點選「 IT碼徒 」, 關註,置頂 公眾號
每日技術幹貨,第一時間送達!
1. 並列處理
簡要說明
舉個例子:在價格查詢鏈路中,我們需要獲取多種獨立的價格配置項資訊,如基礎價、折扣價、商戶活動價、平台活動價等等。為了加快處理速度,可以使用多執行緒並列處理的方式,利用並行計算的優勢。而
CompletableFuture
是一種流行的實作多執行緒的方式,它可以輕松地管理執行緒的建立、執行和回呼,提高程式的可延伸性和並行性。
然而,多執行緒的使用也存在一些弊端,例如硬體資源的限制和執行緒間的通訊開銷等。因此,我們需要在使用多執行緒的同時,考慮到 I/O 密集型和 CPU 密集型的差異,以避免過度開啟執行緒導致效能下降。同時,對於執行緒池的執行情況,我們也需要有一定的了解和控制,以確保程式的高效穩定執行。
CompletableFuture 是銀彈嗎?
我們常說「手拿錘子看什麽都像釘子」,使用
CompletableFuture
的確能夠幫助我們解決許多獨立處理邏輯的問題,但是如果使用過多的執行緒,反而會導致執行緒排程時間不能得到保障,執行緒會被浪費在等待 CPU 時間片上,特別是對於那些本來執行速度就很快的任務,使用 CompletableFuture 之後反而會拖慢整體執行時長。
因此,在使用
CompletableFuture
時,我們需要根據具體的場景和任務,仔細考慮是否需要並列處理。如果需要並列處理,我們需要根據任務的性質和執行速度,選擇合適的執行緒池大小和並列執行緒數量,以避免執行緒排程時間的浪費和執行效率的下降。
測試案例
執行 a,b,c,d4 個方法,比較同步執行與異步執行的耗時情況。
全同步執行
privatevoidtest(){
longs=System.currentTimeMillis();
a(10);
b(10);
c(10);
d(10);
longe=System.currentTimeMillis();
System.out.println(e - s);
}
publicvoida(int time){
try{
Thread.sleep(time);
}catch(InterruptedException e){
e.printStackTrace();
}
}
publicvoidb(int time){
try{
Thread.sleep(time);
}catch(InterruptedException e){
e.printStackTrace();
}
}
publicvoidc(int time){
try{
Thread.sleep(time);
}catch(InterruptedException e){
e.printStackTrace();
}
}
publicvoidd(int time){
try{
Thread.sleep(time);
}catch(InterruptedException e){
e.printStackTrace();
}
}
全異步執行
privatevoidtest2(){
longs=System.currentTimeMillis();
List<CompletableFuture<?>> completableFutureList =newArrayList<>();
CompletableFuture<Void> future1 =CompletableFuture.runAsync(()->{
a(10);
});
completableFutureList.add(future1);
CompletableFuture<Void> future2 =CompletableFuture.runAsync(()->{
b(10);
});
completableFutureList.add(future2);
CompletableFuture<Void> future3 =CompletableFuture.runAsync(()->{
c(10);
});
completableFutureList.add(future3);
CompletableFuture<Void> future4 =CompletableFuture.runAsync(()->{
d(10);
});
completableFutureList.add(future4);
CompletableFuture<?>[] futures = completableFutureList.toArray(newCompletableFuture[0]);
CompletableFuture<Void> futureAll =CompletableFuture.allOf(futures);
futureAll.join();
longe=System.currentTimeMillis();
System.out.println(e - s);
}
結果統計
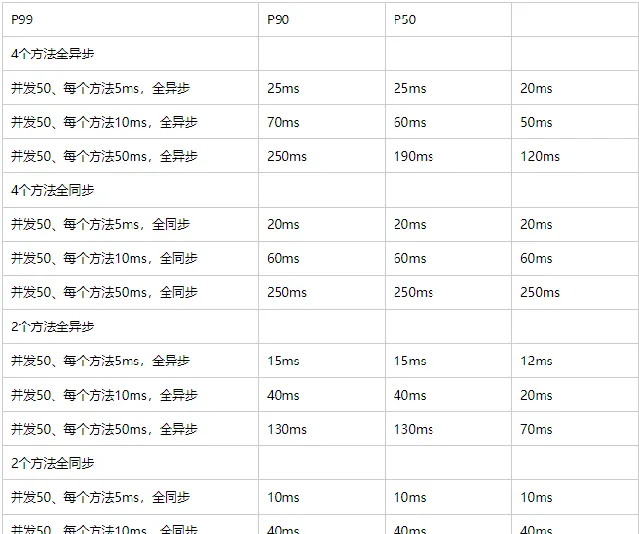
測試結論
在分配了相對合理的執行緒池的情況下,透過以上分析,可以得出下列兩個結論:
• 方法耗時越少,同步比異步越好。
• 方法數量越少,同步比異步越好。
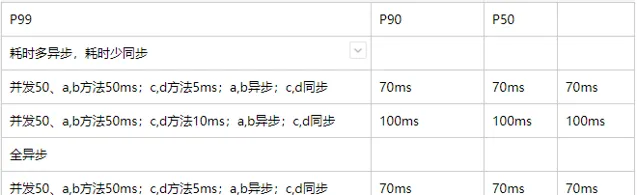
半異步,半同步
有時候,如果方法較多,為了減少高並行時 P99 較高,我們可以讓耗時多的方法異步執行,耗時少的方法同步執行。
透過以下數據可以看出,耗時是差不多的,但可以節省不少執行緒資源。
總結
CompletableFuture
提供了一種優雅而強大的方式來處理並行請求和任務。然而,正如在處理高並行時使用過多的執行緒會導致資源浪費和效率下降一樣,使用過多的
CompletableFuture
也會導致同樣的問題。這種現象被稱為 "執行緒排程問題",它會導致效能下降和吞吐量下降(P99 值較高)。
因此,我們需要在使用
CompletableFuture
時考慮實際場景和負載情況,並根據需要使用恰當的技術來最佳化效能。
2. 最小化事務範圍
簡要說明
首先,我們需要明確的是,事務的存在勢必會對效能產生影響,特別是在高並行的情況下,因為鎖的競爭,會帶來極大的效能損耗。因此,在處理數據互動的過程中,我們始終堅持盡可能地減少事務的範圍,從而提升介面的響應速度。
一般來說,我們可以利用
@Transactional
註解輕松實作事務的控制。但是,由於
@Transactional
註解的最小粒度僅限於方法級別,因此,為了更好地控制事務的範圍,我們需要透過編程式事務來實作。
在編程式事務中,我們可以更靈活地控制事務的開啟和結束,以及對資料庫操作的處理。透過適當的設定事務參數和操作規則,我們可以實作事務的最小化,從而提升系統的效能和可靠性。
編程式事務樣版
publicinterfaceTransactionControlService{
/**
* 事務處理
*
* @param objectLogicFunction 業務邏輯
* @param <T> result type
* @return 處理結果
* @throws Exception 業務異常資訊
*/
<T> T execute(ObjectLogicFunction<T> objectLogicFunction)throwsException;
/**
