每當看到有人的簡歷上寫著熟悉 tcp/ip, http 等協定時, 我就忍不住問問他們: 你給我說說, 埠是啥吧! 可惜, 很少有人能說得讓人滿意... 所以這次就來談談埠(port), 這個熟悉的陌生人。
在此過程中, 還會談談間接層, naming service 等概念, IoC, 依賴倒置等原則以及 TCP 協定的一些重點知識.
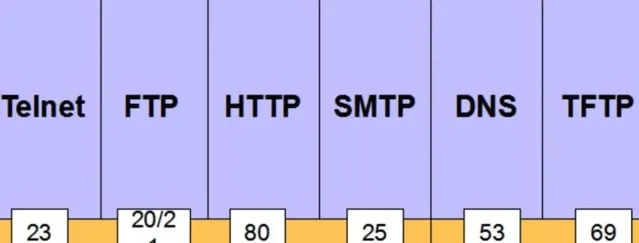
常見埠
在我們的日常開發過程中, 特別是後端的開發人員, 即便他沒有真正理解埠的細節, 他還是會聽過見過各類的埠, 這個東西幾乎無處不在,
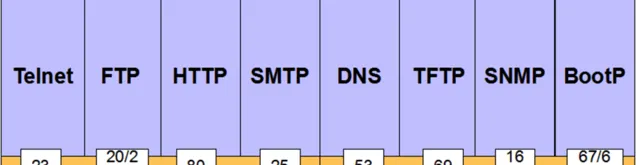
比如:
mysql 缺省用的 3306 埠,
redis 的 6379 埠,
tomcat 預設用的 8080 埠,
ssh 用的 22 埠,
等等...
當然我們最關註的還是 web 相關的埠, 涉及的主要為 80 和 443 兩個埠, 下面就來重點說說.
埠是必須的嗎?
在本地 web 開發偵錯過程中, 我們可能都碰到過埠, 比如或許是/最著名的 8080 埠, 一般我們會這樣去存取原生的 web 程式:
localhost:8080
但一旦 web 程式部署到了正式的網站中, 埠似乎就消失了, 正式的網址中就不需要埠了嗎? 答案是否定的, 在這裏起作用的是缺省值.
比如你存取我的網站: https://xiaogd.net , 這個 url 中似乎沒有埠, 但其實是有的, 它有一個預設值 443, 所以完整的形式實際是這樣的:
https://xiaogd.net :443
你可以透過 Chrome 的開發人員偵錯工具看到這一點:
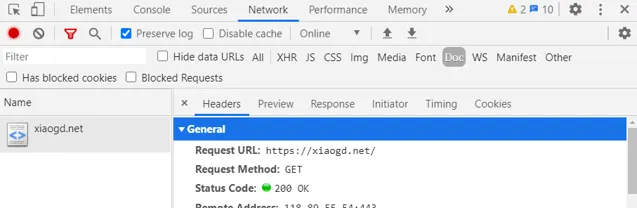
可以看到, ip 地址後面跟著一個 443
如果你輸入一個錯誤的埠, 比如 80, 像這樣: https://xiaogd.net:80, 結果就是無法存取.
但是如果你改成 http://xiaogd.net:80, 它又可以存取了.
註意, 因為我伺服器後台配置了 http 自動跳轉 https 的 301 重新導向, 所以最終瀏覽器會再次跳轉到 https://xiaogd.net:443.
註意勾選 'Preserve log' 以保留日誌, 可以看到第一個 80 埠的請求會被響應一個 301 跳轉, 並指示跳轉目標, 也即是 Location 欄位中的 https 請求, 瀏覽器接收此跳轉指示並重新發起 https 請求, 也即是圖中第二個 xiaogd.net 的請求. 所以位址列最終還是會變成 https 的, 特此說明.
此時如果你輸入 http://xiaogd.net:443, 它又不能存取了...
那麽原因是什麽呢? 你找到規律了沒有?
註意一個是 http, 一個是 https.
協定的缺省埠
當你沒有顯式的在 url 中輸入埠時, 瀏覽器實際上會根據所用的協定來為你指定一個缺省埠:
如果是 http 協定, 就使用 80 埠
如果是 https 協定, 就使用 443 埠
如果你自己輸入埠呢? 那就用你輸入的埠, 你輸入啥就是啥, 輸錯了, 存取不了那就是你的責任了, 誰讓你瞎搞來著?
