大家好,歡迎來到編程教室~
ChatGPT、StableDiffusion的火爆,讓很多同學都想 在自己的電腦上部署本地大模型,進而學習AI、微調模型、二次開發等等。
然而現在 動輒好幾萬的 高算力顯卡讓很多人望而卻步。

但其實 還有一種方案,就是使用雲主機。比如我最近在用的潞晨雲,4090顯卡的機器,現在還不到2塊錢一小時,甚至還能用上現在一卡難求的H800。
使用雲主機也很方便,直接選擇你想要的配置,建立新的雲主機。
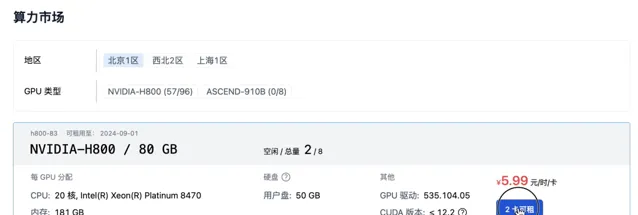
取個名字,選擇顯卡數量。
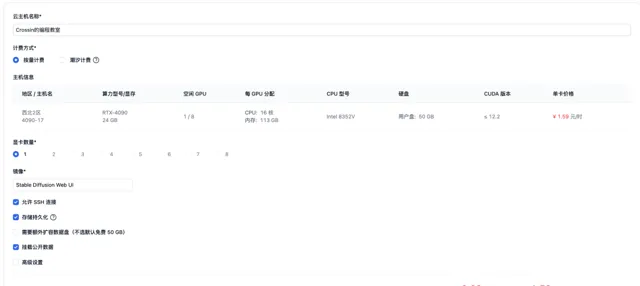
潞晨雲提供了很多預先配置好的公共映像,以滿足一些常用開發場景。省去了配置環境的麻煩,開箱即可用。還提供一些公開的模型數據可掛載使用。
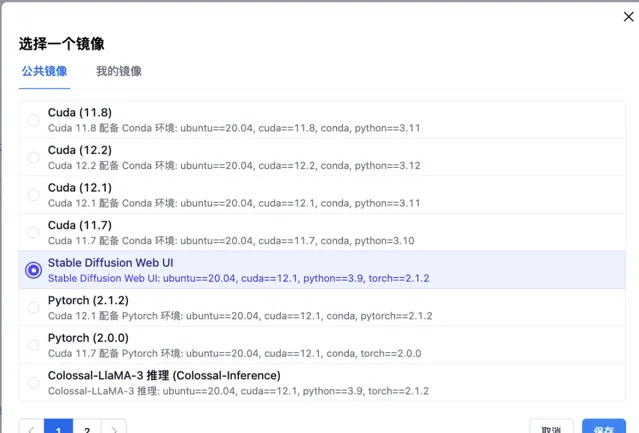
建立主機,等待初始化完成開機後,可以直接透過控制台提供的JupyterLab存取,也可在添加SSH公鑰後,透過本地控制台,或者VSCode遠端連線等方式操作主機和編寫程式碼。
建議先添加SSH公鑰,再建立主機,這樣 SSH 公鑰會自動生效。

最近經常刷到一些AI制作的繪本故事短視訊。下面我就用雲主機上部署的AI工具,來仿制一個這樣的視訊。
我打算做一個簡單的四格漫畫。
1. 指令碼
首先要創作故事指令碼。我的想法是用Meta前陣子剛剛釋出的開源大語言模型Llama 3,讓它來幫我寫。這裏我選擇ollama這個框架,它可以很方便地呼叫llama3模型。
安裝ollama只需要一行命令,然後等待自動下載安裝:
curl -fsSL https://ollama.com/install.sh | sh
安裝完成後啟動服務:
ollama serve
執行 llama3 並與之對話:
ollama run llama3
第一次執行時,程式會去下載模型檔。
如果要使用 llama3-70b,就改一下命令中的模型名:
ollama run llama3:70b
但因為70B的模型有40G,預設地址下的空間不足的話,需要修改環境變量 OLLAMA_MODELS,將模型路徑設到 /root/dataDisk,然後再啟動ollama
export OLLAMA_MODELS=/root/dataDisk/.ollama/models
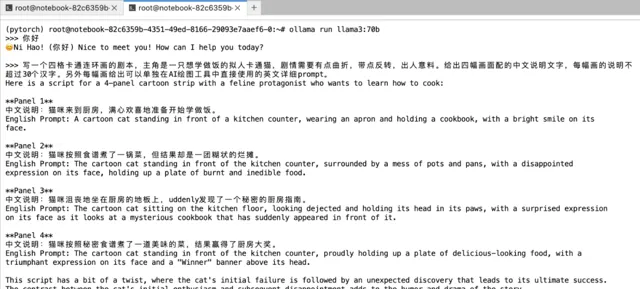
告訴llama3,幫我寫一個四格卡通連環畫的劇本,主角是一只想學做飯的貓,讓它提供配圖的中文說明和英文提示詞。
2. 繪圖
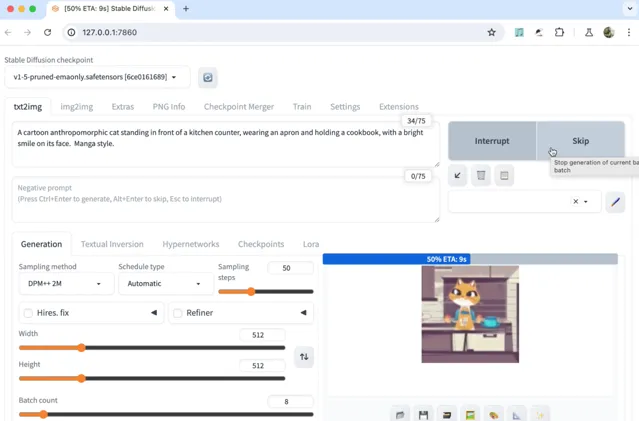
有了劇本和提示詞,接下來就可以繪制插畫了。潞晨雲預設提供了StableDiffusionWebUI的映像,選擇此映像建立主機後( 建議選擇1卡H800機器 ),就可以透過一行命令直接啟動網頁版的StableDiffusion。
cd /root/stable-diffusion-webuibash webui.sh -f
控制台輸出中看到如下地址說明執行成功,記錄下埠號:
因為限制了公網埠存取,我們在本地做一個ssh埠轉發,就能在本地瀏覽器透過 http://127.0.0.1:7860 開啟了。
sh -CNg -L 本地埠:127.0.0.1:7860 root@雲主機地址 -p 埠號
把llama3生成的提示詞貼進去稍作修改,設定下出圖的數量,就能得到與劇情配套的插圖。調節參數多試幾次,從中選擇你滿意的圖。就可以拿來制作視訊了。
3. 視訊
假如你覺得靜態的圖片太過單調。還可以嘗試用AI生成視訊片段。之前OpenAI釋出的文生視訊大模型Sora火爆全網,可惜目前我們還沒法用上它。
而潞晨團隊開源的 Open-Sora 計畫,嘗試對Sora的效果進行了復現,盡管在時長和效果還有差距,但還是很值得期待的。 目前Open Sora在 github 上已有1萬7千多star。