* 事務處理
*
* @param voidLogicFunction 業務邏輯
* @throws Exception 業務異常資訊
*/
voidexecute(VoidLogicFunction voidLogicFunction)throwsException;
}
@Service
public classTransactionControlServiceImplimplementsTransactionControlService{
@Autowired
privatePlatformTransactionManager platformTransactionManager;
@Autowired
privateTransactionDefinition transactionDefinition;
/**
* 事務處理
*
* @param businessLogic 業務邏輯
* @param <T> result type
* @return 處理結果
* @throws Exception 業務異常資訊
*/
@Override
public<T> T execute(ObjectLogicFunction<T> businessLogic)throwsException{
TransactionStatustransactionStatus= platformTransactionManager.getTransaction(transactionDefinition);
try{
Tresp= businessLogic.logic();
platformTransactionManager.commit(transactionStatus);
return resp;
}catch(Exception e){
platformTransactionManager.rollback(transactionStatus);
thrownewException(e);
}
}
/**
* 事務處理
*
* @param businessLogic 業務邏輯
*/
@Override
publicvoidexecute(VoidLogicFunction businessLogic)throwsException{
TransactionStatustransactionStatus= platformTransactionManager.getTransaction(transactionDefinition);
try{
businessLogic.logic();
platformTransactionManager.commit(transactionStatus);
}catch(Exception e){
platformTransactionManager.rollback(transactionStatus);
thrownewException(e);
}
}
}
@FunctionalInterface
publicinterfaceObjectLogicFunction<T> {
/**
* 業務邏輯處理
*
* @return 業務處理結果
* @throws BusinessException e
*/
T logic() throws BusinessException;
}
@FunctionalInterface
publicinterfaceVoidLogicFunction {
/**
* 業務邏輯處理
*
* @throws Exception e
*/
voidlogic() throws Exception;
}
transactionControlService.execute(() -> {
// 把需要事務控制的業務邏輯寫在這裏即可
});
3. 緩存
簡要說明
緩存,這一在效能提升方面堪稱萬金油的技術手段,它的重要性在各種電腦套用領域中無可比擬。
緩存作為一種高效的數據讀取和寫入的最佳化方式,被廣泛套用於各種領域,包括電商、金融、遊戲、直播等。
雖然在網路上關於緩存的文章不勝列舉,但要想充分發揮緩存的作用,需要針對具體的業務場景進行深入分析和探討。因此,在本節中,我們將不過多贅述緩存的具體使用方法,而是重點列舉一些使用緩存時的註意事項.
使用緩存時的註意事項
• 緩存過期時間: 設定合適的過期時間可以保證緩存的有效性,但過期時間過長可能會浪費記憶體空間,過期時間過短可能會導致頻繁清除快取,影響效能。
• 緩存一致性: 如果緩存的數據與資料庫中的數據不一致,可能會導致業務邏輯出現問題。因此,在使用緩存時需要考慮緩存一致性的問題。
• 緩存容量限制: 緩存容量有限,如果緩存的數據量過大,可能會導致記憶體溢位或者緩存頻繁清理。因此,在使用緩存時需要註意緩存容量的限制。
• 緩存需要考慮負載均衡: 在高並行場景下,需要考慮緩存的負載均衡問題,避免某些緩存伺服器因為熱點數據等問題負載過重導致系統崩潰或者響應變慢。
• 緩存需要考慮並行讀寫: 當多個使用者同時存取緩存時,需要考慮並行讀寫的問題,避免緩存沖突和數據一致性問題。
• 緩存穿透問題: 當大量的查詢請求都無法命中緩存時,導致每次查詢都會落到資料庫上,從而造成資料庫壓力過大。
• 緩存擊穿問題: 當緩存數據失效後,導致大量的請求直接打到資料庫中,從而造成資料庫壓力過大。
• 查詢時間復雜度: 需額外註意緩存查詢的時間復雜度問題,如果是 O(n),甚至更差的時間復雜度,則會因為緩存的數據量增加而跟著增加。
考慮到這些問題通常最佳化的手段
•
資料壓縮:
選擇合理的數據型別,舉個例子:如果用
Integer[]
和
int[]
來比較,Integer 占用的空間大約是 int 的 4 倍。其他情況下,使用一些常見數據編碼壓縮技術也是常見的節省記憶體的方式,比如:BitMap、字典編碼等。
• 預載入: 當行為可預測時,那麽提前載入便可解決構建緩存時的壓力。
• 熱點數據: 熱點數據如果不能打散,那麽通常就會構建多級緩存,比如將套用服務設為一級緩存,Redis 設為二級緩存,一級緩存,緩存全量熱點數據,從而實作壓力分攤。
• 緩存穿透、擊穿: 針對命中不了緩存的查詢也可以緩存一個額外的標識;而針對緩存失效,要麽就在失效前,主動重新整理一次,要麽就分散失效時間,避免大量緩存同時失效。
• 時間復雜度: 在設計緩存時,優先考慮選擇常數級的時間復雜度的方法。
4. 合理使用執行緒池
簡要說明
在本文開始提到的使用
CompletableFuture
並列處理時,實際上就已經使用到執行緒池了,池化技術的好處,我想應該不用再過多闡述了,但關於執行緒池的使用還是有很多註意點的。
使用場景
異步任務
簡單來說就是某些不需要同步返回業務處理結果的場景,比如:簡訊、信件等通知類業務,評論、點贊等互動性業務。
平行計算
就像
MapReduce
一樣,充分利用多執行緒的平行計算能力,將大任務拆分為多個子任務,最後再將所有子任務計算後的結果進行匯總,
ForkJoinPool
就是 JDK 中典型的平行計算框架。
同步任務
前面講到的
CompletableFuture
使用,就是典型的同步改異步的方式,如果任務之間沒有依賴,那麽就可以利用執行緒,同時進行處理,這樣理論上就只需要等待耗時最長的步驟結束即可(實際情況可參考
CompletableFuture
分析)。
