點選「 IT碼徒 」, 關註,置頂 公眾號
每日技術幹貨,第一時間送達!
ChatGPT的問世,在科技圈刮起了一股AI之風,各類人工智慧驅動的自然語言處理模型就紛紛冒出來了,它們可以理解和學習人類的語言跟人類進行對話,並能根據聊天的上下文來進行互動。目前ChatGPT-4在某些專業知識領域已經達到甚至超過博士生的水平了。在轉譯、創作、知識問答、圖片生成、視訊剪輯、編程、測試、檢驗等等領域,AI大模型可謂大放異彩!網上也議論紛紛,說以後AI要淘汰這個職業,那個職業的,搞得大家都人心惶惶的。實際上,AI大模型還是有一些局限性的,難以處理過於復雜的任務。但AI大模型的發展已經是大勢所趨,不可逆轉,它將深刻改變我們的工作和生活方式,相信大家都深有感觸。因此,我們要積極擁抱AI大模型,不斷提升自己的AI技能,與時俱進。
作為一個程式設計師,更應該緊跟技術的發展,才不會被淘汰,我們在透過大模型幫助我們解決問題的同時,也應該更近距離的去接觸大模型,安裝測試一些開源大模型,這樣才能更深刻的理解大模型。
本次測試我們選擇了 阿裏最新開源的通義Qwen2大模型 ,其主要有以下優勢:
最新釋出的Qwen2系列效能很強,在十多個大模型權威測評榜單一舉奪冠,超越Llama3,且作為一款開源模型,在各項測評中效能均超過文心4.0、豆包pro等閉源模型;
同時,Qwen的開源生態非常好,LLaMA-Factory、vLLM、Ollama等開源平台和工具都可支持;
通義的開源頻率和速度全球無二、模型效能也不斷前進演化,且多次登頂HuggingFace的開源大模型榜首,開發者口碑很好。
作為對比,我們會先安裝Qwen1.5。下面是本次詳細安裝測試步驟,帶領大家
更近距離體驗大模型的魅力。
1
下載Ollama工具
官網: https://ollama.com
Github: https://github.com/ollama/ollama
開始測試前,我們先介紹一款工具, Ollama ,一個開源的大模型工具框架,它能在本地輕松部署和執行大型語言模型,如Llama 3, Phi 3, Mistral, Gemma,Qwen。它是專門設計用於在本地執行大型語言模型。 Ollama 和LLM(大型語言模型)的關系,有點類似於docker和映像,我們可以在 Ollama 服務中管理和執行各種LLM,它將模型權重、配置和數據捆綁到一個包中,最佳化了設定和配置細節,包括GPU使用情況。
透過該工具,我們可以大大簡化環境部署等問題,省去許多麻煩。
工具下載可以去官網 根據自己的電腦系統,直接下載。
|
|
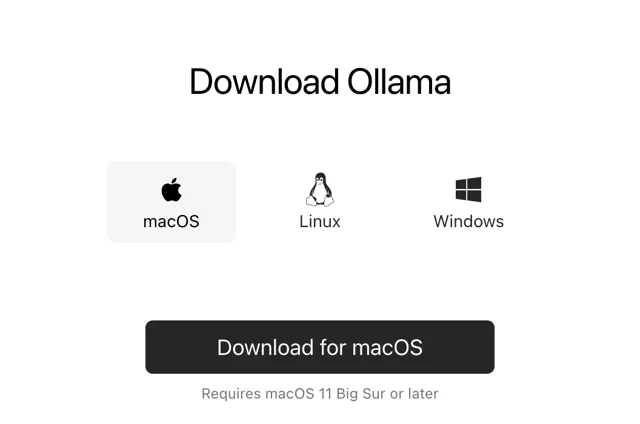
點選圖片 檢視大圖
下載速度相對較慢,大家耐心等待下。
2
安裝
1、安裝 Ollama
比較簡單,本人是Mac,下載的是一個zip壓縮包,直接解壓安裝,Win和Linux也是一樣的,直接安裝。
|
|
|
|


