
點選上方↑↑↑「OpenCV學堂」關註我
來源:公眾號 新智元授權
【導讀】 最近,PyTorch團隊首次公布了開發路線圖,由內部技術文件直接修改而來,披露了這個經典開源庫下一步的發展方向。
如果你在AI領域用Python開發,想必PyTorch一定是你的老朋友之一。2017年,Meta AI釋出了這個機器學習和深度學習領域的開源庫,如今已經走到了第7個年頭。
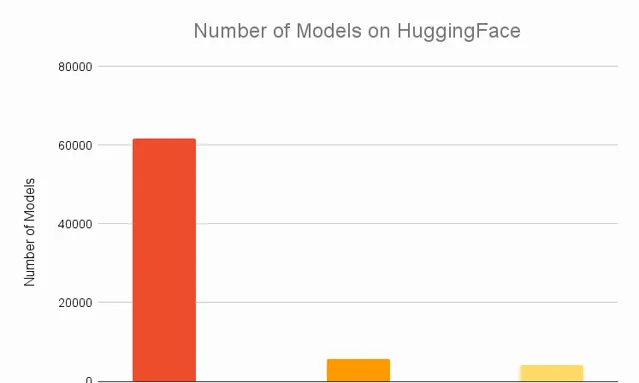
根據Assembly AI 2021年的統計數據,HuggingFace上最受歡迎的top 30模型都能在PyTorch上執行,有92%的模型是PyTorch專有的,這個占比讓包括TensorFlow在內的一眾競爭對手都望塵莫及。
就在7月10日,PyTorch的工程團隊首次公開釋出了他們的路線圖文件,闡述2024年下半年的發展方向。
Meta共同創始人、領導PyTorch團隊的Soumith Chintala在推特上官宣了這個訊息。
他表示,希望公開工程師們的研發動機和目標。
「雖然所有PyTorch開發都在GitHub上公開,但各個PyTorch附屬公司的團隊編寫的實際規劃和路線圖文件並不公開,因此我們決定做出改變,以提高透明度。」
PyTorch團隊的技術計畫經理Gott Brath也在論壇中發表了類似的聲明。

我們一直在考慮,如何分享團隊在PyTorch上所做的工作的路線圖。我們每半年進行一次規劃,因此這些是我們針對PyTorch中多個關鍵領域的2024年H2 OSS計劃的一些公開版本。
這些檔基本就是PyTorch團隊內部的文件和工作規劃,刪減掉了一些內容就釋出出來成為路線圖,其中涉及PyTorch的如下幾個方面:
- 核心庫與核心效能
- 分布式
- torchune、Torchrec、TorchVision
- PyTorch Edge
- 數據載入(DataLoading)
- 編譯器核心及部署
- 開發者基礎設施
每個文件都至少包含三個部份的內容,以OKR的思路展開:
- 背景
- Top5關註領域及目標:目標、關鍵結果、已知或未知風險以及相應緩解措施(最多一頁)
- 提升工程水平的Top3~5個方面:BE Pillar分類、目標、指標/狀態/具體目標、已知或未知風險以及緩解措施、影響/成本、優先級/信心程度(最多一頁)
其中BE Pillar可以看作Meta寫給開發團隊的「五句箴言」,具體內容是:
Better Code, Better Doc, Empowering teams, Modern Code, Better Architecture
「最多一頁」的規定不知道有沒有戳到卷文件長度的開發人員,畢竟文件貴精不貴長,將眾多開發需求精簡到一頁的內容不僅節省同事時間,也十分考驗撰寫者的功力。
此外,文件中也可以看出Meta開發團隊的一些優秀思路,比如重視各個模組團隊的協作、重視和外部合作夥伴的API整合和共同開發,重視與開源社群和開發者的互動。
當推出ExecuTorch這樣的新程式碼庫,或者想要提升PyTorch編譯器影響力時,團隊一般都會從兩方面思路入手:一是鉚足力氣提升效能,把目標直接頂到SOTA;另一方面從深度整合入手,提供更多開箱即用的案例。
或許,這些都是Meta多年來在開源領域如魚得水、風生水起的關鍵所在。
以下是各個文件內容的部份截取和概括。