執行緒池的建立
不要直接使用
Executors
建立執行緒池,應透過
ThreadPoolExecutor
的方式,主動明確執行緒池的參數,避免產生意外。
每個參數都要顯示設定,例如像下面這樣:
privatestaticfinalExecutorServiceexecutor=newThreadPoolExecutor(
2,
4,
1L,
TimeUnit.MINUTES,
newLinkedBlockingQueue<>(100),
newThreadFactoryBuilder().setNameFormat("common-pool-%d").build(),
newThreadPoolExecutor.CallerRunsPolicy());
參數的配置建議
CorePoolSize(核心執行緒數)
一般在配置核心執行緒數的時候,是需要結合執行緒池將要處理任務的特性來決定的,而任務的性質一般可以劃分為:CPU 密集型、I/O 密集型。
比較通用的配置方式如下
• CPU 密集型: 一般建議執行緒的核心數與 CPU 核心數保持一致。
• I/O 密集型: 一般可以設定 2 倍的 CPU 核心數的執行緒數,因為此類任務 CPU 比較空閑,可以多分配點執行緒充分利用 CPU 資源來提高效率。
透過
Runtime.getRuntime().availableProcessors()
可以獲取核心執行緒數。
另外還有一個公式可以借鑒
• 執行緒核心數 = cpu 核心數 / (1-阻塞系數)
• 阻塞系數 = 阻塞時間/(阻塞時間+使用 CPU 的時間)
實際上大多數線上業務所消耗的時間主要就是 I/O 等待,因此一般執行緒數都可以設定的多一點,比如 tomcat 中預設的執行緒數就是 200,所以最佳的核心執行緒數是需要根據特定場景,然後透過實際上線上允許結果分析後,再不斷的進行調整。
MaximumPoolSize
maximumPoolSize
的設定也是看實際套用場景,如果設定的和
corePoolSize
一樣,那就完全依靠阻塞佇列和拒絕策略來控制任務的處理情況,如果設定的比
corePoolSize
稍微大一點,那就可以更好的應對一些有突發流量產生的場景。
KeepAliveTime
由
maximumPoolSize
建立出來的執行緒,在經過
keepAliveTime
時間後進行銷毀,依據突發流量持續的時間來決定。
WorkQueue
那麽阻塞佇列應該設定多大呢?我們知道當執行緒池中所有的執行緒都在工作時,如果再有任務進來,就會被放到阻塞佇列中等待,如果阻塞佇列設定的太小,可能很快佇列就滿了,導致任務被丟棄或者異常(由拒絕策略決定),如果佇列設定的太大,又可能會帶來記憶體資源的緊張,甚至 OOM,以及任務延遲時間過長。
所以阻塞佇列的大小,又是要結合實際場景來設定的。
一般會根據處理任務的速度與任務產生的速度進行計算得到一個大概的數值。
假設現在有 1 個執行緒,每秒鐘可以處理 10 個任務,正常情況下每秒鐘產生的任務數小於 10,那麽此時佇列長度為 10 就足以。
但是如果高峰時期,每秒產生的任務數會達到 20,會持續 10 秒,且任務又不希望丟棄,那麽此時佇列的長度就需要設定到 100。
監控 workQueue 中等待任務的數量是非常重要的,只有了解實際的情況,才能做出正確的決定。
在有些場景中,可能並不希望因為任務被丟進阻塞佇列而等待太長的時間,而是希望直接開啟設定的
MaximumPoolSize
執行緒池數來執行任務,這種情況下一般可以直接使用
SynchronousQueue
佇列來實作
ThreadFactory
透過 threadFactory 我們可以自訂執行緒組的名字,設定合理的名稱將有利於你線上進行問題排查。
Handler
最後拒絕策略,這也是要結合實際的業務場景來決定采用什麽樣的拒絕方式,例如像過程類的數據,可以直接采用
DiscardOldestPolicy
策略。
執行緒池的監控
線上使用執行緒池時,一定要做好監控,以便根據實際執行情況進行調整,常見的監控方式可以透過執行緒池提供的 API,然後暴露給 Metrics 來完成即時數據統計。
監控範例
執行緒池自身提供的統計數據
public classThreadPoolMonitor{
privatefinalstaticLoggerlog=LoggerFactory.getLogger(ThreadPoolMonitor. class);
privatestaticfinalThreadPoolExecutorthreadPool=newThreadPoolExecutor(2,4,0,
TimeUnit.SECONDS,newLinkedBlockingQueue<>(100),
newThreadFactoryBuilder().setNameFormat("my_thread_pool_%d").build());
publicstaticvoidmain(String[] args){
log.info("Pool Size: "+ threadPool.getPoolSize());
log.info("Active Thread Count: "+ threadPool.getActiveCount());
log.info("Task Queue Size: "+ threadPool.getQueue().size());
log.info("Completed Task Count: "+ threadPool.getCompletedTaskCount());
}
}
透過 micrometer API 完成統計,這樣就可以接入
Prometheus
了
package com.springboot.micrometer.monitor;
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import io.micrometer.core.instrument.Metrics;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
import java.util.stream.IntStream;
@Component
public classThreadPoolMonitor{
privatestaticfinalThreadPoolExecutorthreadPool=newThreadPoolExecutor(4,8,0,
TimeUnit.SECONDS,newLinkedBlockingQueue<>(100),
newThreadFactoryBuilder().setNameFormat("my_thread_pool_%d").build(),newThreadPoolExecutor.DiscardOldestPolicy());
/**
* 活躍執行緒數
*/
privateAtomicLongactiveThreadCount=newAtomicLong(0);
/**
* 佇列任務數
*/
privateAtomicLongtaskQueueSize=newAtomicLong(0);
/**
* 完成任務數
*/
privateAtomicLongcompletedTaskCount=newAtomicLong(0);
