
1、水平分庫
水平分庫是把同一個表按一定規則拆分到不同的資料庫中,每個庫可以位於不同的伺服器上,以此實作水平擴充套件,是一種常見的提升資料庫效能的方式。
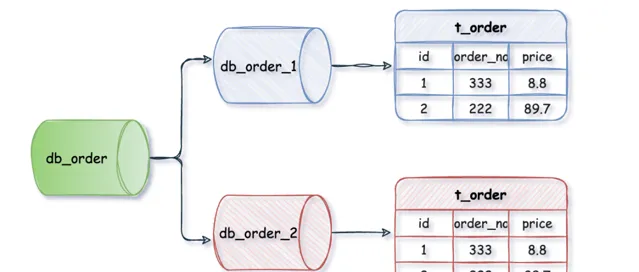
例如:
db_orde_1
、
db_order_2
兩個資料庫內有完全相同的
t_order
表,我們在存取某一筆訂單時可以透過對訂單的訂單編號取模的方式
訂單編號 mod 2 (資料庫例項數)
,指定該訂單應該在哪個資料庫中操作。
這種方案往往能解決單庫儲存量及效能瓶頸問題,但由於同一個表被分配在不同的資料庫中,數據的存取需要額外的路由工作,因此系統的復雜度也被提升了。
2、水平分表
水平分表是在 同一個資料庫內 ,把一張大數據量的表按一定規則,切分成多個結構完全相同表,而每個表只存原表的一部份數據。
例如:一張
t_order
訂單表有900萬數據,經過水平拆分出來三個表,
t_order_1
、
t_order_2
、
t_order_3
,每張表存有數據300萬,以此類推。
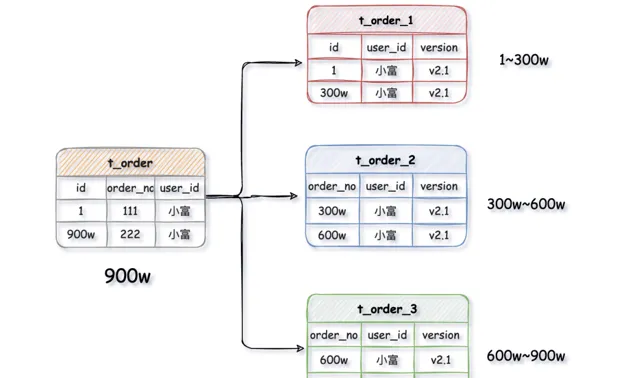
水平分表盡管拆分了表,但子表都還是在同一個資料庫例項中,只是解決了單一表數據量過大的問題,並沒有將拆分後的表分散到不同的機器上,還在競爭同一個物理機的CPU、記憶體、網路IO等。要想進一步提升效能,就需要將拆分後的表分散到不同的資料庫中,達到分布式的效果。
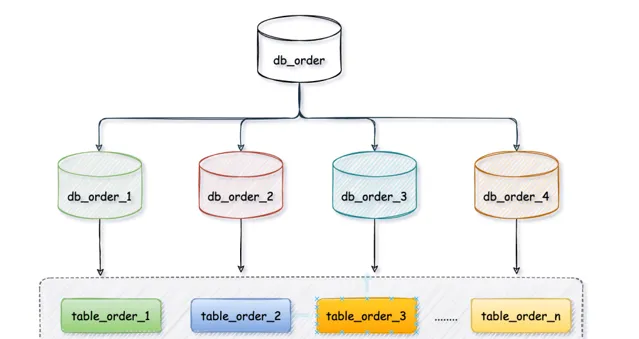
數據存在哪個庫的表
分庫分表以後會出現一個問題,一張表會出現在多個資料庫裏,到底該往哪個庫的哪個表裏存呢?