本來不用你勞神的, 你偏要脫褲子放屁, 搞不好自然就是畫蛇添足, 弄巧成拙了.
比如上面的用了 http 卻輸入了 443, 或者用了 https 卻輸入了 80, 就無法成功存取了.
另外, 如果你胡亂地輸入一個比如 9527, http://xiaogd.net:9527, 自然也是無法存取的, 原因也很簡單, 因為我的伺服器上根本沒有在 9527 埠上進行監聽.
即便我有在 9527 埠上監聽, 提供的也未必是 web 服務, 使用的協定可能既不是 http, 也不是 https, 所以你用瀏覽器試圖去存取也可能會碰壁的.
當然了, 我是完全可以在伺服器上的 9527 埠上再部署一個 web 服務的, 比如放一個 apache 或 tomcat server 之類的 web server 監聽在那個埠上, 再放通防火墻, 安全組之類的, 也是可以存取的. 只是我沒有這麽去做而已.
那麽為啥大家都不在那些奇奇怪怪的埠上提供 web 服務呢? 原因其實也很簡單, 為了方便使用者, 同時也減輕了使用者的認知負擔.
其實關於使用者, 你只要記住兩點就好了:
使用者是傻瓜
使用者是懶漢
深刻地理解了這一點, 你才可能成為一個好的程式設計師(包括但不限於產品經理, 設計師...)
其實呀, 何止了省略了埠呀, 你看看現在的位址列, 不但 http, https 這些協定省了, 最末尾的斜杠 / 省了, 甚至連 www 都省了...
是的, 我也幫你們省了 www, 事實上你透過 https://www.xiaogd.net/ 也能存取到, 但如果透過 https://xiaogd.net/ 就能存取到, 又何苦去再去錄入三個達不溜呢?
必須得承認, 缺省的存在是有很大的幫助的, 這其實是進步; 但另一方面, 這些缺省有時也會給不明就裏的開發人員帶來了一些困惑, 好像埠不是必要的, 但其實不是這樣的.
為什麽需要埠?
那為什麽一定要埠這個東西呢? 它到底起了什麽作用, 想必很多同學想要了解, 下面就來說說為什麽, 而一個首先需要了解的概念就是行程間通訊(所謂的 IPC(inter-process communication)
行程間通訊(IPC)
你在瀏覽器位址列輸入某個網站的網域名稱, 然後回車, 就生成了一次請求, 然後伺服器響應你的請求, 瀏覽器再把結果渲染出來, 你就能最終看到到一個網頁.
如果你曾經 ping 過一個網域名稱, 比如你現在 ping 我的網域名稱 xiaogd.net, 你就能得到一個 ip 地址, 118.89.55.54:
有了 ip, 瀏覽器自然就能找到我的主機, 但還是有個問題, 我的主機上執行著好多的行程, 好多的服務, 除了最常見的 web 服務, 我可能還有 ftp 服務, mysql 服務等等不一而足.
簡單地講, 如果一個請求只有 ip 地址這一資訊, 作業系統將不知道把這個請求交給哪個行程去處理, 如果是你來設計整個系統, 你想象一下, 是不是這樣?
如果你僅僅是輸入網域名稱, 經過 DNS 解析後, 只能得到一個 IP 地址.
所謂的一次請求, 從一個比較底層的角度去看, 就是一次行程間的通訊.
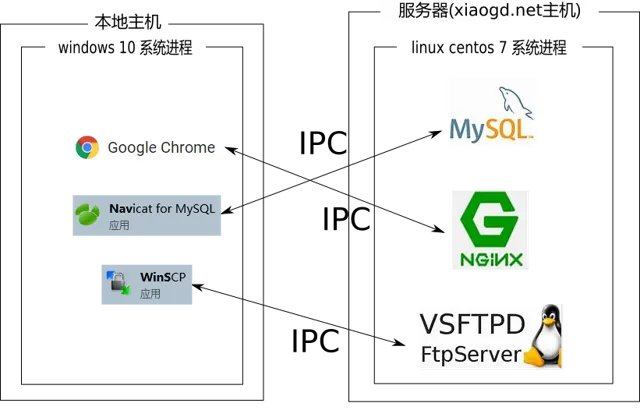
它可以是 navicat 客戶端與 mysql 資料庫服務的一次通訊, 也可以是 winScp 客戶端與 vsftpd FTP 服務的一次通訊等等.