/**
* 執行緒池中當前執行緒的數量
*/
privateAtomicLongpoolSize=newAtomicLong(0);
@PostConstruct
privatevoidinit(){
/**
* 透過micrometer API完成統計
*
* gauge最典型的使用場景就是統計:list、Map、執行緒池、連線池等集合型別的數據
*/
Metrics.gauge("my_thread_pool_active_thread_count", activeThreadCount);
Metrics.gauge("my_thread_pool_task_queue_size", taskQueueSize);
Metrics.gauge("my_thread_pool_completed_task_count", completedTaskCount);
Metrics.gauge("my_thread_pool_size", poolSize);
// 模擬執行緒池的使用
newThread(this::runTask).start();
}
privatevoidrunTask(){
// 每5秒監控一次執行緒池的使用情況
monitorThreadPoolState();
// 模擬任務執行
IntStream.rangeClosed(0,500).forEach(i ->{
// 每500毫秒,執行一個任務
try{
TimeUnit.MILLISECONDS.sleep(500);
}catch(InterruptedException e){
e.printStackTrace();
}
// 每個處理一個任務耗時5秒
threadPool.submit(()->{
try{
TimeUnit.MILLISECONDS.sleep(5000);
}catch(InterruptedException e){
e.printStackTrace();
}
});
});
}
privatevoidmonitorThreadPoolState(){
Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(()->{
activeThreadCount.set(threadPool.getActiveCount());
taskQueueSize.set(threadPool.getQueue().size());
poolSize.set(threadPool.getPoolSize());
completedTaskCount.set(threadPool.getCompletedTaskCount());
},0,5,TimeUnit.SECONDS);
}
}
執行緒池的資源隔離
在生產環境中,一定要註意好資源隔離的問題,盡量不要將不同型別,不同重要等級的任務放入一個執行緒池中,以免因為執行緒資源爭搶而互相影響。
5. 服務預熱
服務預熱也是很常見的一種最佳化手段,例如資料庫連線、執行緒池中的核心執行緒,緩存等資訊可以利用服務啟動階段預先載入,從而避免請求到來後臨時構建的耗時。
下面提供一些預載入的方式
執行緒池
執行緒池本身提供了相關的 API:
prestartAllCoreThreads()
透過該方法可以提前將核心執行緒建立好,非常方便。
Web 服務
常見的如 Tomcat,其本身也用到了執行緒池,只是其自身已經考慮到了預載入的問題,不需要我們額外處理了。
連線池
連線池常用的一般就是資料庫連線池以及Redis連線池,大多數這些連線的客戶端也都做了連線提前載入的工作,遇到沒有預載入的參考其他客戶端方式搞一下即可。
緩存
一般本地緩存可以在每次服務啟動時預先載入好,以免出現緩存擊穿的情況。
靜態程式碼塊
在服務啟動時,靜態程式碼塊中的相關功能會優先被載入,可以有效避免在執行時再載入的情況。
其他擴充套件
預熱實際上可聊的內容很多,一般有用到池化技術的方式,都是需要預熱的,為了能夠提升響應效能,將不在記憶體中的數據提前查好放入記憶體中,或者將需要計算的數據提前計算好,這都是很容易想到的解決方式。
此外還有一些伺服端在設計之初就會針對性地對一些熱點數據進行特殊處理,比如JVM中的JIT、記憶體分配比;OS中的
page cache
;MySQL中的
innodb_buffer_pool
等,這些一般可以透過流量預熱的方式來使其達到最佳狀態。
6. 緩存對齊
CPU的多級緩存
CPU緩存通常分為大小不等的三級緩存
來自百度百科對三級緩存分類的介紹:
一級緩存都內建在CPU內部並與CPU同速執行,可以有效的提高CPU的執行效率。一級緩存越大,CPU的執行效率越高,但受到CPU內部結構的限制,一級緩存的容量都很小。
二級緩存,它是為了協調一級緩存和記憶體之間的速度。cpu呼叫緩存首先是一級緩存,當處理器的速度逐漸提升,會導致一級緩存就供不應求,這樣就得提升到二級緩存了。二級緩存它比一級緩存的速度相對來說會慢,但是它比一級緩存的空間容量要大。主要就是做一級緩存和記憶體之間數據臨時交換的地方用。
三級緩存是為讀取二級緩存後未命中的數據設計的—種緩存,在擁有三級緩存的CPU中,只有約5%的數據需要從記憶體中呼叫,這進一步提高了CPU的效率。其運作原理在於使用較快速的儲存裝置保留一份從慢速儲存裝置中所讀取數據並進行拷貝,當有需要再從較慢的儲存體中讀寫數據時,緩存(cache)能夠使得讀寫的動作先在快速的裝置上完成,如此會使系統的響應較為快速。
效果演示
逐行寫入
public classCacheLine{
publicstaticvoidmain(String[] args){
int[][] arr =newint[10000][10000];
longs=System.currentTimeMillis();
for(inti=0; i < arr.length; i++){
for(intj=0; j < arr[i].length; j++){
arr[i][j]=0;
}
}
longe=System.currentTimeMillis();
System.out.println(e-s);
}
}
逐列寫入
public classCacheLine{
publicstaticvoidmain(String[] args){
int[][] arr =newint[10000][10000];
longs=System.currentTimeMillis();
for(inti=0; i < arr.length; i++){
for(intj=0; j < arr[i].length; j++){
arr[j][i]=0;
}
}
longe=System.currentTimeMillis();
System.out.println(e-s);
}
}
雖然兩種方式得到的結果是一樣的,但效能對比卻相差巨大,這就是緩存行帶來的影響。
原因分析
CPU的緩存是由多個緩存行組成的,以緩存行為基本單位,一個緩存行的大小一般為64字節,二維陣列在記憶體中保存時,實際上是以按行遍歷的方式進行保存,比如:
arr[0][0]
,
arr[0][1]
,
arr[1][0]
,
arr[1][1]
,
arr[2][0]
,
arr[2][1]
...
