整理 | 王啟隆
出品丨AI 科技大本營(ID:rgznai100)
WWDC 首日已經結束,今天淩晨蘋果釋出的「Apple Intelligence」引起的反響相當激烈:有人質疑跨 App 互動導致的私密數據問題,還有人覺得這次會的「料」不算很多,而馬斯克看到 OpenAI 和蘋果官宣合作之後,更是恨不得直接開著星艦撞向舊金山。
「我要把用蘋果裝置的員工逐出家門!」
目前,iOS 18 Beta 已經更新完畢,身處蘋果第一線的使用者可以開始體驗蘋果在「端側 AI」上交出的答卷。

然而,許多人的目光放在了 GPT-4o 加持的 Siri 以及其他爭議拉滿的更新上面,對蘋果自研的端側大模型尚不了解;而蘋果也是在下午默默地放出了一篇文章介 紹自己推出的一系列人工智慧基礎模型策略,其中既有參數為 3B 的 On-Device Models (端側模型),也有 Server Foundation Models (伺服器端模型), 引起了開發者社群大量圍觀:
但這不看不知道,一看嚇一跳:在總結和寫作方面,蘋果的端側模型可以打贏 Mistral-7B ,伺服器模型可以打贏 GPT-4-Turbo ?下面放出全文,探探這個 Apple Intelligence 的深淺究竟如何。
經典環節:承諾「負責任的 AI」
蘋果於 2024 年全球開發者大會(WWDC)上推出了 Apple Intelligence,這是一個深度融合至 iOS 18、iPadOS 18 與 macOS Sequoia 的個人智慧系統。
Apple Intelligence 集結了一系列專為使用者日常需求客製、並能即刻適應當前活動的高效能生成式模型。這些構成 Apple Intelligence 的基礎模型,針對文本編輯與完善、通知管理與摘要、與親友聊天時 生成 趣味圖片,以及跨應用程式互動簡化的操作體驗進行了細致調優。
接下來的概覽將詳述這兩款模型 —— 一款約含 30 億參數、 直接部署在裝置上的語言模型 ,以及一款與 Private Cloud Compute 整合、執行於 Apple 自研芯片伺服器的 大型伺服器端語言模型 —— 是如何被構建並適應高效、精確且負責任地執行特定任務的。
這兩大基礎模型隸屬於 Apple 打造的、旨在賦能使用者與開發者的生成式模型全家桶,其中還涵蓋了助力 Xcode 實作智慧化的 編程模型 ,以及在資訊套用等場景中輔助使用者視覺表達的 擴散模型 。期盼未來能分享更多有關這一廣泛模型體系的詳情。
總結:蘋果的自研模型全家桶目前確認會有四款模型。
Apple Intelligence 在設計之初便融入了蘋果的核心價值觀,並建立在創新私密保護技術的基礎上。
此外,蘋果制定了一套負責任 AI 準則,指導內部如何開發 AI 工具及其支撐模型:
賦予使用者智慧工具 :在確保負責任的前提下,辨識能夠透過 AI 解決特定使用者需求的領域。蘋果尊重使用者選擇這些工具實作目標的方式。
代表使用者群體 :蘋果 致力於打造深入個人的產品,真實反映全球使用者的多樣性;他們將 持續努力,避免在 AI 工具和模型中延續刻板印象及系統性偏見。
謹慎設計 : 從設計、模型訓練、功能開發到品質評估,每一步都采取預防措施,辨識 AI 工具可能被誤用或導致潛在傷害的方式。 蘋果將借助使用者反饋,不斷主動改進 AI 工具。
守護私密 : 利用強大的裝置端處理能力與 Private Cloud Compute 等開創性基礎設施,保護使用者私密。 在訓練基礎模型時,蘋果承諾不使用使用者的私人數據或互動資訊。
這些原則貫穿於 Apple Intelligence 的架構之中,連線特色功能與專門模型,監控輸入與輸出,確保每一項功能都能負責任地運作。
下文其余部份將闡述諸如:如何開發高效、快速且節能的模型;蘋果的訓練方法;介面卡如何針對具體使用者需求進行微調;以及蘋果如何評估模型效能,確保其既有助益又避免非預期危害。
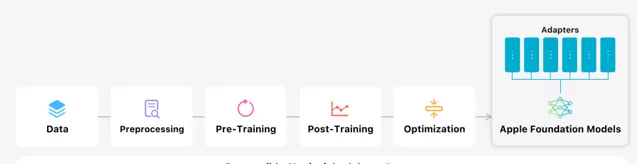
六步打造蘋果基礎模型
揭秘蘋果訓練模型全過程!