原文地址:https://dev-discuss.pytorch.org/t/meta-pytorch-team-2024-h2-roadmaps/2226
核心庫與核心效能
文件中涉及到的核心庫包括TendorDict、torchao、NN、TorchRL等。
效能方面,PyTorch團隊提出了在模型訓練和推理方面實作SOTA效能的目標,措施包括引入架構最佳化技術和高效能kernel,與整個PyTorch技術棧形成搭配組合。
過去一年的時間見證了GenAI的快速發展,許多支持研究領域進行開發的外部庫應運而生,但其中很多並不直接依賴PyTorch,這會威脅到PyTorch在科研領域的主導地位。
為了重新跟上節奏,PyTorch將為量化、稀疏化、MoE和低精度訓練等常用開發技術提供支持,包括構建模組和API(主要整合在torchao中),幫助各類Transformer架構的模型提升效能。
torchao庫可以支持研究人員在PyTorch框架內自訂高效能的dtype、layout和最佳化技巧,將使用範圍擴充套件到訓練、推理、調優等各種場景。
此外,核心庫的更新將包括以下方面:
- 推出的自動最佳化庫torchao已經取得了突破性的成功,下一步提升其程式碼組織性,並將其中的數值運算與核心庫分開
- 解決TendorDict的核心模組性,支持載入/儲存的序列化,並使其在eager模式下的執行速度提高2倍
- 繼續上半年在記憶體對映載入(memory mapped load)方面的成功,繼續提升模型載入/儲存的效能和安全性
- 將TorchRL的開銷降低50%
- 加入對NoGIL的核心支持
- 修復使用者反映的TORCH_env變量不起作用的問題
文件中還提及了要實作對nn.transformer模組的棄用,表示會釋出一系列教程和用例,展示如何使用torch.compile、sdpa、NJT、FlexAttention、custom_op、torchao等模組構建Transformer。
分布式
LLM的預訓練通常橫跨數十個甚至上千個GPU,而且由於模型的參數規模逐漸增大,推理和微調也很難用單個GPU完成。
因此,PyTorch下一步對「分布式」的布局全面涵蓋了訓練、推理、微調這三個環節,提出要達成超大規模分布式訓練、高記憶體效率的微調、內送流量備援容錯機制機分布式推理。
訓練
PyTorch原生支持的並列模式主要包括以下幾種:
- 完全分片數據並列(full sharded data parallel,FSDP)
- 混合分片數據並列(hybrid sharding data parallel,HSDP)
- 張量並列(tensor parallel,TP)
- 流水線並列(pipeline parallel,PP)
- 序列並列(sequence parallel,SP)
- 上下文並列(context parallel,CP)
PyTorch希望在TorchTitan中將各種並列方式進一步模組化,讓開發者可以自由組合,根據需要實作N維並列。

