作者 | 王啟隆
出品 | AI 科技大本營(ID:rgznai100)
由 DeepMind、Google 和 Meta 的研究人員共同創立的舊金山 AI 初創公司 Reka ,昨日推出了一款名為 Reka Core 的新一代多模態語言模型。該模型被標榜為該公司「迄今為止最強大的模型」,用了數千塊 H100 顯卡進行訓練, 從零開始構建一個能與 OpenAI 的 GPT-4 和 Claude 3 Opus 比肩的模型 。
此前,Reka 公司已經推出過 21B 的 Reka Flash 和 7B 的 Reka Edge 模型,效能與 Gemini Pro 旗鼓相當。 作為 Reka 家族系列語言模型中的第三位成員,Core 現已開放使用,其特點在於 能夠理解包括影像、音訊和視訊在內的多種模態 。
比如說,Core 可以看懂近期備受吐槽的「網飛版」【三體】電視劇,甚至用 Python 指令碼模擬 三體問題 。

值得一提的是,盡管 Core 的訓練時間不足一年,其效能已能與 AI 領域內資金雄厚的「三巨頭」——OpenAI、Google 和 Anthropic 的頂級模型相抗衡,甚至超越。
目前 Reka Core 的確切參數數量尚未公布,其模型訓練數據來源於多個渠道,包括公開可用數據、授權數據以及涵蓋文本、音訊、視訊和圖檔的合成數據。 Core 能夠理解多種模態輸入,並在數學、編程等領域提供具有高級推理能力的答案,甚至支持 32 種語言,具備 128,000 個 tokens 的上下文視窗。Reka 的官方部落格寫道, Core 是繼 Google 的 Gemini Ultra 之後第二個覆蓋所有模態(從文本到視訊)並提供高品質輸出的模型 。
下面用三個部份,分別講解 Reka Core 的效能水平、例項演示和這家公司背後的故事。
「 前沿級 」多模態 LLM
Reka Core 訓練封包括文本、影像、視訊和音訊剪輯,並使用了混合語料庫進行預訓練。Reka 模型采用了模組化的編碼器-解碼器架構,支持多種輸入(如文本、影像、視訊和音訊),並以文本形式作為輸出。模型使用了 SwiGLU、Grouped Query Attention、Rotary 位置嵌入和 RMSNorm 等技術,並在訓練過程中使用了不同的數據分布、上下文長度和目標函式來最佳化模型效能。
總的來說,Reka Core 在以下方面展現出了「前沿級」的實力:
多模態理解 :對影像、視訊和音訊的強大情境化理解,是目前僅有的兩款商業化綜合多模態解決方案之一。
大容量上下文視窗 :具備 128K 的上下文視窗,能夠高效精準地處理並回憶大量資訊。
高級推理能力 :包括語言和數學在內的卓越推理能力,適用於需要復雜分析的高級任務。
頂級程式碼生成與代理工作流支持 :作為頂尖的程式碼生成器,其編碼能力結合其他功能可賦能代理工作流。
多語言能力 :預訓練涵蓋 32 種語言,能流暢處理英語及多種亞洲和歐洲語言。
在視訊感知測試中,Core 以明顯優勢(得分 59.3 vs 54.3)勝過唯一競爭對手Gemini Ultra。而在 MMMU 影像任務基準中,Core 得分 56.3,緊隨 GPT-4(56.8)、Claude 3 Opus(59.4)、Gemini Ultra(59.4)和 Gemini Pro 1.5(58.5)。馬斯克的 xAI 近期也推出了具備視覺能力的新版 Grok,僅得分 53.6,仍落後於競爭對手。
在 MMLU 知識任務測試中,Core 得分為 83.2,僅次於 GPT-4、Claude 3 Opus 和 Gemini Ultra。而在 GSM8K 推理基準和 HumanEval 編碼任務中,其分別以 92.2 和 76.8 的分數擊敗了 GPT-4。
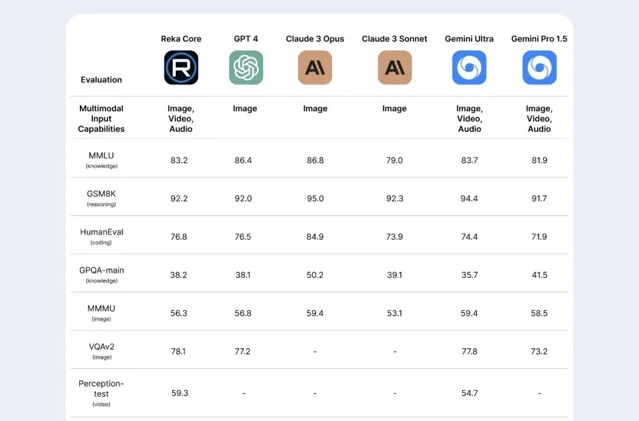
在技術報告中,還展示了獨立第三方進行的「盲測」,即評價者在不知曉系統身份的情況下,根據系統對一系列多模態提示(可能包含影像、文本、音訊等多種型別數據的組合)的響應,表達出自己的偏好。這些偏好數據經過統計計算轉化為 ELO 分數,以此為基礎對參與測試的多模態系統進行排序。我們可以看到,Reka Core 的 ELO 得分為 1130,勝率為 72.2%,而其他模型的得分和勝率則不同。