所以當按行存取時,是按照記憶體儲存的順序進行存取,那麽CPU緩存後面的元素就可以利用到,而如果是按列存取,那麽CPU的緩存是沒有用的。
緩存行對齊
public classCacheLinePadding{
privatestatic classPadding{
// 一個long是8個字節,一共7個long
// public volatile long p1, p2, p3, p4, p5, p6, p7;
}
privatestatic classTextendsPadding{
// x變量8個字節,加上Padding中的變量,剛好64個字節,獨占一個緩存行。
publicvolatilelongx=0L;
}
publicstatic T[] arr =newT[2];
static{
arr[0]=newT();
arr[1]=newT();
}
publicstaticvoidmain(String[] args)throwsException{
Threadt1=newThread(()->{
for(longi=0; i <10000000; i++){
arr[0].x = i;
}
});
Threadt2=newThread(()->{
for(longi=0; i <10000000; i++){
arr[1].x = i;
}
});
finallongstart=System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime()- start)/100000);
}
}
同樣的含有
public volatile long p1, p2, p3, p4, p5, p6, p7;
這一行程式碼與不含效能也相差巨大,這同樣也是因為緩存行的原因,當執行在兩個不同CPU上的兩個執行緒要寫入。
7. 減少物件的產生
避免使用包裝型別
因為包裝型別的建立和銷毀都會產生臨時物件,因此相比基本數據型別來說,會帶來額外的消耗。
public classMain{
publicstaticvoidmain(String[] args){
longs=System.currentTimeMillis();
testInteger();
longe=System.currentTimeMillis();
System.out.println(e - s);
testInt();
longe2=System.currentTimeMillis();
System.out.println(e2 - e);
}
privatestaticvoidtestInt(){
intsum=1;
for(inti=1; i <50000000; i++){
sum++;
}
System.out.println(sum);
}
privatestaticvoidtestInteger(){
Integersum=1;
for(inti=1; i <50000000; i++){
sum++;
}
System.out.println(sum);
}
}
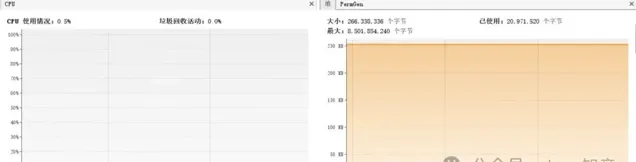
兩個方法不僅執行時間相差百倍,在CPU和記憶體的消耗上Integer也明顯弱於int。
Integer記憶體和CPU都能看到明顯的波動
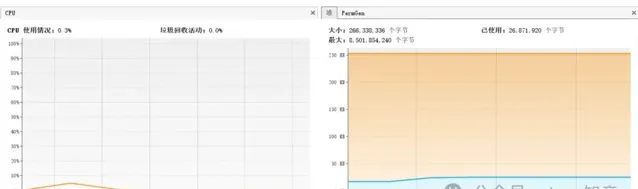
int幾乎沒波動
使用不可變物件
最為典型的案例就是String,我想應該不會有人去透過new的方式再去構建一個String字串了吧!
Stringstr = newString("abc");
Stringstr = "abc";
同時,在實作字串連線時通常使用StringBuilder或StringBuffer,這樣可以避免使用連線符,導致每次都建立新的字串物件。
靜態方法
靜態物件
Boolean.valueOf("true");
publicstaticBooleanvalueOf(String s){
return parseBoolean(s)? TRUE : FALSE;
}
publicstaticfinalBooleanTRUE=newBoolean(true);
publicstaticfinalBooleanFALSE=newBoolean(false);
靜態工廠(單例模式)
public classStaticSingleton{
privatestatic classStaticHolder{
publicstaticfinalStaticSingletonINSTANCE=newStaticSingleton();
}
publicstaticStaticSingletongetInstance(){
returnStaticHolder.INSTANCE;
}
}
列舉
publicenumEnumSingleton { INSTANCE; }
檢視
檢視是返回參照的一種方式。
map的keySet方法,實際上每次返回的都是同一個物件的參照。
public Set<K>keySet(){
Set<K> ks = keySet;
if(ks ==null){
ks =newKeySet();
keySet = ks;
}
return ks;
}
物件池
物件池可以有效減少頻繁的物件建立和銷毀的過程,一般情況下如果每次建立物件的過程較為復雜,且物件占用空間又比較大,那麽就建議使用物件池的方式來最佳化。
使用範例
org.apache.commons
提供了物件池的工具類,可以直接拿來使用
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.11.1</version>
</dependency>
池化的物件
@Data
public classCache {
privatebyte[] size;
}
池化物件工廠
public classCachePoolObjectFactoryextendsBasePooledObjectFactory<Cache>{
@Override
publicCachecreate(){
Cachecache=newCache();
cache.setSize(newbyte[1024*1024*16]);
return cache;
}
@Override
publicPooledObject<Cache>wrap(Cache cache){
returnnewDefaultPooledObject<>(cache);
}
}
物件池工具
import org.apache.commons.pool2.impl.GenericObjectPool;
import org.apache.commons.pool2.impl.GenericObjectPoolConfig;
import java.time.Duration;
publicenumCachePoolUtil{
INSTANCE;
privateGenericObjectPool<Cache> objectPool;
CachePoolUtil(){
GenericObjectPoolConfig<Cache> poolConfig =newGenericObjectPoolConfig<>();
// 物件池中最大物件數
poolConfig.setMaxTotal(50);
// 物件池中最小空閑物件數
poolConfig.setMinIdle(20);
// 物件池中最大空閑物件數
poolConfig.setMaxIdle(20);
// 獲取物件最大等待時間 預設 -1 一直等待
poolConfig.setMaxWait(Duration.ofSeconds(3));
// 建立物件工廠
CachePoolObjectFactoryobjectFactory=newCachePoolObjectFactory();
// 建立物件池
objectPool =newGenericObjectPool<>(objectFactory, poolConfig);
}
/**
* 從物件池中取出一個物件
*/
publicCacheborrowObject()throwsException{
return objectPool.borrowObject();
