作者 | 周周
責編 | 唐小引
出品丨AI 科技大本營(ID:rgznai100)
4 月 27 日上午,國產 AI 視訊大模型 Vidu 在中關村論壇未來人工智慧先鋒論壇上釋出。
「中國第一個長時 長、高一致性、高動態性視訊」是 Vidu 的代名詞,Vidu 模型由清華大學和生數科技聯合開發,具有以下 6 大特征: 模擬真實物理世界、富有想象力、具有多鏡頭語言、出色的視訊時長、時空一致性高、理解中國元素。

模擬真實物理世界:展現復雜、細節豐富的場景,模擬真實世界的物理特性,符合物理規律,例如具有光影效果和人物表情等。
富有想象力:具備虛構場景能力,創造超現實主義畫面
具有多鏡頭語言:支持實作復雜動態鏡頭,體現遠、近、中景、特寫,長鏡頭、追焦等效果
出色視訊時長:一鏡到底 16s 視訊生成,單一大模型,端到端生成
時空一致性高:不同鏡頭之間的視訊連貫,人物和場景在時空中保持一致
理解中國元素:可以理解、生成熊貓、龍等中國元素。

Vidu 背後依托的是一家名為生數科技的創業公司,北京生數科技有限公司成立於 2023年 3 月,核心團隊成員來自清華大學人工智慧研究院,生數科技的 CEO 唐家渝、首席科學家朱軍以及 CTO 鮑凡,皆在人工智慧和擴散模型領域有深厚研究。

該公司致力打造世界領先的多模態大模型,融合文本、影像、視訊、3D 等多模態資訊,探索生成式 AI 在藝術設計、遊戲制作、影視後期、內容社交等場景的商業賦能,透過 AI 提升人類的創造力和生產力。
自 2023 年成立以來,生數科技已完成數億元融資。據了解,生數科技是目前國內在多模態大模型賽道估值最高的創業團隊。
與 SORA 不同的是,Vidu 已經開放了合作夥伴計劃申請表,都可以填寫申請表申請使用,連結如下:
https://shengshu.feishu.cn/share/base/form/shrcnybSDE4Id1JnA5EQ0scv1Ph

