作者 | Aidan McLaughlin
譯者 | 彎月 責編 | 蘇宓
出品 | CSDN(ID:CSDNnews)
假設我們能夠自動化 AI 研究,結果會怎樣?假設我們不必等待 2030 年的超級集群,就能治愈癌癥,結果會怎樣?假設超級人工智慧(ASI) 就在我們身邊,情況又會如何呢?
賦予基礎模型「搜尋」的能力(即更長時間的思考能力)可能會顛覆規模定律,改變 AI 的發展軌跡。
Leela 的終結
2019 年,一組研究人員構建了一台具有突破性的西洋棋電腦,名叫Leela Chess Zero(萊拉西洋棋零),名字中包含「零」是因為她只知道規則。這台引擎透過與自己對弈數十億次,完成了西洋棋的學習。她的走法顛覆了幾個世紀以來人類建立的西洋棋規則。她富有創造性,並願意做出長期犧牲。Leela 玩弄她的對手,並展現出一些奇怪的人類傾向。她甚至贏得了世界冠軍。然而,後來她被Stockfish擊敗了。
我愛 Leela。我投入了數年的時間來了解和研究這個引擎,並做了很多基準測試。小時候,我總幻想遇到超級智慧的外星人,然後他們教我如何下棋。觀看了Leela的棋局,我發現我找到了答案。
當然,Leela 的魔力在於深度學習。她透過自學,獲得了更深入的象棋表征,遠勝人類的寫死。多年後,我仍然認為 Leela 是一個慘痛的教訓。Leela 摒棄了人類的傲慢,並自行解決問題。
早在規模定律流行之前,Leela 就證明了這一點。2018 年,我和團隊中的其他人註意到,大型網路始終優於小網路。我們甚至觀察到了一些顯著的湧現特性,大型網路似乎能夠在沒有明確指示或搜尋的情況下「預見」幾步。
2020 年,Leela 團隊競相訓練更大的網路。他們透過企業捐贈和朋友的 GTX 1070獲得了計算資源。我們跟蹤了許多自我對弈指標,就像今天許多人跟蹤 Wandb 損失曲線一樣。Leela 最大的模型趕在世界冠軍賽之前出爐了。然而,她遭遇了慘敗。
Stockfish的時代
Stockfish 是 2010 年代西洋棋程式的主宰,它是舊世界 AI 的遺物。2019 年,Stockfish 的程式碼是由人類精心編寫的,他們將自己的對弈知識提煉成了巧妙的數學公式。在2019年的比賽中,Leela的深度學習和白板啟發法驚人地推翻了 Stockfish。那麽,為什麽Leela使用了更大的網路,卻被Stockfish重新奪回了王冠呢?
Stockfish 擁有更好的搜尋。
小時候,爸爸教我下棋。四歲那年,我問他,為什麽他的朋友(一位脾氣古怪的克羅埃西亞特級大師)這麽厲害?我爸回答說:「他能看到很多步棋。」
「看到很多步棋」是我最喜歡的「搜尋」的定義。這正是西洋棋電腦的任務:評估棋盤,然後預見後面的很多步。在西洋棋之外,人類也經常這樣做。在破解一個棘手的數學問題時,你也會使用某種形式的搜尋。
Leela 顛覆了西洋棋,因為她拋棄了人類的西洋棋知識,自學成才。在當時,雖然Stockfish具備處理數十億個棋位的能力,但這根本沒用,因為它對每個棋位的理解受限於它的人類創造者。
為了改進這一點,Stockfish 團隊借鑒了 Leela 的深度學習技術,訓練了一個比頂級 Leela 模型小數百倍的模型。
在這個小模型完成訓練後,他們將其投入到了搜尋管道中,於是 Stockfish 在一夜之間擊敗了 Leela。

Stockfish 完全否定了規模法則。他們反其道而行之,制作了一個更小的模型。但是,由於他們的搜尋演算法更高效,更好地利用了硬體,並且看得更遠,所以他們贏了。
我們由此明白了一個慘痛的教訓: 在深度學習的世界中,你不應該低估 AI 搜尋的力量。
Leela 的搜尋能力不佳,從而失去了世界冠軍。我們本來有機會將搜尋功能添加到大型語言模型,但我擔心沒有人註意到這一點。
搜尋時代
基礎模型,如 GPT-4,缺乏搜尋能力。你不能指望 GPT-4 思考一個月的問題並給出更好的答案。如今,要求模型「逐步思考」可以改善效能,但報酬大幅降低。但是,如果我們賦予現有模型搜尋功能,結果會怎樣?