為了在一年時間內達到如此高水平的效能,Reka 采取了「自頂向下」的方法。這意味著 他們並非先訓練模型再觀察其表現,而是先設定目標效能水平,然後逆向工作 ,確定實作這一目標的最高效路徑,其中涉及數據量、所需 GPU 數量等各個方面。
目前模型 API 及定價如下:輸入 tokens 是每百萬 / 10 美元,輸出 tokens 則是每百萬 / 25 美元。

相比之下,OpenAI 的 GPT-4 Turbo 對輸入 tokens 收費相同,但輸出 tokens 費用為每百萬 tokens / 30 美元。
技術報告連結: https://publications.reka.ai/reka-core-tech-report.pdf
官方部落格連結: https://www.reka.ai/news/reka-core-our-frontier- class-multimodal-language-model
殺出重圍的「第四大」巨頭
口說無憑,目前模型已經處於公開測試,感興趣的讀者可以直接點選下方連結體驗,或是點選下方第二個連結獲取 API。
體驗連結: https://chat.reka.ai/chat(Playground)https://platform.reka.ai/dashboard(API)
此外,Reka 官方也給出了一系列演示,展示了 Reka Core、GPT-4 和 Claude-3 面對同一個問題時產生的不同回答。
問題 1:這是一種什麽動物?

Reka Core : 這是一頭大象,具體來說,由於其耳朵形狀巨大且大致呈非洲大陸形狀,判斷其為非洲象。環境特征進一步佐證了這一點,畫面所展示的是一種類似非洲草原的生態環境,這是非洲特有的草地生態系。大象作為陸地上最大的動物,以其智慧、長壽和復雜的社會結構而聞名。
GPT-4 : 圖片中的動物為大象。它們是大型哺乳動物,以顯著的長鼻、大耳和象牙著稱。大象通常棲息於多種生境之中,包括草原、森林、沙漠和沼澤,主要分布在非洲和亞洲。
Claude 3 Opus : 影像中的動物為大象。畫面展示了一群由成年象和幼象組成的象群,它們正沿著一條穿過草地和樹木的土路行進,背景中可見藍天下的山脈。
這一輪 PK 中,只有 Reka Core 精準辨識出了非洲象這一種類,還依據其耳朵形狀與所處環境(非洲草原)進行了細致的物種分類與生境分析。而 GPT-4 提供了較為全面的大象基本資訊,Claude 3 Opus 則擅長文科,在場景還原與氛圍營造方面更具優勢。
問題 2:這是什麽梗?