上邊我們多次提到過
一定規則
,其實這個規則它是一種路由演算法,決定了一條數據具體應該存在哪個資料庫的哪張表裏。
常見的有
取模演算法
、
範圍限定演算法
、
範圍+取模演算法
、
預定義演算法
1、取模演算法
關鍵欄位取模(對hash結果取余數 hash(XXX) mod N),N為資料庫例項數或子表數量)是最為常見的一種路由方式。
以
t_order
訂單表為例,先給資料庫從 0 到 N-1進行編號,對
t_order
訂單表中
order_no
訂單編號欄位進行取模
hash(order_no) mod N
,得到余數
i
。
i=0
存第一個庫,
i=1
存第二個庫,
i=2
存第三個庫,以此類推。
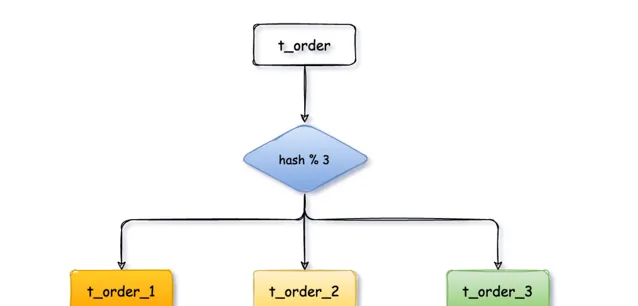
同一筆訂單數據會落在同一個庫、表裏,查詢時用相同的規則,用
t_order
訂單編號作為查詢條件,就能快速的定位到數據。
優點
實作簡單,數據分布相對比較均勻,不易出現請求都打到一個庫上的情況。
缺點
取模演算法對集群的伸縮支持不太友好,集群中有N個資料庫實
·hash(user_id) mod N
,當某一台機器宕機,本應該落在該資料庫的請求就無法得到處理,這時宕掉的例項會被踢出集群。
此時機器數減少演算法發生變化
hash(user_id) mod N-1
,同一使用者數據落在了在不同資料庫中,等這台機器恢復,用
user_id
作為條件查詢使用者數據就會少一部份。
2、範圍限定演算法
範圍限定演算法以某些範圍欄位,如
時間
或
ID區
拆分。
使用者表
t_user
被拆分成
t_user_1
、
t_user_2
、
t_user_3
三張表,後續將
user_id
範圍為1 ~ 1000w的使用者數據放入
t_user_1
,1000~ 2000w放入
t_user_2
,2000~3000w放入
t_user_3
,以此類推。按日期範圍劃分同理。
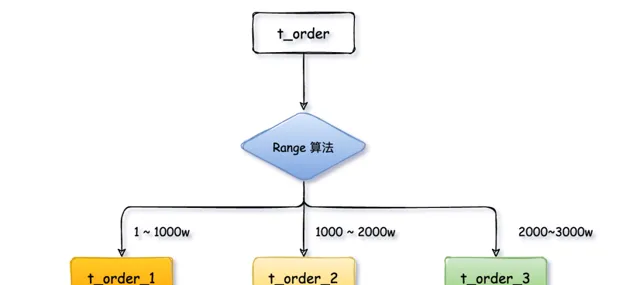
優點
單表數據量是可控的
水平擴充套件簡單只需增加節點即可,無需對其他分片的數據進行遷移
缺點
由於連續分片可能存在
數據熱點
,比如按時間欄位分片時,如果某一段時間(雙11等大促)訂單驟增,存11月數據的表可能會被頻繁的讀寫,其他分片表儲存的歷史數據則很少被查詢,導致數據傾斜,資料庫壓力分攤不均勻。
3、範圍 + 取模演算法
為了避免熱點數據的問題,我們可以對上範圍演算法最佳化一下
這次我們先透過範圍演算法定義每個庫的使用者表
t_user
只存1000w數據,第一個
db_order_1
庫存放
userId
從1 ~ 1000w,第二個庫1000~2000w,第三個庫2000~3000w,以此類推。
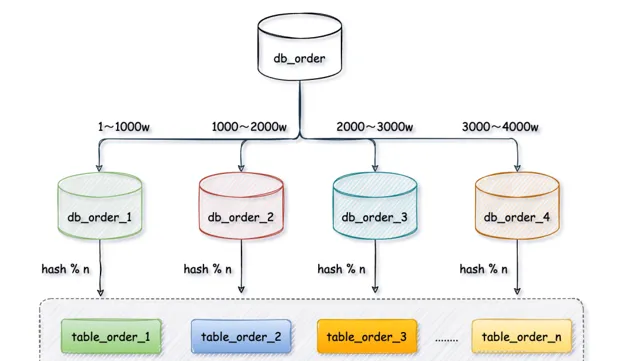
每個柯瑞再把使用者表
t_user
拆分成
t_user_1
、
t_user_2
、
t_user_3
等,對
userd
進行取模路由到對應的表中。
有效的避免數據分布不均勻的問題,資料庫水平擴充套件也簡單,直接添加例項無需遷移歷史數據。
4、地理位置分片
地理位置分片其實是一個更大的範圍,按城市或者地域劃分,比如華東、華北數據放在不同的分片庫、表。
5、預定義演算法
預定義演算法是事先已經明確知道分庫和分表的數量,可以直接將某類數據路由到指定庫或表中,查詢的時候亦是如此。
分庫分表出來的問題
了解了上邊分庫分表的拆分方式不難發現,相比於拆分前的單庫單表,系統的數據儲存架構演變到現在已經變得非常復雜。看幾個具有代表性的問題,比如:
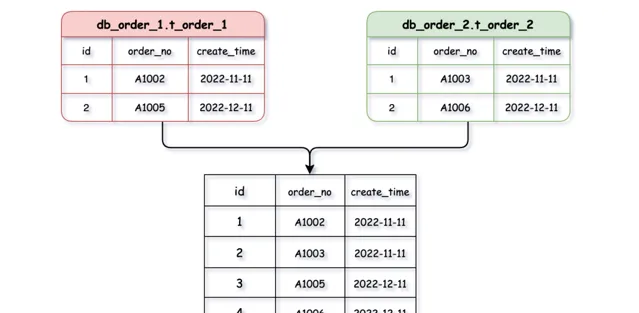
分頁、排序、跨節點聯合查詢
分頁、排序、聯合查詢,這些看似普通,開發中使用頻率較高的操作,在分庫分表後卻是讓人非常頭疼的問題。把分散在不同庫中表的數據查詢出來,再將所有結果進行匯總合並整理後提供給使用者。
