整理丨王軼群
責編丨唐小引
出品丨AI 科技大本營(ID:rgznai100)
在GitHub研究近900個開源AI工具,對了解人工智慧生態系有什麽提升?一位人工智慧暢銷作家和電腦學家幫助全球開發者們做了大量數據分析。一起來看看這份新鮮出爐的開源AI生態報告。
近期,來自越南的作家和電腦科學家、【設計機器學習系統】作者Chip Huyen(奇普·惠恩)在個人區域網絡頁發文【我從900個最流行的開源AI工具中學到了什麽】,對開源AI工具進行了觀察和總結。
條件限定在Star大於500的倉庫,她透過GitHub搜尋LLM、GPT和Generative AI等關鍵詞,結果分別為590個、531個和38個。數小時後,她找到了896個倉庫,最終獲得了845個軟體倉庫,其中51個是教程和匯總列表,794個是軟體計畫。
Chip Huyen表示:「這個過程是痛苦卻十分有益的。在觀察和總結的過程中,我 更好地了解人們正在做什麽、開源社群的協作程度如何,以及中國的開源生態系與西方生態系的差異。 」
開源AI工具分層解析
新AI堆疊
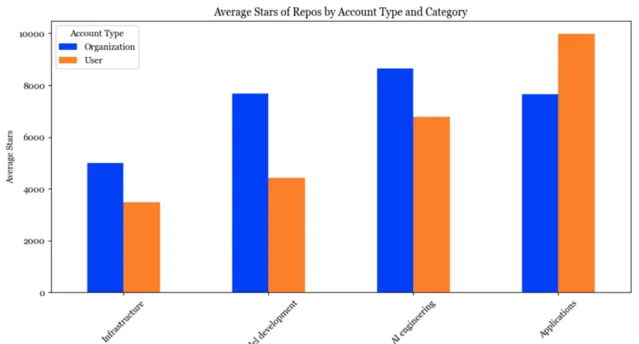
Chip Huyen認為AI堆疊由4層組成:基礎設施、模型開發、應用程式開發和應用程式。
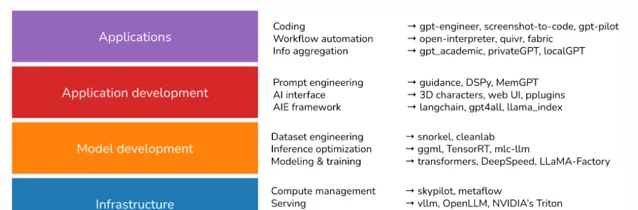
基礎設施層 :AI堆疊的底層是基礎設施,其中包括模型部署(vllm、NVIDIA 的 Triton)、計算管理(skypilot)、向量搜尋資料庫(faiss、milvus、qdrant、lancedb)等。
模型開發層 :提供用於開發模型的工具,包括建模和訓練架構(Transformers、pytorch、DeepSpeed)、推理最佳化(ggml、OpenAI/triton)、數據集、評估等。
套用開發層 :也被稱為人工智慧層。有了現成的模型,任何人都可以在其上開發應用程式,這是過去兩年內執行最多的層,且仍在快速發展。包括提示工程、人機介面、Agent、AIE框架等。
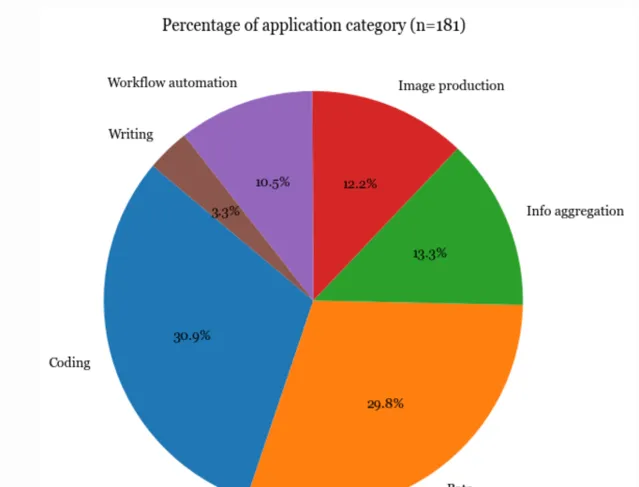
套用層 :有許多開源套用構建在現有模型之上。最流行的應用程式型別是編碼、工作流程自動化、聊天機器人、資訊聚合等。