}
publicvoidreturnObject(Cache cache){
// 將物件歸還給物件池
objectPool.returnObject(cache);
}
/**
* 獲取活躍的物件數
*/
publicintgetNumActive(){
return objectPool.getNumActive();
}
/**
* 獲取空閑的物件數
*/
publicintgetNumIdle(){
return objectPool.getNumIdle();
}
}
public classMain{
publicstaticvoidmain(String[] args){
CachePoolUtilcachePoolUtil=CachePoolUtil.INSTANCE;
for(inti=0; i <10; i++){
newThread(newRunnable(){
@SneakyThrows
@Override
publicvoidrun(){
while(true){
Thread.sleep(100);
// 使用物件池
Cachecache= cachePoolUtil.borrowObject();
m(cache);
cachePoolUtil.returnObject(cache);
// 不使用物件池
//Cache cache = new Cache();
//cache.setSize(new byte[1024 * 1024 * 2]);
//m(cache);
}
}
}).start();
}
}
// 無特殊作用
publicstaticvoidm(Cache cache){
if(cache.getSize().length <10){
System.out.println(cache);
}
}
}
使用物件池
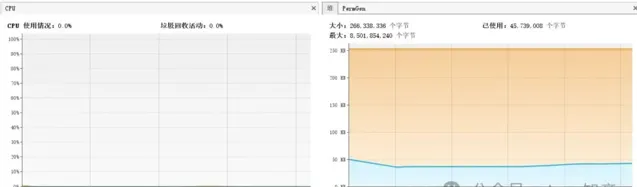
不適用物件池
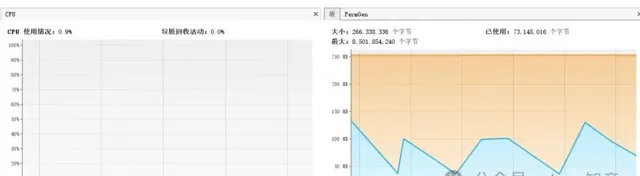
8. 並行處理
鎖的粒度控制
並行場景下就要考慮執行緒安全的問題,常見的解決方式:volatile、CAS、自旋鎖、物件鎖、類鎖、分段鎖、讀寫鎖,理論上來說,鎖的粒度越小,並列效果就越高。
volatile
volatile是Java中的一個關鍵字,用於修飾變量。它的作用是保證被volatile修飾的變量在多執行緒環境下的可見性和禁止指令重排序。
volatile雖然不能保證原子性,但如果對共享變量是純賦值或讀取的操作,那麽因為volatile保證了可見性,因此也是可以實作執行緒安全的。
CAS
compare and swap(比較並交換),CAS主要有三個參數,
• V:記憶體值
• A:當前時
• B:待更新的值
若且唯若V等於A時,就將A更新為B,否則什麽都不做。V和A的比較是一個原子性操作保證執行緒安全。
Random透過cas的方式保證了執行緒安全,但在高並行下很有可能會失敗,造成頻繁的重試。
protectedintnext(int bits){
long oldseed, nextseed;
AtomicLongseed=this.seed;
do{
oldseed = seed.get();
nextseed =(oldseed * multiplier + addend)& mask;
}while(!seed.compareAndSet(oldseed, nextseed));
return(int)(nextseed >>>(48- bits));
}
ThreadLocalRandom進行了最佳化,其主要方式就是分段,透過讓每個執行緒擁有獨立的儲存空間,這樣即保證了執行緒安全,同時效率也不會太差。
publicstaticThreadLocalRandomcurrent(){
if(U.getInt(Thread.currentThread(), PROBE)==0)
localInit();
return instance;
}
staticfinalvoidlocalInit(){
intp= probeGenerator.addAndGet(PROBE_INCREMENT);
intprobe=(p ==0)?1: p;// skip 0
longseed= mix64(seeder.getAndAdd(SEEDER_INCREMENT));
Threadt=Thread.currentThread();
U.putLong(t, SEED, seed);
U.putInt(t, PROBE, probe);
}
publicintnextInt(){
return mix32(nextSeed());
}
finallongnextSeed(){
Thread t;long r;// read and update per-thread seed
U.putLong(t =Thread.currentThread(), SEED,
r = U.getLong(t, SEED)+ GAMMA);
return r;
}
物件鎖、類鎖
主要就是透過synchronized實作,是最基礎的鎖機制。
自旋鎖
在自旋鎖中,當一個操作需要存取一個共享資源時,它會檢查這個資源是否被其他操作占用。如果是,它會一直等待,直到資源被釋放。在等待期間,這個操作會進入一個自旋狀態,也就是不會被系統掛起,但是也不會繼續執行其他任務。當資源被釋放後,這個操作會立即返回並繼續執行下一步操作。
自旋鎖是一種簡單而有效的同步機制,自旋鎖的優點是減少執行緒上下文切換的開銷,但是它也有一些缺點。由於它需要一直進行自旋操作,所以會消耗一定的CPU資源。因此,在使用自旋鎖時需要仔細考慮並行問題和效能問題。
分段鎖
在分段鎖的模型中,共享數據被分割成若幹個段,每個段都被一個鎖所保護,同時只有一個執行緒可以在同一時刻對同一段進行加鎖和解鎖操作。這種鎖機制可以降低鎖的競爭,提高並行存取的效率。
ConcurrentHashMap的設計就是采用分段鎖的思想,其會按照map中的table capacity(預設16)來劃分,也就是說每個執行緒會鎖1/16的數據段,這樣一來就大大提升了並行存取的效率。
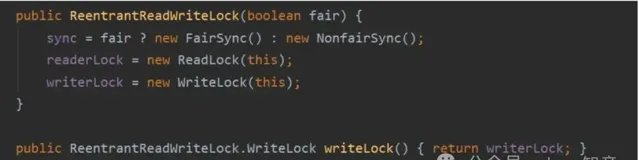
讀寫鎖
讀寫鎖主要根據大多數業務場景都是讀多寫少的情況,在讀數據時,無論多少執行緒同時存取都不會有安全問題,所以在讀數據的時候可以不加鎖,不過一旦有寫請求時就需要加鎖了。
• 讀、讀:不沖突
• 讀、寫:沖突
• 寫、寫:沖突
典型的如:
ReentrantReadWriteLock
寫時復制
寫時復制最大的優勢在於,在寫數據的過程時,不影響讀,可以理解為讀的是數據的副本,而只有當數據真正寫完後才會替換副本,當副本特別大、寫數據過程比較漫長時,寫時復制就特別有用了。
CopyOnWriteArrayList
、
CopyOnWriteArraySet
就是集合操作時,為保證執行緒安全,使用寫時復制的實作
public E get(int index){
return elementAt(getArray(), index);
}
finalObject[] getArray(){
return array;
}
publicbooleanadd(E e){
synchronized(lock){
Object[] es = getArray();
intlen= es.length;
es =Arrays.copyOf(es, len +1);
es[len]= e;
setArray(es);
returntrue;
}
}
finalvoidsetArray(Object[] a){
array = a;
}
寫時復制也存在兩個問題,可以看到在add方法時使用了synchronized,也就是說當存在大量的寫入操作時,效率實際上是非常低的,另一個問題就是需要copy一份一模一樣的數據,可能會造成記憶體的異常波動,因此寫時復制實際上適用於讀多寫少的場景。
對比說明
import java.util.Collections;
import java.util.Iterator;
import java.util.Set;