以上面的具體為例, 可以說就是 Chrome 瀏覽器這個本地作業系統上的行程與我的伺服器上的一個叫做 Nginx 的行程間的一次通訊.
那麽, 所謂的埠, 其實可以簡單地視作為行程 ID.
當然, 它與行程 ID 還是有不同的, 下面再分析, 或者目前你可以認為埠就是行程 ID 的影子.
也即是說, 如果僅有網域名稱(ip), 是無法定位到一個行程的, 通訊的發起方不但需要給出 ip, 還需要給出埠, 只有這樣, 伺服器才能知道由哪個行程去響應.
埠, 一個間接層
那麽問題又來了, 為什麽引入埠, 而不是直接使用行程 ID 呢? 這個原因想想也不難明白, 大概有這麽幾點原因:
作為客戶端無法知道伺服端對應行程的 ID
伺服端對應行程重新開機後 ID 會改變
一個網站的 web 行程 ID 是這個, 另一個網站的可能又是另一個
自然, 原因是很多的, 我也是隨便的列舉了一些, 你或許還能想到更多. 而為了解決這些個問題, 就引入了埠這一間接層(indirection).
電腦世界裏有一句名言: 任何電腦問題均可透過增加一個間接(indirection)層來解決.(Any problem in computer science can be solved with another layer of indirection. -- David Wheeler)
這個名言其實還有後面一句: But what usually will create another problem.(但通常會帶來另一個問題)
這裏所謂另一個問題, 比如它會使得階層復混成, 互動效率下降等等. 當然了, 這就是架構師們要去權衡的問題了, 很多時候, 架構就是關於平衡的藝術. 打死都不肯引入任何的間接層, 這是一個極端; 而一上來就引入好多個間接層, 這又是另一個極端.
如果沒有這個間接層, 客戶端要與伺服端通訊, 就要知道伺服端對應行程的 ID, 也即是客戶端是依賴於伺服端的:
顯然, 這種模式對於 web 這種一個伺服端對應大量客戶端存取的情形是極不適應的, 你都不知道有誰可能會來存取你的網站! 你根本無法告訴它們.
而有了埠這一間接層, 對於 web 的情形, 這種依賴被倒置了, 客戶端總是把請求發送到 80(或443) 埠, 這些成為標準的一部份, 並要求伺服端反過來去適應, 伺服端去監聽埠的通訊並處理, 變成了一種反向依賴.
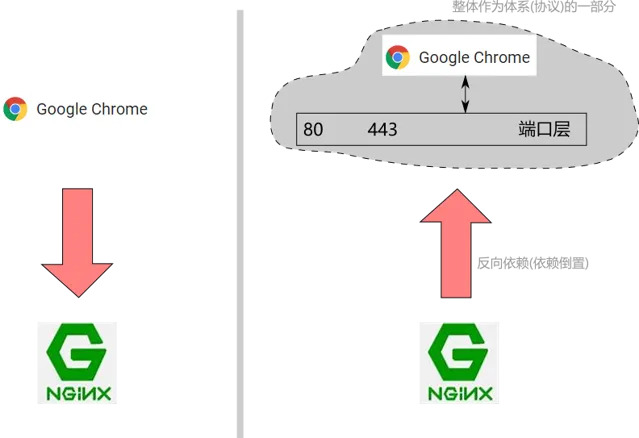
如果一個行程想要提供 web 服務, 它啟動之後就要去繫結(binding) web 相關的埠,
如果埠已經被其它行程繫結了(即所謂占用了), 就會繫結失敗; 又或者被自身前一個未完全結束的行程占據著, 也會繫結失敗, 在開發過程中你可能會遇到類似的問題, 一個 web 行程沒有關閉, 你又試圖啟動另一個, 而兩者都用了相同的埠, 就會產生沖突.
並在其上持續的監聽(listen), 同時在有請求到來的時候去響應(response). 這樣一來, 行程 ID 的問題就消解了:
這類似於一個介面回呼, 瀏覽器只需要面向介面索取服務, 而無需知道介面服務的具體提供者, 這些細節被埠層所封裝並隱藏起來了.
埠這一間接層的存在解耦(decouple)了客戶端與伺服端之間的強依賴, 整個體系變得很靈活.
可以把埠視作一般編程概念中的介面(interface), 而想 Nginx, apache, tomcat 等等可以認為是這個介面的不同實作(Implementation).