除了這 4 層之外,Chip Huyen認為還有另一個類別,即 模型倉庫層 。模型倉庫層由公司和研究人員建立,用於共享與其模型相關的程式碼。此類別中的儲存庫範例包括CompVis/stable-diffusion、openai/whisper和facebookresearch/llama。
透過繪制每層內倉庫的累計數,Chip Huyen總結出2023年AI堆疊的變化趨勢。

2023年 套用和套用開發層增長迅速 ,且套用增長最快。
2023年 基礎設施層變化不大 ,僅有微小增長,與其他層的增長水平相差甚遠。
最流行的應用程式型別是編碼、機器人(如角色扮演、WhatsApp 機器人、Slack 機器人)和資訊整合。
人工智慧工程
在套用領域, 提示工程、人機介面、推理最佳化最熱門 。2023年是人工智慧工程年,這一年AI工程發生了爆發式的增長。

Chip Huyen把人工智慧工程分為提示工程、人機介面、Agent和AI工程(AIE)框架。
提示工程 不僅是提示,還涵蓋受約束采樣(結構化輸出)、長期記憶體管理、提示測試和評估等。
人機介面 是為使用者提供與AI應用程式互動的界面,是令Chip Huyen最為興奮的類別。其中越來越受歡迎的界面是:網路和桌面應用程式;瀏覽器外掛程式;承載於Slack、Discord、微信、WhatsApp等聊天應用程式的機器人;開發人員能夠將AI套用嵌入到 VSCode、Shopify 和 Microsoft Offices 等應用程式中的外掛程式。外掛程式方法對於可以使用工具完成復雜任務的人工智慧應用程式來說很常見(Agents)。
AIE框架 是所有開發AI應用程式的平台總稱。其中許多都是圍繞 RAG 構建的,但許多還提供其他工具,例如監控、評估等。
Agent 是一個特殊的類別,因為許多Agent只是復雜的提示工程,由潛在受限的生成(如只輸出預設動作的模型)和外掛程式(如讓Agent使用工具)整合。
模型開發
在 ChatGPT 之前,AI堆疊主要由模型開發主導。2023 年模型開發的最大增長來自於對推理最佳化、評估和參數高效微調(歸屬於建模和訓練)的日益增加的影響力。
推理最佳化一直很重要,但當今基礎模型的規模使其對延遲和成本至關重要。最佳化的核心方法保持不變(量化、低秩分解、裁剪、蒸餾),但特別針對Transformer架構和新一代硬體開發了許多新技術。例如,在 2020 年,16 位量化被認為是最先進的。今天,我們看到了2 位量化,甚至低於 2 位。
同樣,評估一直都是必不可少的,但由於當今許多人將模型視為黑匣子,評估變得更加重要。出現了許多新的評估基準和評估方法,例如比較評估(參見Chatbot Arena)和AI-as-a-judge。
