DeepMind再放大招!!
新方法拯救大模型算力問題!省時省力!!🥳
新方法
JEST
將模型訓練時間
縮短13倍
!!
節省90%的算力
!!
許多算力不足的問題在此刻迎來了曙光!!🤩

掃碼加入AI交流群
獲得更多技術支持和交流

技術簡介
對模型進行大規模的預訓練時,訓練數據的品質對模型的效能起到十分重要的作用。
無論在語言、視覺,還是多模態模型中,優質高品質的數據集的使用能夠顯著減少所需的數據量,大幅提高模型的效能表現。
但對訓練數據管道傳統上都是進行手動篩選,這是十分昂貴且不靈活的。
聯合範例選擇技術——JEST 透過聯合選擇批次訓練數據,比單獨選擇數據更能夠加速學習過程,優先數據點大大加快訓練速度。
技術原理
為了確定哪些數據最容易學習,JEST使用兩個模型:當前正在訓練的模型和已經訓練的參考模型。
對於那些正在訓練的模型來說很難,但對於參考模型來說很容易的數據被認為是高品質的。
並采用對批次數據進行評分的策略,根據這些評分來采樣。主要使用三種評分準則:困難學習器、簡單參考和可學習性。
最終可學習性評分結合了前兩種評分準則,透過優先選擇那些未被學習但易於學習的數據加速大規模學習過程。
技術效果
為了減少評估「超級批次」時增加的計算工作量,團隊還引入了一個名為 Flexi-JEST 的變體。
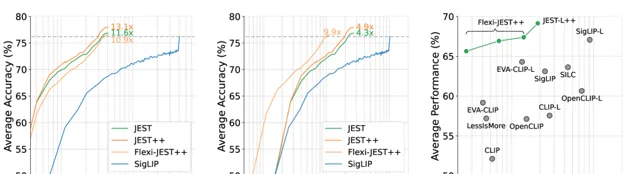
在達到相同的訓練後模型效能的情況下,
JEST
比當前最好的方法
SigLIP
最高縮短13倍的叠代次數。
同時第二張圖能看出 Flexi-JEST 僅用10% 的訓練數據就取得 SigLIP 用100%取得的分數。
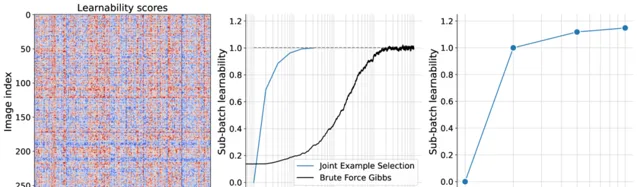
並且JEST能夠產生更多可學習的批次,第一張圖達到批次的可學習性高度結構化且非對角化。
從二圖我們能看出JEST更少的叠代發現與吉布士抽樣相當的具有高可學習性的子批次。
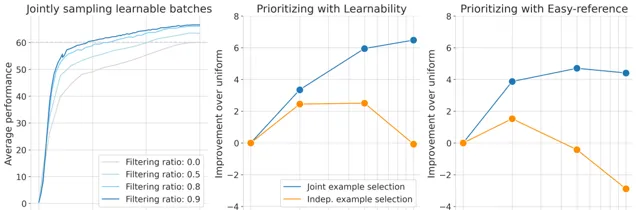
采樣批次的可學習性隨著過濾率的提高而提高,能夠從更大的超批次中進行選擇。
JEST從超批次中選擇出的最具學習能力的子批次上進行訓練顯著加速多模態學習。
同時下面清楚地表現出聯合優先排序可學習批次比簡單地優先排序單個樣本能產生更好的結果。
多分辨率訓練對於提升JEST的效能十分重要且顯著,同時在數據集中緩存固定的參考模型分數,可以將JEST 在大型超批次進行評分時每次叠代產生的大量的計算成本減少一半。
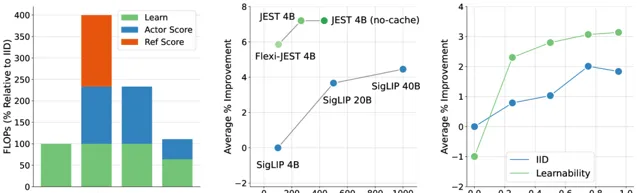
基於現有的技術相比較,JEST能夠讓模型達到用最少的訓練量達到超越其他技術的效能,並在T2I以及I2T的套用上達到最好的效果。
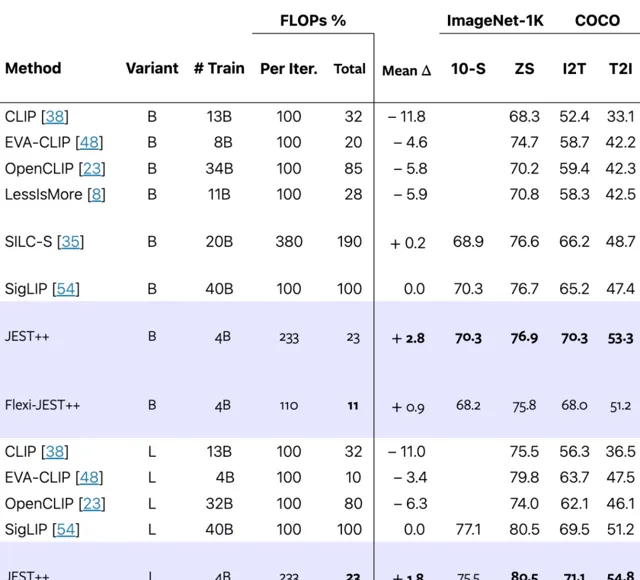
COCO 效能表示影像到文本和文本到影像檢索的平均值,JEST ++ 大大超越了現有技術,同時需要的訓練叠代次數明顯減少。
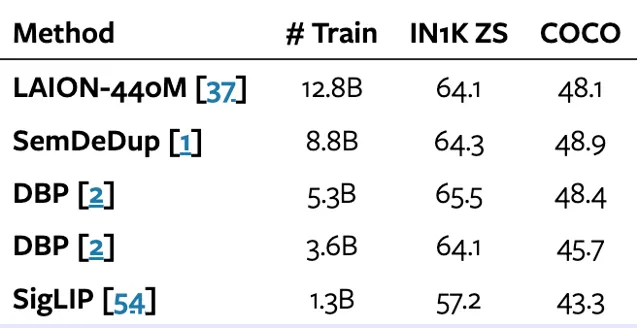
總的來說,JEST 方法在實驗中展示了顯著的優勢。相比於傳統的獨立樣本選擇方法,JEST 不僅提升了訓練效率,還顯著減少了所需的計算量。
JEST 為多模態學習中的數據篩選提供了一種新的高效方法,小編覺得在未來的各種新技術裏會看到它的身影!
🔗 計畫連結 :
https://arxiv.org/abs/2406.17711
關註「 向量光年 」公眾號
加速全行業向AI的改變
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點
關註「 AGI光年 」公眾號
獲取每日最新咨詢