預訓練階段(Pre-Training)
蘋果基礎模型依托於 Apple 的開源計畫 AXLearn ,這是 2023 年面世的先進訓練框架,建立在 JAX 與 XLA 基礎上,它提供了跨 TPUs 及各類雲端、本地 GPU 的高效、可延伸模型訓練能力。蘋果綜合運用數據並列、張量並列、序列並列及全分片數據並列(FSDP)技術,從數據規模、模型復雜度到序列長度等多角度擴大訓練規模。
訓練數據選取方面,蘋果既有針對性地引入提升特性的授權資料,也整合由網頁爬蟲 AppleBot 搜集的公共資訊,同時, 網站主有權選擇不參與 Apple Intelligence 訓練計劃 。保護私密方面,蘋果嚴格避免使用使用者個人數據及互動記錄,實施過濾機制排除互聯網上的社保號、信用卡號等敏感資訊,並剔除粗俗內容及低質材料,以保障訓練集的品質。此外,蘋果還執行數據精煉、去重及基於 模型的優質文件甄別工作。
後訓練階段(Post-Training)
數據品質被視為模型效能的關鍵,因此蘋果的訓練流程融合了人工標註數據與合成數據,輔以嚴格的資料治理與篩選過程。在後訓練環節,蘋果創新性地提出了兩項演算法:一是教師團隊輔助的拒絕采樣微調法;二是結合映像下降策略最佳化與單例優勢評估的基於人類反饋的強化學習(RLHF)。這兩項演算法極大提升了模型遵循指令的能力。
最佳化措施
確保生成模型高效能的同時,蘋果透過一系列革新策略,最佳化了其在終端與私有雲環境下的執行速度與效率。這些最佳化涵蓋了首 token 推理及連續 token 推理的各個方面。
不論是裝置端還是伺服器端模型,蘋果都采用了分組查詢註意力機制,並透過共享輸入輸出詞嵌入表減小記憶體占用和推理開銷,這些表在對映時不產生冗余。裝置端模型 配置了 49K 詞匯量,而伺服器端則使用了包含更多語言與技術詞匯的 100K 詞匯量。
裝置端推理上,蘋果運用了低位元量化技術,既滿足了記憶體、能耗和效能需求,又透過 引入 LoRA 介面卡框架 ,采用 2 位元與 4 位元混合 配置方案(平均每位權值 3.5 位元),保持了模型精度不變。
蘋果還利用互動式模型延遲與功耗分析工具 Talaria ,精確調控各項操作的量化級別。另外,啟用量化與嵌入量化亦被采納,且設計了針對神經引擎的高效 KV 緩存更新方案。