基礎設施
基礎設施涉及數據管理、計算、服務和監控的工具,以及其他平台工作。盡管生成式人工智慧帶來了所有變化,但開源人工智慧基礎設施層或多或少保持不變。這也可能是因為基礎設施產品通常不是開源的。
這一層的最新類別是向量資料庫,包括 Qdrant、Pinecone 和 LanceDB 等公司。然而,許多人認為這根本不應該成為一個類別。向量搜尋已經存在很長時間了。DataStax 和 Redis 等現有資料庫公司不再僅僅為向量搜尋構建新資料庫,而是將向量搜尋引入已有資料庫。
開源AI開發者生態畫像
開源人工智慧開發者分布
開源軟體呈長尾分布,少數帳戶掌握著大量倉庫。
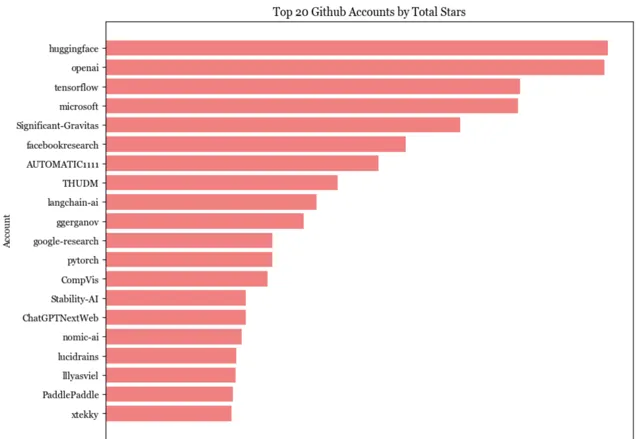
845個儲存庫掌管在 594 個特定的GitHub帳戶上。有20個帳戶至少有4個倉庫。 前20的帳戶共掌管著195個倉庫,占所有統計中的23% 。這195個倉庫總共獲得了165萬顆star。
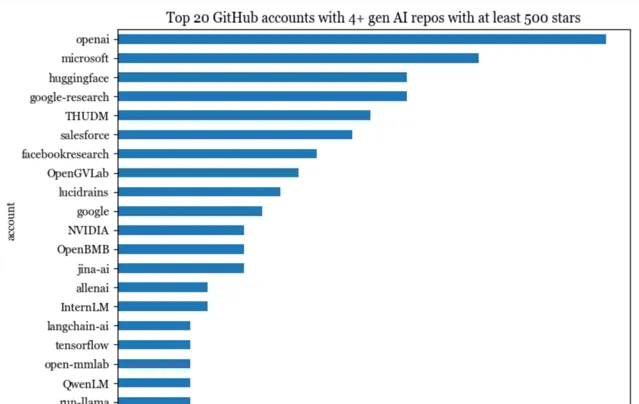
Github上的帳戶可以是組織,也可以是個人。95%的前20帳戶是組織。其中,3個屬於谷歌:google-research, google, tensorflow。
這前20名的帳戶中唯一的個人帳戶是 lucidrains。Star數最多的前 20 個帳戶
中(僅算 gen AI 倉庫),個人帳戶有 4 個:
lucidrains (Phil Wang):能夠以驚人的速度實作最先進的模型。
格爾加諾夫(Georgi Gerganov):物理背景的最佳化大神。
Illyasviel(張呂敏):Foocus 和 ControlNet 的建立者,目前是史丹佛大學博士。
xtekky:建立 gpt4free 的全棧開發人員。
不出所料,在堆疊的地位越低,個人構建起來就越難。基礎設施層的軟體最不可能由個人帳戶啟動和掌管,而超過一半的應用程式由個人掌管。

通常來說,個人發起的應用程式比組織發起的應用程式獲得更多Star。Sam Altman等人推測我們將看到許多非常有價值的個人公司,Chip Huyen認為這是有可能的。
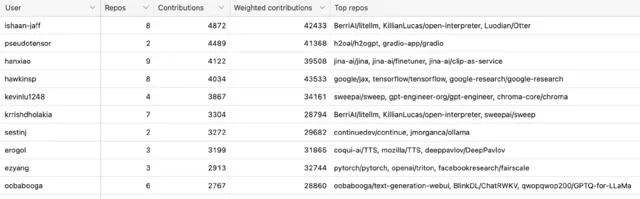
百萬次的送出
超過2萬名開發人員為這845個倉庫做出了貢獻,總計100萬次送出的貢獻!