import java.util.UUID;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.CopyOnWriteArraySet;
import java.util.concurrent.CountDownLatch;
public classThreadSafeSet{
publicstaticvoidmain(String[] args)throwsInterruptedException{
//Set<String> set = ConcurrentHashMap.newKeySet();
//CopyOnWriteArraySet<String> set = new CopyOnWriteArraySet();
readMoreWriteLess(set);
System.out.println("==========華麗的分隔符==========");
//set = ConcurrentHashMap.newKeySet();
//set = new CopyOnWriteArraySet();
writeMoreReadLess(set);
}
privatestaticvoidwriteMoreReadLess(Set<String> set)throwsInterruptedException{
//測20組
for(intk=1; k <=20; k++){
CountDownLatchcountDownLatch=newCountDownLatch(10);
longs=System.currentTimeMillis();
//建立9個執行緒,每個執行緒向set中寫1000條數據
for(inti=0; i <9; i++){
newThread(()->{
for(intj=0; j <1000; j++){
set.add(UUID.randomUUID().toString());
}
countDownLatch.countDown();
}).start();
}
//建立1個執行緒,每個執行緒從set中讀取所有數據,每個執行緒一共讀取10次。
for(inti=0; i <1; i++){
newThread(()->{
for(intj=0; j <10; j++){
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()){
iterator.next();
}
}
countDownLatch.countDown();
}).start();
}
//阻塞,直到10個執行緒都執行結束
countDownLatch.await();
longe=System.currentTimeMillis();
System.out.println("寫多讀少:第"+ k +"次執行耗時:"+(e - s)+"毫秒"+",容器中元素個數為:"+ set.size());
}
}
privatestaticvoidreadMoreWriteLess(Set<String> set)throwsInterruptedException{
//測20組
for(intk=1; k <=20; k++){
CountDownLatchcountDownLatch=newCountDownLatch(10);
longs=System.currentTimeMillis();
//建立1個執行緒,每個執行緒向set中寫10條數據
for(inti=0; i <1; i++){
newThread(()->{
for(intj=0; j <10; j++){
set.add(UUID.randomUUID().toString());
}
countDownLatch.countDown();
}).start();
}
//建立9個執行緒,每個執行緒從set中讀取所有數據,每個執行緒一共讀取100萬次。
for(inti=0; i <9; i++){
newThread(()->{
for(intj=0; j <1000000; j++){
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()){
iterator.next();
}
}
countDownLatch.countDown();
}).start();
}
countDownLatch.await();
longe=System.currentTimeMillis();
System.out.println("讀多寫少:第"+ k +"次執行耗時:"+(e - s)+"毫秒"+",容器中元素個數為:"+ set.size());
}
}
}
經過測試可以發現在讀多寫少時
CopyOnWriteArraySet
會明顯優於
ConcurrentHashMap.newKeySet()
,但在寫多讀少時又會明顯弱於
ConcurrentHashMap.newKeySet()
。
當然使用
CopyOnWriteArraySet
還需要註意一點,寫入的數據可能不會被及時的讀取到,因為遍歷的是讀取之前獲取的快照。
這段程式碼可以測試
CopyOnWriteArraySet
寫入數據不能被及時讀取到的問題。
public classCOWSetTest{
publicstaticvoidmain(String[] args)throwsInterruptedException{
CopyOnWriteArraySet<Integer> set =newCopyOnWriteArraySet();
newThread(()->{
try{
set.add(1);
System.out.println("第一個執行緒啟動,添加了一個元素,睡100毫秒");
Thread.sleep(100);
set.add(2);
set.add(3);
System.out.println("第一個執行緒添加了3個元素,執行結束");
}catch(InterruptedException e){
e.printStackTrace();
}
}).start();
//保證讓第一個執行緒先執行
Thread.sleep(1);
newThread(()->{
try{
System.out.println("第二個執行緒啟動了!睡200毫秒");
//Thread.sleep(200);//如果在這邊睡眠,可以獲取到3個元素
Iterator<Integer> iterator = set.iterator();//生成快照
Thread.sleep(200);//如果在這邊睡眠,只能獲取到1個元素
while(iterator.hasNext()){
System.out.println("第二個執行緒開始遍歷,獲取到元素:"+ iterator.next());
}
}catch(InterruptedException e){
e.printStackTrace();
}
}).start();
}
}
9. 異步
異步是提升系統響應能力的重要手段之一,異步思想的套用也非常的廣泛,常見的有:執行緒、MQ、事件通知、響應式編程等方式,有些概念在前面的章節中也涉及到了,異步最核心的思想就是,先快速接收,後查詢結果,比如:如果介面處理時間較長,那麽可以優先響應中間狀態(處理中),然後提供回呼和查詢介面,這樣就可以大大提升介面的吞吐量!
10. for迴圈最佳化
減少迴圈
通常可以透過一些高效的演算法或者數據結構來減少迴圈次數,尤其當出現巢狀迴圈時要格外小心。 常見的方式比如:有序的尋找可以用二分,排序可以用快排,檢索可以構建Hash索引等等。
批次獲取
最佳化前:每次查詢一次資料庫
for(String userId : userIds){
Useruser = userMapper.queryById(userId);
if(user.getName().equals("xxx")){
// ...
}
}
最佳化後:先批次查詢出來,再處理
Map<String, User> userMap = userMapper.queryByIds(userIds);
for(String userId : userIds){
Useruser = userMap.get(userId);
if(user.getName().equals("xxx")){
// ...