經過上述最佳化,在 iPhone 15 Pro 上,蘋果實作了約 0.6 毫秒 的首次 token 延遲,以及每秒 30 tokens 的生成速度。這還是在未采用 token 預測技術之前,後者將進一步加速 token 生成。
模型適應力調整
基礎模型透過微調融入使用者日常套用場景,具備了按需即時自我客製的能力。蘋果借助介面卡——即可插拔於預訓練模型各層級的小型神經網路元件——對特定任務進行微調,調整範圍覆蓋了 Transformer 架構解碼層的註意力矩陣、註意力投射矩陣及點對點前饋網路的全連線層。
僅對介面卡層進行微調,確保了基礎模型的核心知識結構不變,同時介面卡層靈活適應任務需求。
介面卡參數以 16 位形式儲存,對於約 30 億參數的裝置端模型,一個 rank 16 的介面卡參數集占用幾十 MB 空間。介面卡模型支持動態載入、記憶體緩存及切換,使基礎模型能隨任務需求即時調整自身,高效管理記憶體資源,確保系統響應敏捷。
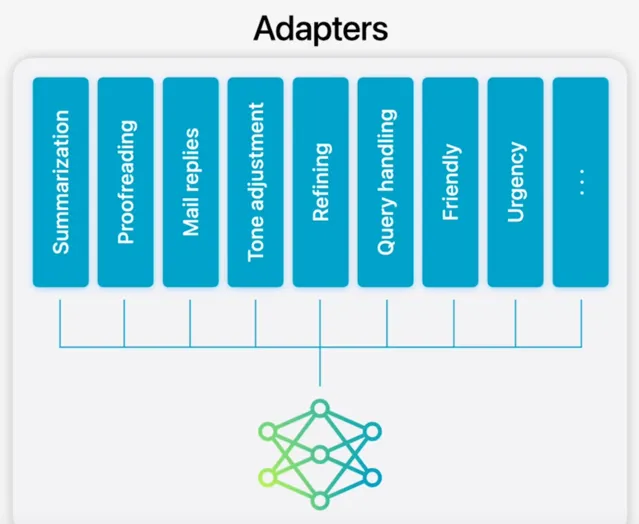
為加速介面卡訓練,蘋果還搭建了高效基礎設施,便於在基礎模型或訓練數據更新時快速叠代、測試及部署介面卡。介面卡參數初值設定基於最佳化章節提及的精度恢復介面卡方案。
效能評估環節:以人為本
蘋果致力於打造能讓使用者跨裝置溝通、工作、自我表達並高效完成任務的生成模型。在衡量模型效能時,測試團隊重 視 人類的反饋 ,下面的所有圖表也都標註著「人類評審員」的字樣 —— 因為這能緊密關聯到實際產品體驗。整套評估工作涵蓋了特有功能介面卡及核心模型的效能。
PK 計畫 1:摘要總結
鑒於信件和通知摘要的需求雖然細微但極其關鍵,蘋果對壓縮後的基礎模型套用了精度恢復 LoRA 介面卡進行微調,以貼合具體需求。訓練素材基於大型伺服器模型產出的合成摘要,並經由嚴格的篩選機制,僅保留最優質的部份。
為了驗證特定場景下的摘要品質,蘋果選取了 750 份精心挑選的樣本,每一種套用場景均包含在內。這組評估資料特意包含了產品特性在實際套用中可能遇到的各種復雜輸入情況,既有單一文件也有復合文件,內容型別和長度各異。確保貼近真實套用場景對評估來說至關重要,結果顯示,采用介面卡的模型生成的摘要優於同類模型。
為了開發「負責任的 AI」,蘋果還辨識並分析了摘要功能內在的風險,比如某些情況下摘要可能會不當簡化資訊。 幸運的是,摘要介面卡在超過 99% 的對抗性範例中未加劇敏感內容的問題,隨後測試團隊 持續進行對抗性測試,以探索未知風險點,並據此指導後續最佳化。