埠與現實世界的一個類比
為加深理解, 可以舉一個現實世界中的例子. 相信大家都有過去市民中心辦事的經歷, 比如去辦理居住證, 護照, 社保等等業務, 你通常會收到一個小紙條讓你去某個視窗辦理對應業務, 這個視窗其實就類似於埠了:
比如 80 視窗就對應港澳台通行證業務
那麽你要辦港澳台通行證, 你就奔向 80 號視窗就完了. 你不要去問門口保衛處的王大爺, 到底是哪位同誌辦理這個業務.
今天可能是小明在辦理, 隔了幾天, 小明可能受傷了, 流血了, 又輪到小紅在那裏辦理, 又過段時間, 小紅也出意外了, 流產了, 又輪到小張在辦理, 又過段時間, 小張被發現在辦理業務過程中徇私舞弊, 流放了...
等等, 如果此時你的同事問你怎麽辦港澳台通行證, 你需要知道這些個人事變動的細節嗎? 根本不需要呀, 你只需告訴他去 80 號視窗辦理就好了...
市民中心的整個體系, 會確保有個會辦理這些業務的人員坐在那個視窗下面, 你唯一需要做的, 就是到那個視窗下請求服務即可.
埠與名稱服務(naming service)
透過上面現實世界類比的例子, 對於埠的機制, 相信你已經理解得比較深入了. 廣義上講, 埠層也可以視作一個 naming service(名稱服務), 這與比如 spring cloud 中的 eureka 裏的機制本質上是一樣的, 只是這個 name 就是一個抽象的數位, 比如 80. 80 就代表了一個 web 服務, Nginx 之類的 web server 繫結並監聽就相當於把自身提供的 web 服務註冊於其上.
DNS 網域名稱系統其實也是 naming service, 你透過 xiaogd.net 這個名字(name), 就能獲取到我所提供給你的網頁服務.
類似的還有 java 裏的 JNDI 等, 把一個名字與一個服務關聯起來, 比如一個名字就代表一個資料來源(資料庫連線)之類的.
埠與 IoC(控制反轉)
廣義上, 埠的上述機制也是控制反轉(Ioc: Inversion of Control)思想的一種體現, 如果客戶端需要知道伺服端的行程 ID, 實際上就被伺服端控制了, 畢竟我伺服端在哪個 ID 上提供服務, 你就得把你的請求發到相應的 ID 上來;
而有了埠這一中間層呢? 作為客戶端, 總是把請求發到對應埠上, 並要求伺服端繫結並監聽那些埠以及作出響應, 你伺服端是反過來被我客戶端所控制, 我客戶端發到哪個埠, 你伺服端就要去相應埠上監聽並響應.
大家可以體會一下這種轉變. 這種設計或思想在編程領域其實是特別重要的, 在很多其它地方都有體現.
因為瀏覽器總是把 web 請求發到了 80 或 443 埠, 這就要求一個 web server 行程去監聽這些埠. 比如在我的伺服器上, web server 是 Nginx, 它啟動之後就會去監聽 80 和 443 埠, 任何想要存取我的主頁的人, 並不需要知道我的 Nginx 行程 ID 是啥, 借助於埠這一間接層, 你就能夠與我的 Nginx 行程通訊, 並獲取你想要的東西.
事實上你可以這麽認為, 瀏覽器實際上只是在與埠通訊, 埠層再把這些請求委托(delegate)或代理(proxy)給相應的 web server 去處理, 埠的角色就是一個中間人, 一個間接層.
再論缺省埠
現在, 我們應該明白了, 埠是必要的了, 當然, 對最終的使用者來說, 則不需要知道這些實作的細節, 對於他們, 應該遵循最小知識原則, 知道得越少越好.
如果你一定要讓使用者在輸入 url 的過程中輸入埠, 又或者要輸入個 www 等等, 使用者就要給你扔過來"十萬個為什麽"了...
為什麽要加個 443?
為什麽不是 334, 443是啥意思?
為什麽一會兒是 80, 一會兒又是 443?
為什麽加個 www, 啥意思?
為什麽末尾還加個斜杠, 不加會死嗎?
...
惹不起, 惹不起...
還記得前面說的, 使用者是笨蛋, 使用者是懶漢嗎?