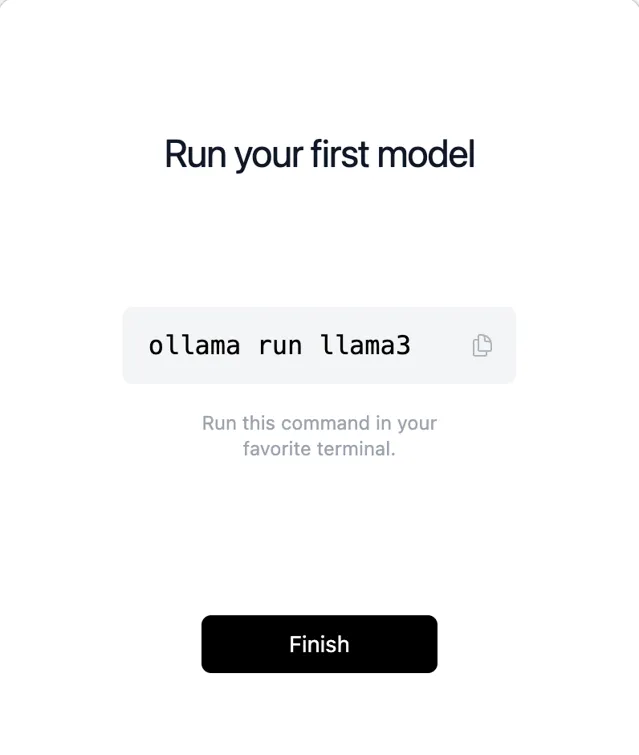
點選圖片 檢視大圖
最後,點選Finish,安裝完畢。
我們需要什麽模型,可以直接在ollama.com 網站搜尋我們需要下載的模型, 這裏首先使用的是 阿裏開源的通義千問大模型Qwen ,我們可以在網站搜下Qwen,如下:
|
|
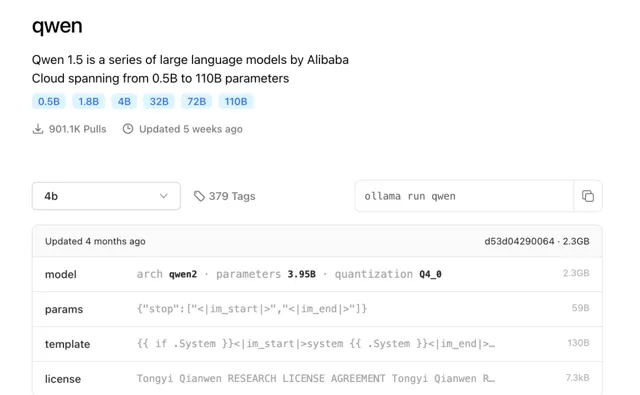

點選圖片 檢視大圖
可以看到目前有多個不同參數訓練的Qwen開源模型,不同數值對應不同的參數大小,第一次使用,先從最小的,使用了模型1.8b(18億參數)。整個模型不到2G的大小。
具體操作,開啟終端直接執行命令,下載速度比較快。
ollamarunqwen:1.8b
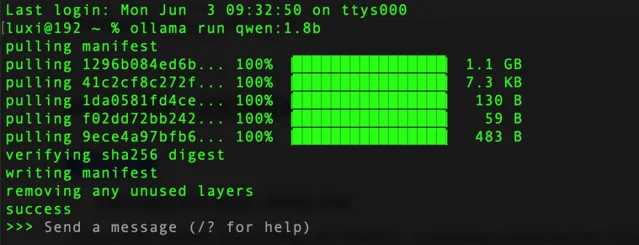
看到success表示已經安裝完成,我們可以直接在終端下使用,進行提問。

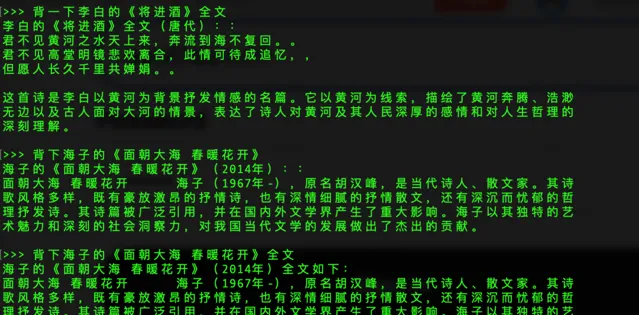
可以看到Qwen-1.8b的回答並不是很理想,初級版本明顯問題較多,我們先放著,等下再下載其他更先進更準確的模型測試。
2、安裝Docker(可選, 更好的體驗 )
終端下操作,體驗並不是很好,想要更好的體驗,我們可以安裝Docker,並啟動open-webUI,這樣我們可以在瀏覽器上使用自己下載的大模型,Docker的安裝比較簡單,這裏不在過多介紹,基本是傻瓜式安裝,官方下載。
地址: https://www.docker.com/products/docker-desktop/
安裝時配置和註冊資訊我們都可以直接跳過。如果無法存取,請開魔法。
|
|