同StableDiffusion一樣,潞晨雲也提供了OpenSora的映像。建立主機 之後 (建議選擇1卡H800機器),配置一下環境路徑,就可以使用了。 註意:一定要選擇「掛載公開數據」。
mkdir -p /root/.cache/huggingface/hubln -s /root/notebook/common_data/OpenSora-1.0/models--stabilityai--sd-vae-ft-ema /root/.cache/huggingface/hub/models--stabilityai--sd-vae-ft-emaln -s /root/notebook/common_data/OpenSora-1.0/models--DeepFloyd--t5-v1_1-xxl /root/.cache/huggingface/hub/models--DeepFloyd--t5-v1_1-xxl
我們把提示詞替換到計畫的配置檔 assets/texts/t2v_samples.txt 中,執行程式:
cd Open-Sora/python -m torch.distributed.run --standalone --nproc_per_node 1 scripts/inference.py configs/opensora/inference/16x512x512.py --ckpt-path /root/notebook/common_data/OpenSora-1.0/OpenSora-v1-HQ-16x512x512.pth --prompt-path ./assets/texts/t2v_samples.txt
稍等片刻,就會在 samples/samples 資料夾中得到生成的視訊。
4. 配音
最後,還需要給故事增加一個朗讀旁白。這個可以透過語音合成技術實作。這裏我用的是Coqui-TTS。
透過pip命令就可以安裝,支持包括中文在內的多種語言:
pip install TTS
用 tts 命令把 llama3 生成的配圖說明轉成語音:
tts --text "需要轉換為語音的文字內容" --model_name "tts_models/zh-CN/baker/tacotron2-DDC-GST" --out_path speech.wav
這裏 tts_models/zh-CN/baker/tacotron2-DDC-GST 為中文語音模型。
再同前面生成的視訊整合到一起。
來看看最終的效果。 (參見文章開頭的視訊)
這個演示中,我用的都是些基礎模型和預設配置,大家還可以在此基礎上進一步微調和最佳化。雖然這幾樣功能,市面上都有現成產品可以實作。但對於學習AI的人來說,是要成為AI的產生者而不是消費者,所以還是得靠自己動手部署和開發。
這種情況下,尤其對學生黨來說,雲服務的價效比就很高了。假設只有3000塊的預算,買台帶4090顯卡的電腦就別想了,但在潞晨雲上,4090的雲主機按2塊錢一小時,平均每天使用4小時來算,就能用上375天了。而且還能根據你的需求快速升級和擴容,這點上比自己的電腦還要方便。
最近
潞晨雲還有活動可以領取代金券:
【百萬補貼】優質線上算力資源百萬補貼等你來薅,隨開隨用。
【企業認證】企業使用者參與潞晨雲企業認證可得500元代金券。
【分享有禮】:使用者在社交媒體和專業論壇(如知乎、小紅書、微博、CSDN等)上分享使用體驗並帶上「 #潞晨雲 」,有效分享一次可得100元代金券。
了解詳情可關註潞晨雲官方公眾號: 潞晨科技
最後提醒一下,用完記得及時關機,節省點費用哦。
參考網址:
潞晨雲:
https://
cloud.luchentech.com
ollama:https://ollama.com/download/linux
coqui-tts:https://github.com/coqui-ai/TTS
添加微信
crossin123
,加入編程教室共同學習
~
感謝 轉發 和 點贊 的各位~











