點選「 IT碼徒 」, 關註,置頂 公眾號
每日技術幹貨,第一時間送達!
今天給大家介紹一款 Python 爬蟲計畫,支持小紅書爬蟲,抖音爬蟲, 快手爬蟲, B站爬蟲, 微博爬蟲...。
❝
目前能抓取小紅書、抖音、快手、B站、微博的視訊、圖片、評論、點贊、轉發等資訊。
❞功能列表
下面不支持的計畫,相關的程式碼架構已經搭建好,只需要實作對應的方法即可
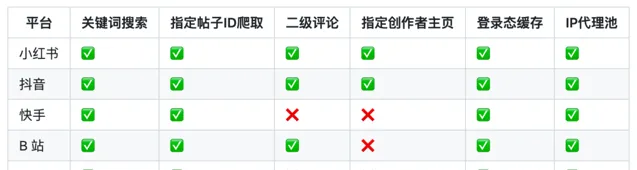
使用方法
建立並啟用 python 虛擬環境
# 進入計畫根目錄
cd MediaCrawler
# 建立虛擬環境
# 註意python 版本需要3.7 - 3.9
python -m venv venv
# macos & linux 啟用虛擬環境
source venv/bin/activate
# windows 啟用虛擬環境
venv\Scripts\activate
安裝依賴庫
pip3 install -r requirements.txt
安裝 playwright瀏覽器驅動
playwright install
執行爬蟲程式
### 計畫預設是沒有開啟評論爬取模式,如需評論請在config/base_config.py中的 ENABLE_GET_COMMENTS 變量修改
### 一些其他支持項,也可以在config/base_config.py檢視功能,寫的有中文註釋
# 從配置檔中讀取關鍵詞搜尋相關的貼文並爬取貼文資訊與評論
python main.py --platform xhs --lt qrcode --type search
# 從配置檔中讀取指定的貼文ID列表獲取指定貼文的資訊與評論資訊
python main.py --platform xhs --lt qrcode --type detail
# 開啟對應APP掃二維碼登入
# 其他平台爬蟲使用範例,執行下面的命令檢視
python main.py --help
數據保存
支持保存到關系型資料庫(Mysql、PgSQL等)
執行 python db.py 初始化資料庫資料庫表結構(只在首次執行)
支持保存到csv中(data/目錄下)
支持保存到json中(data/目錄下)
免責聲明
❝
大家請以學習為目的使用本倉庫,爬蟲違法違規的案件:https://github.com/HiddenStrawberry/Crawler_Illegal_Cases_In_China
本倉庫的所有內容僅供學習和參考之用,禁止用於商業用途。任何人或組織不得將本倉庫的內容用於非法用途或侵犯他人合法權益。本倉庫所涉及的爬蟲技術僅用於學習和研究,不得用於對其他平台進行大規模爬蟲或其他非法行為。對於因使用本倉庫內容而引起的任何法律責任,本倉庫不承擔任何責任。使用本倉庫的內容即表示您同意本免責聲明的所有條款和條件。
❞開源地址
https://github.com/NanmiCoder/MediaCrawler
— END —
PS:防止找不到本篇文章,可以收藏點贊,方便翻閱尋找哦。
往期推薦