點選圖片 檢視大圖
3、安裝Open-WebUI
安裝完畢Docker,我們開啟終端,執行open-webui安裝口令,如下:
docker run -d -p3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
|
|
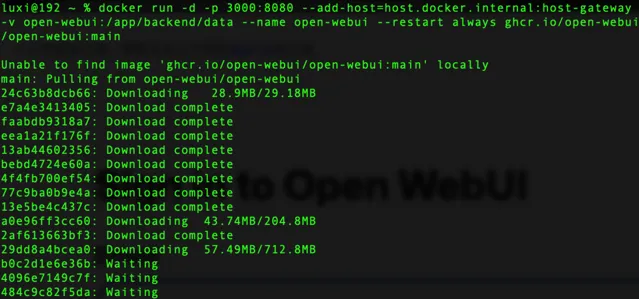
點選圖片 檢視大圖
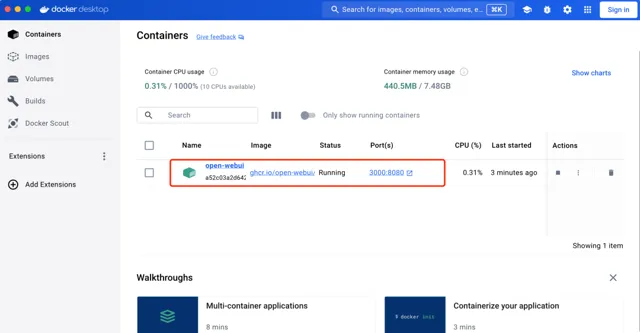
需要安裝相應的元件,耐心等待下,下載完。我們可以透過Docker工具看到執行的open-webui,瀏覽器存取地址: http://localhost:3000/auth/
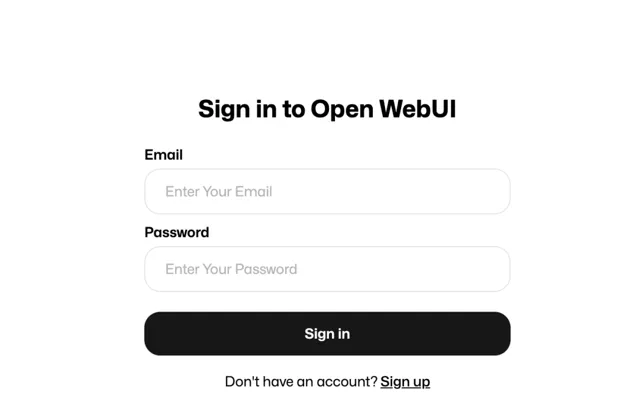
首次登陸,需要先點選Sign up註冊,隨便註冊下,進入到管理後台。
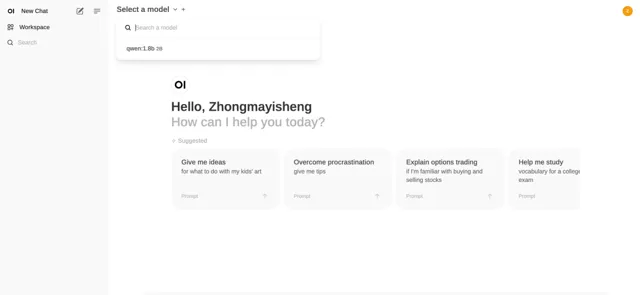
界面是不是有點似曾相識,沒錯,和GPT後台很相似。同樣的,左上角可以選擇我們安裝的Qwen模型,如果我們安裝多個模型的話,可以切換不同模型使用。

4、添加更先進的模型(Qwen2-7b)
因為剛才安裝的1.8b,回答效果並不理想,這次我們添加剛剛開源的 通義千問Qwen2-7b ,70億模型,大小在4G左右(當然,還有更先進,大家根據自己的電腦配置選擇)
ollamarunqwen2:7b