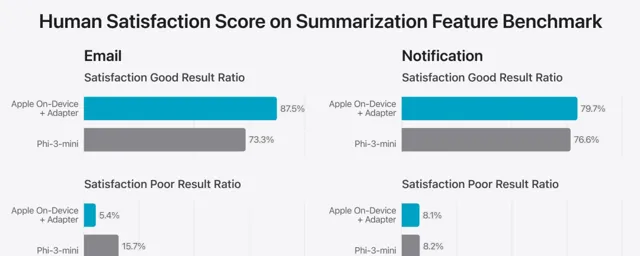
圖為兩種摘要套用場景下「優秀」與「不佳」反饋占比,依據評價者在五個標準上的打分劃分。 只有當所有維度均達到高分標準時才被視為「優秀」,有任何一項指標得分偏低即被標記為「不佳」。 結果表明,蘋果的介面卡增強模型在摘要生成上更勝一籌。
PK 計畫 2:通用能力
除了功能特性的專項測試,蘋果也檢驗了裝置內建模型和雲端模型的通用能力。 采用廣泛的真實世界情境作為測試樣本,這些情境包羅永珍,從簡單的創意思維到復雜的數學問題解答,再到程式碼編寫和文本安全檢測。
蘋果將自家模型與開源界(如Phi-3、Gemma、Mistral、DBRX)及業界同量級的商用模型(GPT-3.5-Turbo、GPT-4-Turbo)進行了對比。 結果顯示,多數情況下,蘋果模型更受人類評審員的青睞。
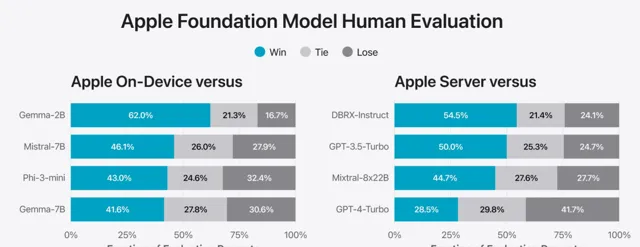
尤為值得一提的是,即使參數量僅為約 30 億的裝置端模型,在多項基準測試中也能超越 Phi-3-mini、Mistral-7B 和 Gemma-7B 等大模型。 而雲端模型的表現更是優於 DBRX-Instruct、Mixtral-8x22B 及 GPT-3.5-Turbo,同時保持著極高的效率。
PK 計畫 3:風險敏感
測試團隊還利用一套多樣化的對抗性提示來檢測模型在處理有害資訊、敏感話題及事實準確度方面的表現。
透過人類評審員的打分,測試團隊量化了模型在這類測試中的違規頻率,數值越低代表表現越佳。 無論是裝置端還是雲端模型,在面臨挑戰性測試時都表現出了強大的穩健性,違規率遠低於開源和商業競品。
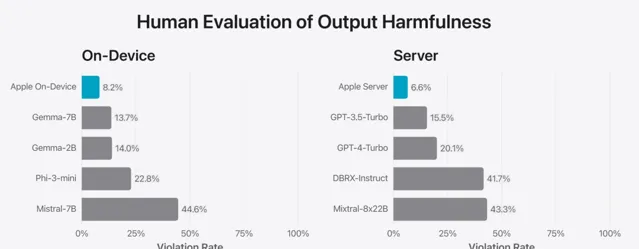
在有害內容、敏感話題及事實準確性方面的違規響應占比,數值越小意味著模型越能妥善應對對抗性挑戰。
蘋果的模型在這方面展現出了顯著的魯棒性。
人類評審員一致認為,相較於競爭對手,蘋果的模型在安全性與實用性上更勝一籌。
盡管如此,鑒於大語言模型的廣泛潛力,研究團隊深知當前安全評估的局限。
因此,
蘋果正與內外部團隊密切合作
,透過手動及自動化手段持續進行安全審計,以期不斷提升模型的安全水平。
PK 計畫 4:模型安全性