其中,最活躍的50名開發者的送出次數超過10萬次,平均每人送出次數超過2000 次。
不斷發展的中國開源生態系
GitHub 上有很多針對中國受眾的熱門人工智慧倉庫,其介紹都是用中文編寫的。有針對中文或中文+英文開發的模型的倉庫,例如Qwen、ChatGLM3、Chinese-LLaMA。
雖然在美國許多研究實驗室已經放棄了語言模型的 RNN 架構,但基於 RNN 的模型系列RWKV仍然很受歡迎。
還有一些人工智慧工程工具提供了將人工智慧模型整合到微信、QQ、釘釘等中國流行產品中的方式。許多流行的提示工程工具也有中文範式。
GitHub 上排名前 20 的帳戶中,有 6 個來自中國:
THUDM:清華大學知識工程研究室和資料探勘小組
OpenGVLab:上海人工智慧實驗室通用視覺團隊
OpenBMB:開源社群OpenBMB,由面壁智慧聯合清華大學 NLP 實驗室共同創立
InternLM:來自上海AI實驗室。
OpenMMLab:來自香港中文大學。
QwenLM:阿裏巴巴的人工智慧實驗室,該實驗室釋出了Qwen模型系列。
AI計畫的現象與偏好
短命的計畫:誕生迅速,消亡也迅速
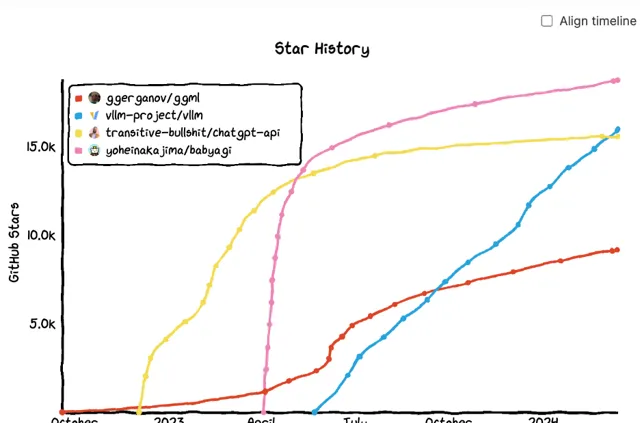
Chip Huyen在2023年看到的一種現象是,許多倉庫很快獲得大量關註,然後又很快消失。這樣的趨勢被她的一些朋友稱之為「炒作曲線」。在這 845 個擁有至少500個GitHub Star的倉庫中,有158 個倉庫 (18.8%) 在過去24小時內沒有獲得任何新star,37 個儲存庫 (4.5%) 在上周沒有獲得任何新star。
下方的範例圖,是兩個此類倉庫與兩個更持久的軟體的增長曲線對比。盡管這裏顯示的這兩個案例已不再使用,但Chip Huyen認為它們具備向社群展示可能性的價值,且作者能夠如此快速地構建產品是很cool的。
Chip最喜歡的想法
Chip Huyen在文章的結尾出列出了自己感興趣的想法:
社群正在開發許多很酷的想法,這是一些我最喜歡的:
批次推理最佳化:FlexGen、llama.cpp
使用Medusa、LookaheadDecoding等技術實作更快的解碼器
模型融合:mergekit
受約束采樣:輪廓、指導、SGLang
專註解決一個問題的計畫也很有價值,例如einops和safetensors
結論
Chip Huyen在分析中囊括了845 個倉庫,但她實際上瀏覽了數千個倉庫。她認為,這份分析有助於全面了解看似勢不可擋的人工智慧生態系。讀者們如果有補充,Chip Huyen會將之添加到列表中。
Chip Huyen
Chip Huyen,一位來自越南的作家和電腦科學家,即時機器學習平台Claypot AI的聯合創始人,MLOps Discord的維護者,曾在NVIDIA、 Snorkel AI和 Netflix構建過機器學習工具,是GitHub的活躍使用者。
畢業於史丹佛大學(Stanford University),獲得電腦科學學士和碩士學位。在史丹佛大學建立並教授CS 329S:機器學習系統設計課程,並著有亞馬遜人工智慧領域暢銷書【設計機器學習系統】。
長期從事人工智慧研究,是機器學習領域專家級人物,在研究過程中,主張機器學習要面向實踐,面向實際,立誌解決當前問題,AI必須要有商業驅動,方能足夠長遠的發展。
相關 連結 :
【What I learned from looking at 900 most popular open source AI tools】
http://t.cn/A6TPU1pM
4 月 25 ~ 26 日,由 CSDN 和高端 IT 咨詢和教育平台 Boolan 聯合主辦的「 全球機器學習技術大會 」將在上海環球港凱悅酒店舉行,特邀近 50 位技術領袖和行業套用專家,與 1000+ 來自電商、金融、汽車、智慧制造、通訊、工業互聯網、醫療、教育等眾多行業的精英參會聽眾,共同探討人工智慧領域的前沿發展和行業最佳實踐。 歡迎所有開發者朋友存取官網 http://ml-summit.org、點選「閱讀原文」或掃碼 進一步了解詳情。