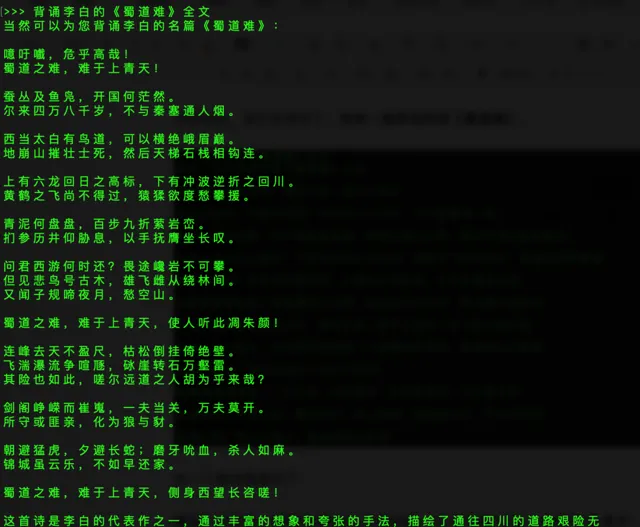
安裝完成,我們在測試下, 先來一首李白的詩【蜀道難】 。
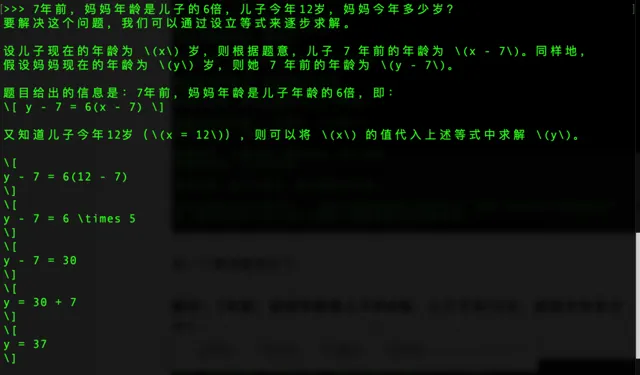
來一個演算法題測試下
提問:7年前,媽媽年齡是兒子的6倍,兒子今年12歲,媽媽今年多少歲?
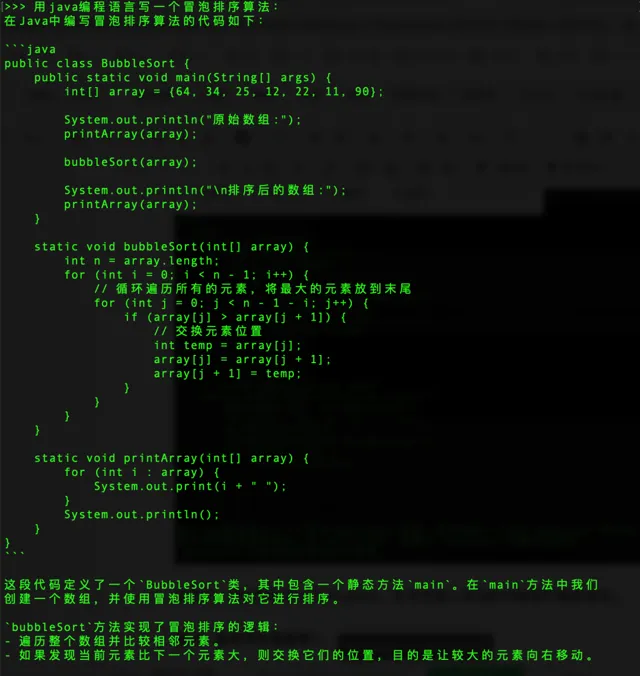
再來一個編程
提問:用java程式語言寫一個氣泡排序演算法:
當然了,我們同樣可以開啟webUI,在瀏覽器上來回的切換我們模型使用。
提問:如何評價陳獨秀?

可以看出來,相比之前模型,Qwen-14b模型很明顯理解能力和準確性要提升了許多,回答內容也更加優質。當然還有更先進的模型,像Qwen-32B,Qwen-72B和Qwen-110B,以及文章開頭提到的Qwen2系列,也有不同尺寸,完全能夠滿足我們的需求,都可以按照上述方法部署。
3
最後
好了,今天的部署測試就到這裏。 是不是很香,很方便,再也不用到處註冊帳號,申請試用了。現在完全可以自己搭建一個大模型,在本地就可以使用大模型。馬上自己操作體驗一下吧!!