}
}
緩存結果
最佳化前:每次都要根據每個使用者的roleId去資料庫查詢一次。
Map<String, User> userMap = userMapper.queryByIds(userIds);
for(String userId : userIds){
Useruser = userMap.get(userId);
Rolerole = roleMapper.queryById(user.getRoleId());
}
最佳化後:每次根據roleId查詢過以後就暫記下來,後面再遇到相同roleId時即可直接獲取,這比較適用於一次迴圈中roleId重復次數較多的場景。
Map<String,User> userMap = userMapper.queryByIds(userIds);
Map<String,Role> roleMap =newHashMap<>();
for(String userId : userIds){
Useruser= userMap.get(userId);
Rolerole= roleMap.get(user.getRoleId());
if(role ==null){
role = roleMapper.queryById(user.getRoleId());
roleMap.put(user.getRoleId(), role);
}
}
並列處理
典型的如parallelStream
Integersum = numbers.parallelStream().reduce(0, Integer::sum);
11. 減少網路傳輸的體積
精簡欄位
1.資料庫查詢時要避免頻繁查詢大文本欄位,常見的如下面幾種:
select url, describe, remark from t
2.介面傳輸時同樣要註意盡量減少內容傳輸的大小。
3.精簡欄位除了透過減少不必要的欄位傳輸之外,也可以透過改變數據結構,數據型別來實作。
數據傳輸格式
常用的如JSON,語法簡單,相比XML來說傳輸體積更小,解析更快,但如果需要頻繁傳輸大量數據時,使用protobuf則更會更加高效,因為其采用結構化的數據描述語言,並使用二進制編碼,因為體積更小,速度更快。
壓縮
常見的資料壓縮方式如:GZIP、zlib,而zip常用於檔壓縮。
借助Hutool工具包,可以看下壓縮的效果
gzip壓縮
StringBuildersb=newStringBuilder();
for(inti=0; i <1000; i++){
sb.append(i);
}
System.out.println("壓縮前:"+ sb.toString().getBytes().length);
byte[] compressedBytes =ZipUtil.gzip(sb.toString(),CharsetUtil.UTF_8);
System.out.println("壓縮後:"+ compressedBytes.length);
Stringstr=ZipUtil.unGzip(compressedBytes,CharsetUtil.UTF_8);
System.out.println("壓縮還原:"+ str.getBytes().length);
壓縮前:2890
壓縮後:1474
壓縮還原:2890
zlib壓縮
StringBuildersb=newStringBuilder();
for(inti=0; i <1000; i++){
sb.append(i);
}
System.out.println("壓縮前:"+ sb.toString().getBytes().length);
byte[] compressedBytes =ZipUtil.zlib(sb.toString(),CharsetUtil.UTF_8,1);
System.out.println("壓縮後:"+ compressedBytes.length);
Stringstr=ZipUtil.unZlib(compressedBytes,CharsetUtil.UTF_8);
System.out.println("壓縮還原:"+ str.getBytes().length);
壓縮前:2890
壓縮後:1518
壓縮還原:2890
12. 減少服務之間的依賴
依賴越多,不但會給服務的穩定性、可靠性造成影響,同時也會成為效能提升的瓶頸,因此我們在設計之初就應當充分考慮到這個問題,透過合理的手段來減少服務之間的依賴。
鏈路治理
透過合理的微服務劃分,可以有效的減少鏈路上的依賴,鏈路呼叫之間要避免出現重復呼叫,迴圈依賴,以及上、下層級互相呼叫的情況。
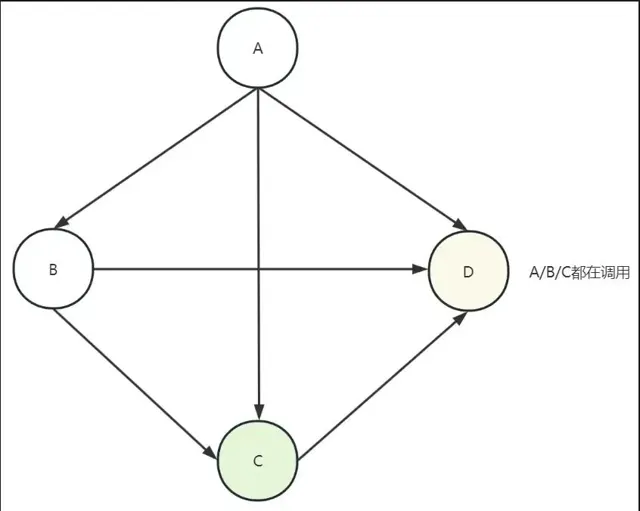
重復呼叫
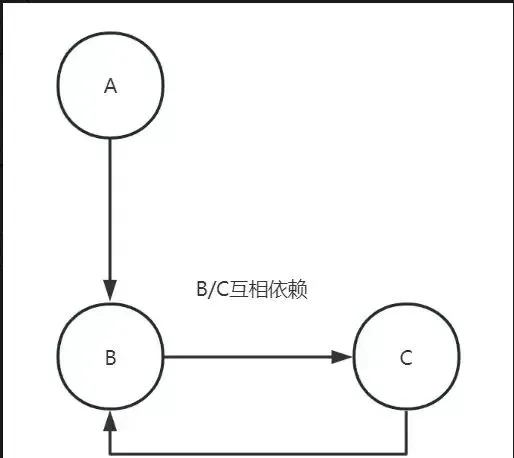
迴圈依賴
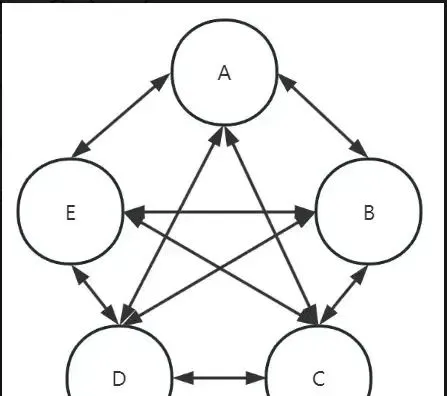
服務上、下層級混亂,互相呼叫
數據冗余
數據冗余是指將非自身維護的數據透過某種手段保存下來,以便在之後使用時避免多次發起數據請求,從而實作減少服務依賴的手段。
常見的方式如:通用的基礎數據,字典數據等各個需求方可復制一份存在本地;建立寬表,冗余部份數據,減少關聯查詢。
結果緩存
將需要頻繁使用的結果儲存在緩存服務中,也是有效減少服務依賴的方式之一。
訊息佇列
訊息佇列天然就有簡化系統復雜性的作用,它透過異步的方式將任務與任務之間的關系進行解耦,也就達到了減少服務之間依賴的效果。
來源:juejin.cn/post/7271276760905023549
— END —
PS:防止找不到本篇文章,可以收藏點贊,方便翻閱尋找哦。
往期推薦