U-ViT 架構
U-ViT 是 Vidu 架構的核心技術,於 2022 年提出,全球第一個 Diffusion 與 Transformer 融合的架構,被 CVPR2023 所收錄。2023 年 3 月,團隊開源全球第一個基於 U-ViT 架構的多模態擴散大模型 UniDiffuser,被 ICML2023 所收錄。
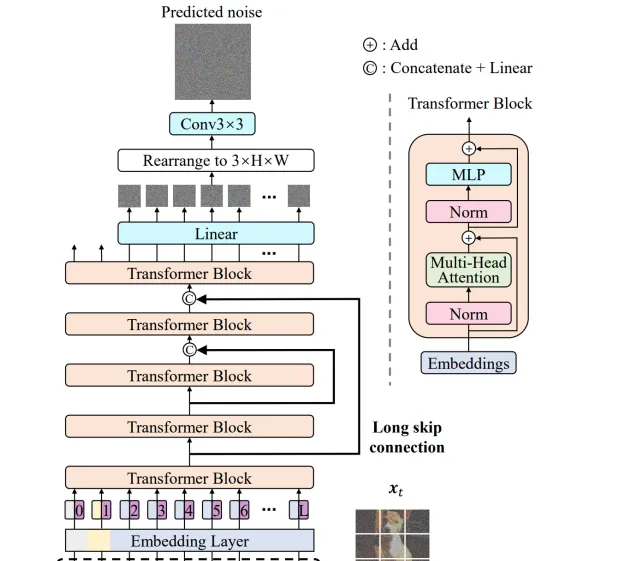
U-ViT 網路是將在影像領域熱門的 Vision Transformer 結合 U-Net,套用在了 DiffisionModel 中。基於 ViT 將時間,條件,和影像塊視作 token 輸入到 Transformer block,受到基於 CNN 的 U-Net 在擴散模型中成功套用的啟發,U-ViT 在網路淺層和深層之間引入長跳躍連線。同時,該架構選擇性地在輸出前添加一個 3×3 的摺積塊以提高視覺品質。網路相關細節如下:
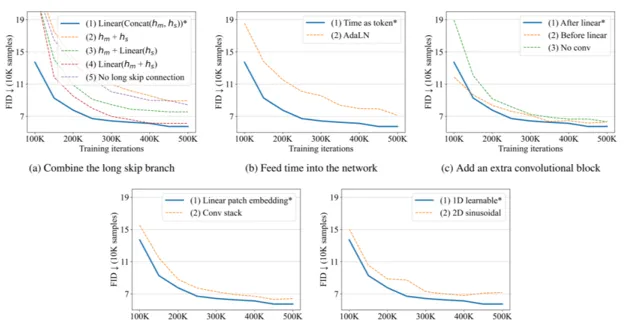
長跳躍連線組合方式: 長跳躍連線是融合特征的有效方式,U-ViT 對網路特征ℎ𝑚和ℎ𝑠的融合方式進行對比,包括以下幾種:𝐿𝑖𝑛𝑒𝑎𝑟(𝐶𝑜𝑛𝑐𝑎𝑡(ℎ𝑚, ℎ𝑠)),ℎ𝑚 + ℎ𝑠,ℎ𝑚 + 𝐿𝑖𝑛𝑒𝑎𝑟(ℎ𝑠),𝐿𝑖𝑛𝑒𝑎𝑟(ℎ𝑚, ℎ𝑠),𝑁𝑜 𝑙𝑜𝑛𝑔 𝑠𝑘𝑖𝑝 𝑐𝑜𝑛𝑛𝑒𝑐𝑡𝑖𝑜𝑛。其中,𝐿𝑖𝑛𝑒𝑎𝑟(𝐶𝑜𝑛𝑐𝑎𝑡(ℎ𝑚, ℎ𝑠))融合形式的效能最佳。
將時間嵌入網路的方式: 1.將時間視為 token;2.在 transformer 中加入層歸一化的時間𝐴𝑑𝑎𝐿𝑁(ℎ, 𝑦) = 𝑦𝑠𝐿𝑎𝑦𝑒𝑟𝑁𝑜𝑟𝑚(ℎ) + 𝑦𝑏。實驗結果表明第一種方法效能更佳。
在 transformer 後添加額外摺積塊的方法: 1.在將 token 嵌入對映到影像塊的線性投影後,添加 3*3 的摺積塊;2.線上性投影前添加 3*3 的摺積塊;3.不添加任何的摺積塊。實驗結果表明第一種方法優於其他兩種方法。
修補程式嵌入的變體: 1.對其采用線性投影,對映至 token 嵌入;2.使用 3*3 摺積塊堆和 1*1 摺積塊,將影像對映至 token 嵌入。實驗結果表明線性投影效果更佳。
位置嵌入的變體: 1.采用一維可學習的位置嵌入;2.采用二維正弦位置嵌入。實驗結果表明一維可學習的位置嵌入效果更佳。
U-ViT 為擴散模型提供了一個簡單通用的基於 ViT 的主幹網路。
UniDiffuser 擴散模型框架

UniDiffuser 擴散模型框架,透過一個統一的模型來建模多模態數據相關的所有分布,包括邊緣、條件和聯合分布,具備影像生成、文本生成、文本到影像生成、影像到文本生成以及影像-文本對生成等任務的能力。
模型統一預測所有分布
學習多模態數據集相關的所有分布,可以透過統一預測擾動數據中的對應的雜訊期望來實作:UniDiffuser 模型同時對所有模態的數據進行擾動,給不同模態的數據設定各自時間步,並預測所有模態的雜訊。不同的時間步長對應不同的擾動級別,零級表示給定相應模態的條件生成,最大級別表示透過忽略相應模態來進行無條件生成,繫結同樣的時間步長意味著對兩種模態進行聯合生成。
對 UniDiffuser 套用 classifier-Free Guidance
classifier-Free Guidance 常用來提高條件擴散模型的生成樣本品質,透過線性組合條件模型和無條件模型來采樣
UniDiffuser 在影像和文本多模態的套用
首先,透過影像和文本編碼器將分別影像和文本轉換為連續的潛在嵌入,並引入兩個解碼器用於重建;然後,在嵌入上訓練 UniDiffuser。其中,影像編碼器包括兩部份,第一部份是 Stable Diffusion 的 VAE,第二部份是 CLIP Image Encoder。文本編碼器采用 Stable Diffusion的 CLIP text Encoder。UniDiffuser 根據上一節獲取的嵌入訓練聯合雜訊預測網路,該網路采用 U-ViT 作為主幹來處理不同的模態。原始 U-ViT 將所有輸入(包括數據、條件和時間步)視為標記,並在淺層和深層之間采用長跳躍連線,UniDiffuser 則將兩種數據模態及其相應的時間步視為標記。
基於對 U-ViT 架構的深入理解以及長期積累的工程與數據經驗,團隊在短短兩個月裏進一步突破了長視訊表示與處理的多項關鍵技術,研發了 Vidu 視訊大模型,顯著提升視訊的連貫性和動態性。