這裏又要參照一句電腦世界的名言了: 程式設計師和上帝打賭要開發出更大更好連傻瓜都會用的軟體, 而上帝卻總能創造出更大更傻的傻瓜。目前為止,上帝贏了。
Programmers are in a race with the Universe to create bigger and better idiot-proof programs. The Universe is trying to create bigger and better idiots. So far the Universe is winning.
說句心裏話, 很多時候, 使用者能記住你的網域名稱就阿彌陀佛了, 你就該燒高香了, 你還想使用者記住你的埠, 真的想多了...
另一方面, 說到這裏我們應該也能明白了, 那就是理論上, web 服務實際上可以構建在任何埠之上. 比如在本地開發的時候, 使用者只有你自己, 那當然你可以隨便挑一個埠, 比如 8080, 只要自己知道就好了或頂多告訴另一個與你配合的前端同事.
同理, 其它非 web 的服務, 比如 ftp 服務, 也不一定說非得在 21 埠上等等; mysql 服務的埠同樣可以調整為 3306 之外的埠.
又或者說, 你想提供一個服務, 但只想小範圍內的人知道, 你可以挑一個很偏門的埠, 這樣一般人只輸一個網域名稱就沒法存取到你的服務了.
比如有人想偷偷提供一些服務, 放一些廣淫民群眾喜聞樂見的小視訊啥的...刑法警告, 後果自負!! 別說我沒有提醒你.
埠與 TCP/UDP 協定
前面一直在說, 什麽 3306 埠, 80 埠, 443 埠, 其實嚴格來說, 埠是分 TCP 埠和 UDP 埠的, 不過多數時候遇到的都是 TCP 埠, 但 TCP 80 埠和 UDP 80 埠是不同的埠.
UDP 的 80 埠, 包括 443 埠其實被保留了, 目前的 http 協定只構建在 TCP 協定之上.
當然, 理論上講, 在 UDP 上構建 http 也不能說就完全不行, 畢竟, 無論 UDP 還是 TCP 都是構建在 IP 協定之上, 總之呢, 電腦的世界沒什麽是不可能的, 而且似乎真有人在做這些嘗試, 不過這就屬於兩小母牛對屁股--比較牛逼的範疇了, 深水區了, 咱也不懂, 不多說了.
還有一點, 對於行程間的埠通訊, 實際上是對稱的, 也即是說, 伺服器的響應也是先回到一個客戶端的埠上.
如果你用 Windows 10 系統, 可以在 工作管理員 > 效能 > 開啟資源監視器 > 網路 > TCP 連線, 點選下遠端埠可以按照從小到大排列, 通常就可以看到 443 的相關連線了, 可以看到左邊有一欄本地埠, 一個 TCP 連線總是有一個遠端埠, 一個本地埠:
當發起一個 TCP 連線時, 客戶端首先自己先隨機挑選一個沒有被使用的埠作為伺服器響應的接收埠, 比如 38672. 在一個 TCP 的包裏, 無論是握手包還是後續的封包, 包頭部份最重要的兩個欄位, 一個就是源埠(source port), 比如 38672; 另一個就是目標埠(destination port), 比如 80, 或者 443.
可以這樣看, 伺服器的響應也是先回到源埠, 比如 38672 上, 源埠再轉給最終的行程, 比如瀏覽器.
而對於一個 IP 包, 同樣的, 包頭部份最重要的兩個欄位, 一個就是源IP(source IP); 另一個就是目標 IP(destination IP).
而 TCP 包會作為 IP 包的封包被打包到 IP 包裏面, 也一個 IP 包裏其實包含了 IP + 埠.
IP 加埠再加上埠與行程間的關聯, 分屬兩個不同主機間的行程就能透過 TCP(UDP)/IP 協定愉快地進行行程間的通訊(IPC)了.
當然了, 同一個主機間的行程也同樣可以利用這套機制. 但同一個主機間還可以有其它選擇, 這個具體看各個作業系統是否提供相關機制及支持. 而 TCP/IP 屬於廣泛套用的標準協定, 從而得到了廣泛支持.
因為篇幅關系, 關於這樣 TCP 協定等的細節, 以及包括 Socket, 連線等概念, 以及虛擬主機, 反向代理等等就不再展開去說, 如果你感興趣, 歡迎留言, 後續會考慮再寫一些文章去介紹.
同樣因為篇幅的原因以及同時我也不是電腦網路及協定方面的專家, 關於埠方面的, 如果有什麽說得不到位, 或不正確的地方, 歡迎留言指正, 關於埠方面的介紹就到這裏.