比如:我們要查詢11、12月的訂單數據,如果兩個月的數據是分散到了不同的資料庫例項,則要查詢兩個資料庫相關的數據,在對數據合並排序、分頁,過程繁瑣復雜。
事務一致性
分庫分表後由於表分布在不同庫中,不可避免會帶來跨庫事務問題。後續會分別以阿裏的
Seata
和MySQL的
XA
協定實作分布式事務,用來比較各自的優勢與不足。
全域唯一的主鍵
分庫分表後資料庫表的主鍵ID業務意義就不大了,因為無法在標識唯一一條記錄,例如:多張表
t_order_1
、
t_order_2
的主鍵ID全部從1開始會重復,此時我們需要主動為一條記錄分配一個ID,這個全域唯一的ID就叫
分布式ID
,發放這個ID的系統通常被叫發號器。
多資料庫高效治理
對多個資料庫以及庫內大量分片表的高效治理,是非常有必要,因為像某寶這種大廠一次大促下來,訂單表可能會被拆分成成千上萬個
t_order_n
表,如果沒有高效的管理方案,手動建表、排查問題是一件很恐怖的事。
歷史數據遷移
分庫分表架構落地以後,首要的問題就是如何平滑的遷移歷史數據,增量數據和全量數據遷移,這又是一個比較麻煩的事情,後邊詳細講。
分庫分表架構模式
分庫分表架構主要有兩種模式:
client
客戶端模式和
proxy
代理模式
客戶模式
client
模式指分庫分表的邏輯都在你的系統套用內部進行控制,套用會將拆分後的SQL直連多個資料庫進行操作,然後本地進行數據的合並匯總等操作。
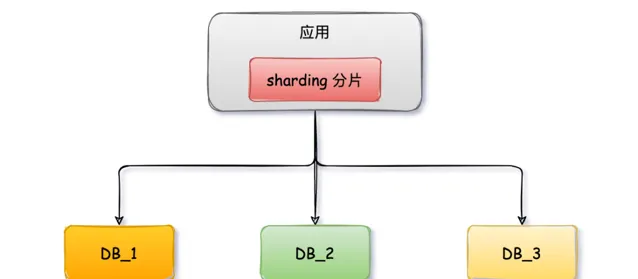
代理模式
proxy
代理模式將應用程式與MySQL資料庫隔離,業務方的套用不在需要直連資料庫,而是連線proxy代理服務,代理服務實作了MySQL的協定,對業務方來說代理服務就是資料庫,它會將SQL分發到具體的資料庫進行執行,並返回結果。該服務內有分庫分表的配置,根據配置自動建立分片表。

如何抉擇
如何選擇
client
模式和
proxy
模式,我們可以從以下幾個方面來簡單做下比較。
1、效能
效能方面
client
模式表現的稍好一些,它是直接連線MySQL執行命令;
proxy
代理服務則將整個執行鏈路延長了,套用->代理服務->MySQL,可能導致效能有一些損耗,但兩者差距並不是非常大。
2、復雜度
client
模式在開發使用通常引入一個jar可以;
proxy
代理模式則需要搭建單獨的服務,有一定的維護成本,既然是服務那麽就要考慮高可用,畢竟套用的所有SQL都要透過它轉發至MySQL。
3、升級
client
模式分庫分表一般是依賴基礎架構團隊的Jar包,一旦有版本升級或者Bug修改,所有套用到的計畫都要跟著升級。小規模的團隊服務少升級問題不大,如果是大公司服務規模大,且涉及到跨多部門,那麽升級一次成本就比較高;
proxy
模式在升級方面優勢很明顯,釋出新功能或者修復Bug,只要重新部署代理服務集群即可,業務方是無感知的,但要保證釋出過程中服務的可用性。
4、治理、監控
client
模式由於是內嵌在套用內,套用集群部署不太方便統一處理;
proxy
模式在對SQL限流、讀寫許可權控制、監控、告警等服務治理方面更優雅一些。
結束語
本文主要是回顧一下分庫分表的一些基礎概念,為大家在後續
ShardingSphere
實踐中更好上手理解,內容裏很多概念一筆帶過沒詳細展開。
如喜歡本文,請點選右上角,把文章分享到朋友圈
如有想了解學習的技術點,請留言給若飛安排分享
因公眾號更改推播規則,請點「在看」並加「星標」 第一時間獲取精彩技術分享
·END·
相關閱讀:
作者:小富
來源:程式設計師小富
版權申明:內容來源網路,僅供學習研究,版權歸原創者所有。如有侵權煩請告知,我們會立即刪除並表示歉意。謝謝!
架構師
我們都是架構師!

關註 架構師(JiaGouX),添加「星標」
獲取每天技術幹貨,一起成為牛逼架構師
技術群請 加若飛: 1321113940 進架構師群
投稿、合作、版權等信箱: [email protected]