相較於競爭者,在特定情境提示下,蘋果的基礎模型被人類評審員一致認為更安全、實用。盡管如此,鑒於大語言模型的多功能性,研究團隊也清楚意識到當前安全評估標準的局限性。因此,蘋果正攜手內外部團隊,積極開展手動與自動化紅藍對抗測試,持續監控模型安全性表現。
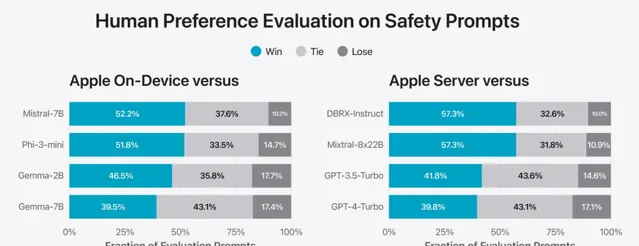
上面這張測評描述了安全導向評估場景下,蘋果基礎模型相對其他可比模型在獲得偏好評價方面的占比。透過人類稽核確認,蘋果模型的回應不僅更安全,且實用性更強。
PK 計畫 5:指令執行能力
為進一步驗證效能,蘋果借助 Instruction-Following Eval(IFEval)標準,與同等級別模型對比指令執行能力。結果顯示,無論是在裝置內建還是雲端版本上,蘋果模型均優於市面上開源及商用競品,展現出對復雜指令的出色遵循力。
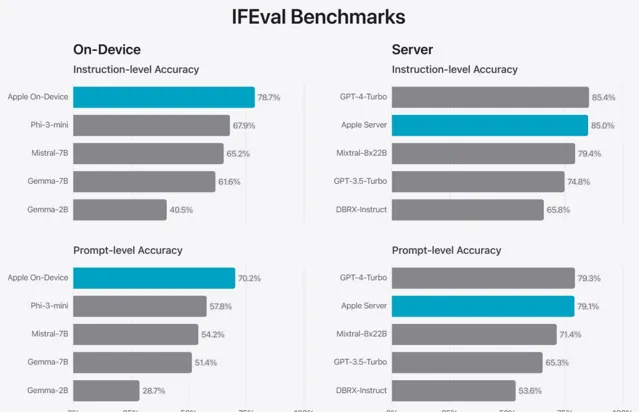
上圖展示了蘋果基礎模型及其同類規模模型的指令遵循能力得分(IFEval 測試,分數越高代表能力越強)。
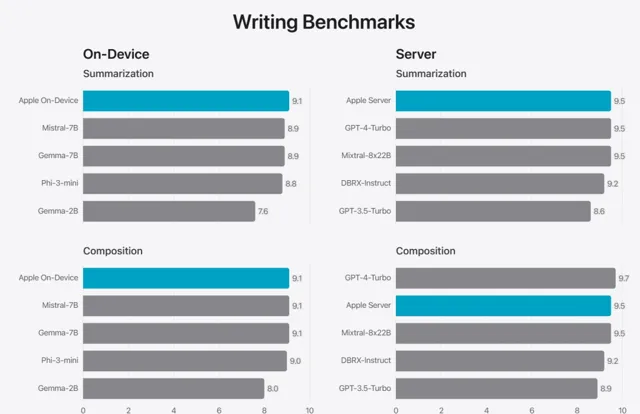
PK 計畫 6:寫作
為了檢驗寫作技能,測試團隊利用包含多樣寫作指令的內部摘要與創作指標進行評估。需註意的是,這部份測試不涉及第一輪 PK 中提及的特定摘要介面卡,也未專門設計用於評估創作能力的介面卡。
下面這張圖反映了在上述內部評估體系下,模型的寫作能力水平(同樣遵循高分優原則)
於 WWDC24 釋出的蘋果基礎模型及其介面卡體系,是 Apple Intelligence 的核心支撐,這一全新個人智慧化系統深度融入了 iPhone、iPad 和 Mac,全方位提升了使用者的語言處理、影像辨識、行動指導及個人化體驗。
蘋果的目標是助力使用者輕松完成跨裝置的日常任務,並確保在每個開發環節都秉持蘋果的核心價值理念,負責任地推進技術進步。 未來,蘋果還會帶來更多關於生成模型系列的最新動態,涵蓋語言、擴散模型及編程模型等前沿領域。
開發者正在迎接新一輪的技術浪潮變革。由 CSDN 和高端 IT 咨詢和教育平台 Boolan 聯合主辦的 2024 年度「全球軟體研發技術大會」秉承幹貨實料(案例)的內容原則,將於 7 月 4 日-5 日在北京正式舉辦。大會共設定了 12 個大會主題:大模型智慧套用開發、軟體開發智慧化、AI 與 ML 智慧運維、雲原生架構……詳情👉: http://sdcon.com.cn/