註意:在後文中,我所說的基礎模型搜尋指的是模型利用推理計算(搜尋),而不是訓練計算(模型擴充套件),以更好地解決問題的能力。
我所交談過的每一位AI研究人員、經濟學家和CEO都極大地低估了賦予基礎模型搜尋能力的重要性。
原因大致如下:
我們不需要規模來解決搜尋問題。
我們可以利用搜尋有針對性地分配計算資源。
我們能夠利用搜尋自動化AI研究。
無需規模
人們普遍認為,我們需要更大的模型才能實作大型語言模型搜尋。Sholto Douglas等人聲稱,我們需要更多的大型語言模型來處理長期思考。而Leopold Aschenbrenner等人則認為,預訓練可能已經包含了搜尋所需的必要因素,我們只需要「稍微擴充套件」和一些額外的標記就可以實作。但是,事實證明,規模並非搜尋的先決條件。
最近,DeepMind研究了沒有搜尋的棋類演算法,並指出這種演算法自然地產生了搜尋行為(預測走步)。研究人員指出,由於棋類已經有了搜尋演算法,為什麽我們還要等待低效的大模型預測後面的走法呢?
此外,文章【Scaling Scaling Laws with Board Games】(棋牌遊戲的擴充套件法則的擴充套件)表明,「訓練時間每額外增加10倍,就可以消除大約15倍的測試時間計算」,這個結果甚至適用於單個神經元模型。請記住,Stockfish用於打敗Leela的模型在規模上小三個數量級。
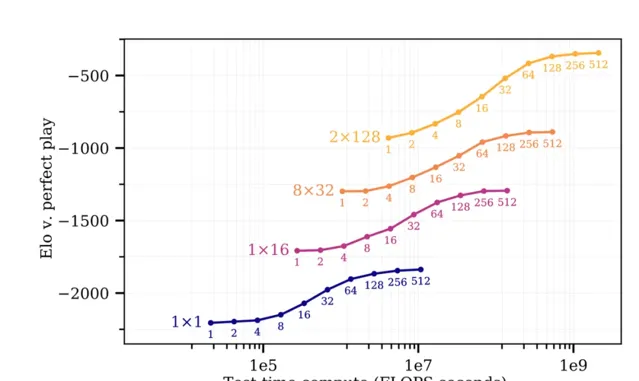
現如今,我們的模型非常龐大(也許是過於龐大了),足以支持搜尋。
雖然很少有人完全理解搜尋的重大意義,但許多人正在致力於此項研究。Demis Hassabis和Sam Altman公開表示,他們希望模型能夠長時間思考。網上有大量關於大型語言模型的文獻資料。在GPT-4釋出後的一年裏,我們看到了許許多多「思維圖譜」、「思維鏈」、「LLM MCTS」等論文。我們會解決搜尋問題。甚至有可能許多已發表的技術已經投入了使用,只是我們還沒有跟上節奏。
有針對性的計算
訓練時間和推理時間計算之間的權衡大致相同。初聽之下,這似乎令人失望。Aidan曾聲稱大型語言模型搜尋將吞噬整個世界。如果推理成本和訓練一樣昂貴,這又怎麽可能實作呢?
簡單來說:
搜尋可以有針對性地分配計算資源:你只需為自己的領域買單。
想象一下,我是輝瑞,我想利用人工智慧研究新藥。在一個具有AI搜尋能力的世界中,我有兩個選擇:
等到2030年,直至OpenAI釋出一個比現在大四個數量級的模型。
使用比現在大四個數量級的推理計算資源。
輝瑞當然會選擇第二個!