文件中特別提到,對MoE和多模態這兩種新興的架構需要添加支持,比如專家並列、路由演算法的最佳化。
除了TorchTitan本身的更新,分布式團隊還需要與編譯器團隊進一步緊密合作,更好地與torch.compile模組整合,為大規模分布式場景帶來額外的效能提升。
微調與推理
微調:聯合torchtune,將FSDP2 LoRA/QLoRA方案投入使用,以及支持模型狀態字典的NF4量化
推理:PP和DP已經成為分布式API的核心,下一步需要關註torchtitan的分布式推理,支持大模型PP+異步TP方式,將給出案例展示
文件中還提到,會將HuggingFace的推理API從PiPPy遷移到PyTorch(由HuggingFace完成)。
torchtune、TorchRec、TorchVision
torchtune
torchtune的推出旨在幫助使用者更方便微調LLM,這也是官方給出的Llama模型微調的方案。
torchtune定義的「微調」範圍非常廣,主要可以概括為三類場景:
- 對特定領域數據集或者下遊任務的模型適應
- 獎勵和偏好建模,比如RLHF、DPO等
- 包含蒸餾與量化的訓練過程
下半年的更新將支持為agent工作流進行的微調,同時著重關註微調效能的提升。
團隊會與compile、core、distributed等模組進行合作,提供高效率微調,並在PyTorch生態內建立有代表性的微調效能基準。
由於torchtune也是一個較新的開源庫,因此與開源社群的互動也必不可少。
文件提出釋出部落格文章和教程、舉辦技術講座等方式,提升使用者的理解;並會定義量化指標,衡量torchturn在LLM生態中的貢獻份額。
除了開源社群,torchtune還會與至少一個合作夥伴整合,參與到它們的社群中,以促進torchtune的使用。
TorchVision
TorchVision作為CV領域內的絕對主宰者,技術也相對成熟,因此路線圖中提出的更新很少。
團隊將繼續在預處理方向努力,在影像編碼/解碼空間中支持更多格式(如WebP、HEIC)和平台(如CUDA),並提升jpeg格式在GPU上的編碼/解碼效能。
TorchRec
TorchRec旨在提供大規模推薦系統中常用的稀疏性和並列性原語,將秋季推出第一個穩定版本TorchRec 1.0。
Edge
目前,開源庫ExecuTorch已經推出了Alpha版本,主要依賴torch.compile和torch.export,用於支持行動裝置和邊緣裝置(如AR/VR、可穿戴裝置)上的模型分析、偵錯和推理。
下半年,Edge團隊將推出xecuTorch的Beta版本,同時為Meta的Llama系列模型和其他開源模型提供PyTorch生態內的解決方案。
關鍵目標中主要涵蓋兩個方向。一是為裝置上AI提供基礎功能和可靠基礎設施,包括:
- 確保C++和Python的API穩定性
- 實作一系列核心功能:支持模型壓縮、代理緩存位置管理、數據和程式分離
二是為這個新生的程式碼庫保駕護航,培育開源社群內的影響力,同時與Arm、Apple 和Qualcomm等公司保持良好合作關系。
其中社群影響力的目標甚至被量化到,要求程式碼在GitHub上得到3k標星,500次複制(fork)。有興趣的吃瓜群眾可以去持續關註一下,看看團隊能不能在年底完成這個OKR。
數據載入
基於Apache Arrow格式的HuggingFace datasets庫憑借無記憶體限制的高速載入/儲存,近幾年異軍突起,似乎搶走了PyTorch相關功能的風頭。
數據載入的文件中開篇就提出了雄心壯誌,要讓TorchData庫再次偉大,重新確立PyTorch在數據載入方面的主宰地位。
要達到這個目標,就需要讓相關功能變得靈活、可延伸、高效能、高記憶體效率,同時實作傻瓜式操作,支持各種規模的多模態訓練。
具體的更新目標包括以下幾個方面:
- DataLoader的功能開發和介面都將貫徹GitHub優先的原則,DataPipes和DataLoader v2則將被逐步被棄用、刪除
- 確保TorchTune、TorchTitan、HuggingFace、TorchData之間的清晰邊界和良好互通性,支持多數據集、多模態數據載入
- HuggingFace使用StatefulDataLoader的API,確保相容性,及時更新樣例和測試用例
編譯器核心及部署
PyTorch的編譯器核心功能經過多年發展已經趨於完善,目前亟待彌補的只是對LLM和GenAI領域的更深度整合和更多最佳化支持。
路線圖提出,要將torch.compile()函式帶到LLM和GenAI的使用周期的各個方面(推理、微調、預訓練),讓重要模型在發行時就搭載原生的PyTorch編譯。
為了實作這個目標,文件提出了很多具體措施,比如與torchtune與TorchTitan團隊合作,提升編譯效能,並在下半年釋出至少兩個高知名度模型的原生PyTorch編譯版本。
此外,編譯器可能添加視覺化功能,在non-eager訓練模式下生成表達前向計算/後向傳播過程的模型圖。
使用者支持方面也有諸多規劃,比如提升系統的監控性和可觀察性,幫助戶自行偵錯編譯問題。關鍵目標還包括建立使用者支持團隊,針對幾個關鍵領域(數據類、上下文管理等),解決開發者在GitHub等平台上釋出的問題。
參考資料:
https://dev-discuss.pytorch.org/t/meta-pytorch-team-2024-h2-roadmaps/2226
https://x.com/soumithchintala/status/1811060935211049046
https://www.assemblyai.com/blog/pytorch-vs-tensorflow-in-2023/
OpenCV4系統化學習

深度學習系統化學習

推薦閱讀