Reka Core : 這張梗圖以幽默的方式對比了從不同渠道學習機器學習(ML)和深度學習(DL)的有效性。圖中展示了腦部影像漸次增亮和復混成的過程,象征著知識積累或頓悟的過程。
頂部影像標記為「 從 大學學習 ML、DL」,顯示一個單一色彩的簡單大腦,暗示基礎或初步的理解。第二張圖「從線上課程學習」,則呈現了一個多色、細節豐富的腦部,意味著更豐富深入的學習體驗。第三張圖「從 YouTube 學習」,腦部中心放射光芒,暗示 YouTube 學習如同明燈,能提供廣泛的知識或深刻見解。第四張圖「從閱讀文章學習」,大腦帶有精致圖案和鮮艷色彩,可能意味著文章能提供詳盡且深入的理解。底部影像「從梗圖學習」描繪了一個頭部輪廓,周圍散發強烈光芒,其中的人物正在冥想,戲謔地暗示從梗圖中可以獲取深刻甚至靈性的洞察。
梗圖的笑點在於,通常輕松娛樂而不具備教育性質的梗圖被誇張地表現為最啟迪人心的來源,顯然是為了喜劇效果而使用的誇張手法。
GPT-4 : 此圖是一幅幽默的梗圖,用以表現人們從不同途徑學習 ML 和 DL 時可能達到的不同層次的領悟或理解。每一種學習資源都用一個逐漸更明亮、更復雜的腦部影像來代表,象征更高的理解和覺悟水平:
大學學習 ML、DL:展示標準的顱骨 X 光片配大腦,暗指基礎理解程度;
線上課程:展示部份突出的大腦,表明比大學學習有更深的理解;
YouTube 學習:描繪大腦發出強烈光芒,暗示因 YouTube 平台內容豐富多樣,可獲得更高層級的理解;
閱讀書籍:展示大腦發出強烈光芒並伴有復雜連線和活動跡象,表示透過深入閱讀可獲得全面理解;
梗圖學習:最後一幅圖描繪一個人物正在冥想,周圍環繞著復雜且璀璨的光網路,滑稽地暗示從梗圖中可獲得超然、終極的 ML 和 DL 理解。
梗圖圍繞著這樣一個觀念展開:相較於傳統的學習方式,如 YouTube 視訊和梗圖這類更易獲取且非正式的資訊源,可能意外地提供深刻洞見,盡管是以一種詼諧調侃的方式。
Claude 3 Opus : 該圖列舉了從大學課程到互聯網梗圖等多種學習 ML 概念的方式。
頂部提到從大學課程和線上課程學習,這些都是更為傳統且結構化的學習路徑。
往下則是透過 YouTube 視訊和文章學習,屬於更為非正式且自主引導的學習方法。
最後幽默地提出可以從互聯網梗圖學習 ML 概念。伴隨的發光大腦影像暗示了一種「開悟」般的理解。
這個梗圖以諷刺手法指出,人們竟可以從幽默、非教育性質的源頭如梗圖中系統化地獲取 ML 知識。它輕松地調侃了這樣一個觀點:即使是透過梗圖接觸某個主題,也可能帶來某種程度的理解,盡管明顯地,梗圖並非嚴肅或全面掌握機器學習的有效途徑。
你覺得哪個 AI 解釋的最好?還有更多演示,請感興趣的讀者點選連結觀看。
官方演示連結: https://showcase.reka.ai/
殺出重圍的「第四 巨頭 」
解析 Reka 的成員結構,他們規模雖小卻實力雄厚,核心成員皆來自 DeepMind、谷歌大腦(Google Brain)和 FAIR(Meta AI)。由於 Reka Core 技術報告的作者部份按照字母大小進行排序,我們尚未得知該模型的核心功臣是誰(並且 Core 的參數目前也尚未公布,但肯定不會低於上一代 Flash 模型的 21B)。

在 Reka 的天團中,最為矚目的便是 Yi Tay 。他在谷歌大腦工作了 3.3 年,期間為諸多行業標桿級大語言模型(如 PaLM、UL2、Flan-2 和 Bard)及多模態模型(如 PaLI-X 和 ViT-22B)做出了貢獻,總共參與撰寫了近 45 篇論文,還是 PaLM-2 和 PaLM-2 API 兩大計畫的共同負責人 。
和出走 OpenAI、在安全問題上與 GPT 針鋒相對的「復仇者聯盟」 Anthropic 不太一樣,Yi Ta y 在出走谷歌時是心懷感激的,當時還寫了一篇深情的告別信總結這 3.3 年的歷程,在 Google 的經歷被他視為學術生涯的「畢業」,因為這段時期與完成博士學位的時間巧合。 期間 Quoc Le 對他的職業生涯產生了重大影響,令他 學會了做有影響力的研究並關註其實際套用, 而他與思維鏈的作者 Jason Wei 也交情頗深。
Google Brain 的故事漫長且極具傳奇色彩,在我們先前釋出的【AI 技術 50 人】欄目中,也記載了 對這個「深度學習黃埔軍校」的回憶。

盡管 Reka 仍處於起步階段,但他們全力以赴挑戰 OpenAI、Anthropic 和 Google 在 AI 領域的主導地位。目前,Reka 已與多家行業合作夥伴和組織展開合作,擴大其模型的套用範圍。例如, Snowflake 最近宣布在其用於 LLM 套用開發的 Cortex 服務中整合 Reka Core 和 Flash。此外,匯聚新加坡所有研究機構及 AI 初創企業和公司的 Oracle 和 AI Singapore 也在使用 Reka 的模型。
然而,在積極投入工作的過程中, 官方卻表示公司並無開源的計劃 。Reka CEO Dani Yogatama 強調自己一直是開源的堅定支持者,但關鍵是找到「分享與保留之間的恰當平衡」,以確保公司持續成長。
4 月 25 ~ 26 日,由 CSDN 和高端 IT 咨詢和教育平台 Boolan 聯合主辦的「 全球機器學習技術大會 」將在上海環球港凱悅酒店舉行,特邀近 50 位技術領袖和行業套用專家,與 1000+ 來自電商、金融、汽車、智慧制造、通訊、工業互聯網、醫療、教育等眾多行業的精英參會聽眾,共同探討人工智慧領域的前沿發展和行業最佳實踐。 歡迎所有開發者朋友存取官網 http://ml-summit.org、點選「閱讀原文」預約領取大會 PPT 。