有了搜尋功能,輝瑞就不必等待Sam Altman籌集7萬億美元,微軟股票升值,或者國會批準人工智慧支出法案。輝瑞可以自掏腰包,投資推理計算,並立即獲得GPT-8的能力。
假設,輝瑞每年在GPT-4上的支出為10萬美元。
如果他們想利用搜尋功能,馬上獲得2030年超級智慧(ASI)的能力,那麽他們需要將人工智慧預算增加四個數量級,即每年10億美元。
雖然對於一家公司來說,這是一筆巨款,但輝瑞的研發預算高達120億美元!
再次強調,這是為了獲得超級智慧而投入的10億美元。
對於輝瑞來說,這項投資非常值得,因為他們不必等待OpenAI訓練下一個重要模型。對於OpenAI來說,這也是一個好訊息,因為他們的推理可以賺更多錢。雙贏局面。
尚未成熟的超級智慧
下面,我們來簡單地介紹一下搜尋宇宙與規模宇宙的區別。根據Leopold Aschenbrenner的詳細說明,2030年超級智慧的構建方式如下:
各大公司自掏腰包購買大型集群。
這些大型集群能夠推動收入增長。
各大公司獲得巨額貸款,建設更大的集群。
更大的集群再次推動收入增長。
政府介入並建設最大的集群。
然後,模型達到逃逸速度,可以自行進行AI研究。
在沒有搜尋的世界裏,Leopold的模型似乎是合理的。
以下是我的願景:
我們發現搜尋功能可以套用於現有模型。
大型實驗室和政府意識到,他們可以即刻將搜尋套用於進一步的AI研究。
推理計算受到限制:政府或大型實驗室將其限制在安全或AI研究領域。
在搜尋的驅動下,AI不斷進步,並行現了更高效的搜尋演算法和模型架構。
「數據壁壘」問題消失,因為搜尋不需要更多的訓練數據。
智慧爆炸從明年開始,而不是2030年。
盡管一些人承認,搜尋確實可以在一些狹窄領域帶來幾個數量級的增益,但他們似乎忘記了我們很可能會將搜尋首先套用於AI研究。
許多人認為,當人工智慧發展到足夠強大,可以研究自身時,整個人類的科技力量都會騰飛。但正如輝瑞無需等待GPT-8,就可以利用搜尋研究更好的藥物一樣,人工智慧實驗室無需等待更大的模型,也可以利用搜尋研究人工智慧。
當然,我們可能需要打破更多枷鎖,取代自主和主動的人工智慧研究者。但我認為,以GPT-8的智慧水平,一個簡單的聊天機器人就足以加速提升AI的能力。
利用搜尋自動化AI研究有巨大的上升空間。
雖然我懷疑早期的搜尋增強模型可能沒有人類代理,但它們可能是超人類的「扶手椅理論家」,推動了演算法進步。
假設GPT-4花費一萬億個令牌(1500萬美元),發現了一種減少訓練成本3%或增加搜尋效率10%的演算法,那麽這將收獲巨大的報酬。
假設輝瑞公司利用搜尋發現了一種更好的藥物,這雖然也是一種進步,但新藥物對輝瑞的進一步研究並沒有幫助。而對於人工智慧研究來說,更好的演算法將幫助你構建更好的人工智慧。
自我改進的人工智慧並非新概念,這種「科幻」距離我們的生活之近超出了許多人的想象。
總結
如果你認同我的預測,則必須相信:
基礎模型搜尋演算法已存在,這些演算法所能帶來的效能增益並不低於強化學習系統。
相較於模型擴充套件,搜尋可以更高效地將現有資本轉化為智慧。
也許對於許多AI領域的人來說,這兩個說法都很離譜。但與2020年代深入研究的規模定律不同,我們缺乏關於搜尋效能和經濟學的充分證據。以上是我根據自己的遊戲強化學習研究得出的推斷。
2019年,人工智慧研究人員希望電腦在棋牌遊戲中能有更好的表現。透過幾個月的努力,他們意識到了:
一個慘痛的教訓
規模定律
搜尋的力量
以上第一點和第二點得到廣泛的認可,並推動了2020年代AI空前的發展。但我們仍需努力。
原文:https://yellow-apartment-148.notion.site/AI-Search-The-Bitter-er-Lesson-44c11acd27294f4495c3de778cd09c8d
本文為 CSDN 轉譯。
推薦閱讀:












