一、Anthropic的成立背景
Anthropic是一家專註於人工智慧安全和負責任開發的初創公司,成立於2021年,其創始團隊都是GPT系列產品的早期開發者。在2020年6月,OpenAI推出了第三代大型語言模型GPT-3。然而,由於對OpenAI未來發展方向的擔憂,特別是對微軟投資可能導致的商業化傾向和對AI安全性研究的忽視,OpenAI的研究副總裁Dario Amodei和安全政策副總裁Daniela Amodei決定離開。
2021年,他們與另外 5 名 OpenAI 成員,包括GPT-3模型的主要開發者Tom Brown,一同創立了Anthropic,旨在構建可靠的(Reliable)、可解釋的(Interpretable)和可操控的(Steerable)AI 系統。
Anthropic的目標本質上是開發使AI系統更安全的技術和辨識AI系統安全或危險程度的方法。 公司名Anthropic意為」與人類有關的」。
Anthropic與OpenAI等頭部大模型公司不同,主要采用to B商業化的模式。
目前,Claude的客戶包括科技公司Gitlab(軟體開發工具)、Notion(筆記應用程式)、Quora(海外問答平台)和Salesforce(Anthropic的投資者);金融巨頭橋水公司(Bridgewater)和企業集團SAP,以及商業研究入口網站LexisNexis、電信公司SK Telecom和丹娜法伯癌癥研究所(Dana-Farber Cancer Institute)。
據外媒The Information報道,Anthropic預測2023年度收入達到2億美金,而2024年底其年化收入將超過8.5億美元。
二、團隊構成與專業背景
Anthropic 的創始團隊成員,大多為 OpenAI 的重要員工或關聯成員,這些人曾是 OpenAI 的中堅力量,參與了 OpenAI 的多項研究。在 GPT-3 論文 Language Models are Few-Shot Learners 中,前兩位作者(Tom Brown 和 Ben Mann)和最後一位通訊作者、計畫負責人(Dario Amodei)目前均在 Anthropic 工作。該論文的 31 名作者中,有 8 名目前在 Anthropic 工作。
(一)Dario Amodei-全職CEO兼聯合創始人
Dario Amodei,義大利裔美國人,博士畢業於普林斯頓大學,後回到本科畢業的史丹佛大學擔任博士後學者。Dario於2021年2月創辦了 Anthropic 公司,任 CEO職位。他是 OpenAI 的前核心成員,也被認為是深度學習領域最為前沿的研究員之一。
Dario Amodei領導了GPT-2和GPT-3的開發工作,同時也是為OpenAI設定總體研究方向並撰寫年度研究路線圖的兩個人之一。曾發表多篇 AI 可解釋性、安全等方面的論文,離職前在 OpenAI 擔任研究 VP。在此之前,Dario 還曾在百度和谷歌擔任研究員。
(二)Daniela Amodei-聯合創始人、總裁
Daniela Amodei是Dario Amodei的姐妹,曾擔任OpenAI的安全政策副總裁。現擔任Anthropic總裁,在公司中負責領導團隊,並利用她在人員和管理方面的經驗來推進公司構建可靠、可解釋和可控的人工智慧系統的目標。
Daniela曾經在國際發展、公共健康、政府政策以及政治領域工作過。Daniela 對於如何使 AI 系統更加安全和以人為中心有著深刻的見解,並且在推動 AI 安全性研究方面發揮了重要作用。
(三)Tom Brown-聯合創始人
Tom Brown本科及碩士畢業於麻省理工學院。Tom Brown是Anthropic的聯合創始人之一,曾是Open AI的核心技術人員,參與過GPT-3的開發建設,領導GPT-3的工程,並負責模型並列分布式訓練基礎設施,將參數從1.5B擴充套件到170B。
在此之前,Tom Brown也擔任過谷歌大腦的技術人員。他是MoPub的創始工程師,也是 Grouper 的聯合創始人和技術長。
(四)Sam McCandlish-聯合創始人
Sam McCandlish本科及碩士畢業於布蘭迪斯大學,博士畢業於史丹佛大學理論物理專業。Sam於2018年加入Open AI擔任研究負責人,曾是核心成員之一。2021年離職後聯合創辦了Anthropic,研究方向是理學與哲學。
(五)Christopher Olah -聯合創始人
Christopher Olah是Anthropic的聯合創始人之一,也是 OpenAI 多模態神經元論文的作者之一。主要工作是將人工神經網路逆向工程成人類可以理解的演算法。此前,他曾在OpenAI領導可解釋性研究,在Google Brain工作,並與人共同創辦了專註於優秀溝通的科學期刊【蒸餾】(Distill)。
(六)Ben Mann-聯合創始人
Ben Mann是Anthropic的創始團隊成員之一,也曾是Open AI的核心技術人員。在此之前,Ben Mann也先後在Open AI、機器智慧研究所、谷歌擔任軟體工程師,離職谷歌後,自主創業,後再次以技術人員的身份入職Open AI。
(七)Jared Kaplan-聯合創始人
Jared Kaplan是一位理論物理學家,同時也是一位機器學習專家,於2021年聯合創辦了Anthropic。2018年起擔任霍普金斯大學副教授,主要研究領域是機器學習研究,包括神經模型的縮放規律以及GPT-3語言模型。曾為OpenAI合約研究顧問。
(八)Jack Clark -聯合創始人兼政策主管
Jack Clark 是 Anthropic 公司的聯合創始人兼政策主管。Jack Clark 還擔任史丹佛大學人工智慧研究所(Stanford HAI)的 AI 指數指導委員會的聯合主席。
三、Anthropic的主要產品
大語言模型Claude
1、Claude模型發展歷史
2023年3月,Anthropic推出了早期的Claude版本,最早是Claude和Claude Instant兩個模型,能夠處理內容的最長長度為9000個token,提供API和Slack平台上的機器人兩個渠道。
2023年7月,Anthropic推出Claude 2,推出自有網站claude.ai上的面向公眾版本,提供高達100K token(大約相當於 75,000 個單詞)上下文視窗,顯著優於GPT-3和GPT-4,這也是Claude 2的核心競爭力。
2023年11月,Anthropic緊貼著OpenAI的GPT-4 Turbo在同月推出Claude 2.1,Claude 2.1 為企業提供了關鍵功能,業界領先200K token上下文視窗(是 Claude 2.0 的 2 倍)、降低了幻覺率(減少50%)、提高了長文件的準確性(錯誤減少30%)、系統提示以及用於函式呼叫和工作流程編排的測試版工具使用功能。
2024年3月,Anthropic推出他們新一代的大模型Claude 3 模型系列,該系列包含三個模型,按能力由弱到強排列分別是 Claude 3 Haiku、Claude 3 Sonnet 和 Claude 3 Opus。
2、Claude 3大模型評估
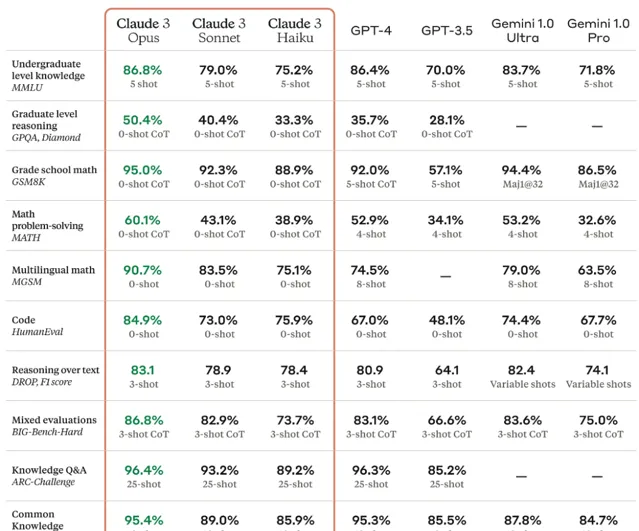
根據Anthropic公布的技術報告,能力最強的 Opus在大多數常見的 AI 系統評估基準上都優於同行,超過了 GPT-4 和 Gemini 1.0 Ultra,包括MMLU (大規模多工語言理解)、GPQA(研究生水平專家推理)、GSM8K(基礎數學)等。Sonnet的效能與GPT-4不相上下;Haiku則略遜於GPT-4。不過,這項測試中沒有包含剛剛更新的GPT-4 Turbo和Gemini 1.5 Pro。
不過根據業界反饋MMLU(大規模多工語言理解)/ GSM8K (基礎數學)/ HumanEval(編程能力)等熱門指標實質基本飽和,雖然Claude 3在HumanEval指標數據上顯示效果表現優異,但業界基本認為頭部大模型在這些指標上效能幾乎一樣。
Claude 3 Opus最大的亮點是在GPQA(研究生水平專家推理)和Math(數學問題解決)這兩部份評估指標的突破。
GPQA(研究生水平專家推理)
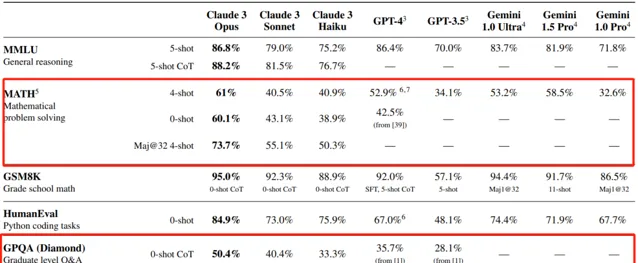
GPQA(Graduate-Level Google-Proof Q&A),是一個由生物學、物理學和化學領域專家編寫的具有挑戰性的多項選擇題數據集,Claude 3 Opus在GPQA上用0-shot CoT(僅加入「Let's think step by step.」 的思維鏈)準確率約為50%,用Maj@32 5-shot CoT(32次結果擇多數,增加5次示範和思維鏈)準確率約為60%。
這是一個極大的突破,即使是擁有博士學位(與待解決問題屬於不同領域)且可以存取互聯網,準確率也只有34%。而在同一領域且擁有博士學位的人(同樣可以存取互聯網)的準確率在65%到75%之間。由於Claude 3.0的數據集截止到2023年8月,而GPQA Bechmark的釋出時間在2023年11月,Claude 3.0完全沒有機會去「刷題」,能力是天然的。
Math(數學問題解決)
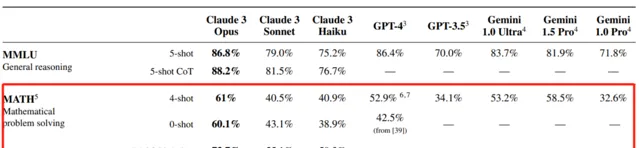
Math(數學問題解決)是一個相較GSM8K(基礎數學)更高要求的數學問題解決能力評估指標,包含12,500個具有挑戰性的新數據集競賽數學問題。Claude 3 Opus在Math上用0-shot(不進行示範問答)準確率約為60%,用Maj@32 4-shot(32次結果擇多數,4次示範)準確率約為73.7%,數學問題解決能力上的突破更能凸顯Claude 3 Opus在技術上的突破。
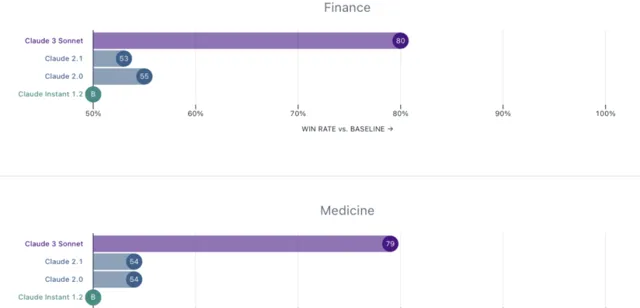
領域專家評估
Anthropic特別邀請了金融、醫學、哲學和STEM(科學、技術、工程和數學)領域的專家對公司的歷史模型進行了評估,從結果上看,公司的中間層產品Claude 3 Sonnet相較公司歷史模型都有了極大的提高,偏好勝率在60-80%。
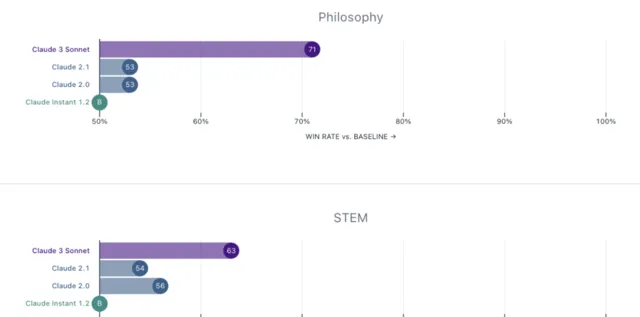
3、Claude 3上下文長度和召回率
Claude在GPT-4時代仍然可以獲得大量使用者的最核心競爭力,主要就依靠其較強的長上下文文本記憶能力。Claude 2擁有的100k token上下文能力,讓它在面對論文、報告等長內容時,準確率和細致程度遠超只支持32k上下文的原初GPT-4版本。
自GPT-4Turbo升級到提供128k上下文長度之後,Claude的這一優勢就再難彰顯。同月,Claude緊急推出2.1版本,支持200k上下文長度,但在實際體驗上,大家很快就發現Claude 2.1雖然支持文本長,但召回率很低,很多內容都會被忽略或遺失,不具有實用性。
Claude 3.0 支持200k token的上下文輸入,在Claude 3 Opus模型下的召回率能達到98.3%,基本上能做到無遺忘,長文本支持得到真正實作。

4、Claude 3模型定位及定價
從特性上看,Claude 3三款模型針對不同的場景:
①Opus:最強大、最智慧,是Anthropic的主力大模型
②Sonnet:價效比最高,在對比中顯著超過Claude 2.0、Claude 2.1。
③Haiku:成本最優,市場上速度最快、成本效益最高的模型。
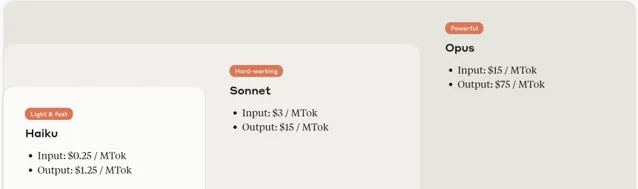
在定價上(ToB,每百萬tokens)
① Opus:$15 (input) / $75(output)。對標模型為GPT-4,它的定價水平與GPT-4相當,高於GPT-4 Turbo。
② Sonnet:$3(input) / $15(output)。在中型模型中定價具有競爭力,比所有GPT-4版本便宜,在品質上接近Mistral Large,但在價格上更接近Mistral Medium。
③ Haiku:$0.25(input) / $1.25(output)。價格非常有競爭力,最接近小型模型,同時在能力上可以與中型模型競爭。
四、Anthropic的AI研究工作
(一)Anthropic團隊對AI的看法
Anthropic 秉持兩個重要的信念:無限進步和安全。前者是指只要不斷增加計算資源,這些語言模型就會得到持續改進和發展。不過,僅靠增強計算資源並不能讓基礎模型自然生成價值觀,因此還需要註意模型與人類價值的對齊和安全性,這一點非常重要。
因此,與「 ChatGPT 」和「 Bard 」相比,Anthropic 的聊天機器人 「 Claude 」的優勢之一在於安全性和可控性。許多早期企業使用者希望模型的行為是可預測的,而且不會隨意編造事實,這些都是「 Claude 」設計時所考慮的。
「 Claude 」的獨特之處還在於「憲法式 AI 」(constitutional AI.)。與依賴「基於人類反饋的強化學習」的常見聊天機器人不同,「 憲法式 AI 」的核心思想是由一群人來評估和指導模型表現,明確指出哪些回答更好,來訓練出一個監督管理AI,進而為「 Claude 」進行標簽及反饋,這些評分被匯總起來以訓練模型按照使用者期望行動。「憲法式 AI 」允許使用者更透明地了解模型正在做什麽,也更容易被控制,確保其安全性。
(二)Anthropic的研究領域
1、AI能力方面
旨在使AI系統在任何型別的任務上變得更好的AI研究,包括寫作、影像處理或生成、玩遊戲等。使大型語言模型更高效或改進強化學習演算法的研究都屬於此類。這方面的工作會生成並改進Anthropic在對齊研究中調查和使用的模型。
2、對齊能力方面
對齊能力方面研究專註於開發新演算法,使AI系統在有用性、誠實性和無害性以及更可靠、穩健和與人類價值觀更一致方面變得更好。
Anthropic目前和過去進行的這類工作包括辯論、擴充套件自動化紅隊攻擊、憲法AI、消除偏見以及RLHF(基於人類反饋的強化學習)。這些技術通常具有實用價值和和經濟價值,但並非一定如此——例如,它們可能相對低效或僅在AI系統能力更強時才有用。
3、對齊科學方面
對齊科學方面主要關註評估與理解AI系統是否真正對齊,對齊能力技術的工作效果如何,以及我們能在多大程度上將這些技術的成功推廣到更有能力的AI系統。
Anthropic在這方面的工作包括機械可解釋性、用語言模型評估語言模型、紅隊攻擊和使用影響函式(見下文)研究大型語言模型中的泛化的工作。我們在誠實性方面的一些工作處於對齊科學與對齊能力之間的邊界。
對齊能力研究試圖開發新演算法,而對齊科學試圖理解和揭示它們的局限。如果AI安全問題確實能容易解決,那麽對齊能力工作可能是Anthropic最具影響力的研究。相反,如果對齊問題更困難,那麽將越來越依賴對齊科學來找到對齊能力技術的漏洞。如果對齊問題實際上幾乎不可能解決,那麽就需要對齊科學來建立一個非常強有力的論據,以阻止發展先進的AI系統。
(三)Anthropic的安全研究計畫
1、機制可解釋性
長久以來,我們都無從理解AI是如何進行決策和輸出的。模型開發人員只能決定演算法、數據,最後得到模型的輸出結果,而中間部份——模型是怎麽根據這些演算法和數據輸出結果,就成為了不可見的「黑箱」。
針對這個問題,Anthropic一直試圖將AI的神經網路逆向工程為人類可理解的演算法,Anthropic希望這最終可以使我們做類似於「程式碼審查」的事情,稽核我們的模型,以確定不安全的方面,或者提供強有力的安全保證。
目前階段,Anthropic團隊實作將小模型的神經元分解出可解釋特征,在小模型上實作一定的可解釋工作,Anthropic認為小模型上的成功意味著大模型同樣也可以解釋,對大模型黑箱的解釋將只是個工程問題。(在Anthropic的最新研究報告,Towards Monosemanticity: Decomposing Language Models With Dictionary Learning(【走向單語意性:用字典學習分解語言模型】),Anthropic團隊將包含512個神經元的層分解出了4000多個可解釋的特征。)
2、可延伸的監督
AI實作對齊,需要大量高品質的反饋資訊來引導。目前主要的問題是人類可能無法提供必要的反饋資訊。這既包括人類無法提供可靠的反饋來充分訓練模型,也包括人類可能會被AI系統愚弄,無法提供反映人類實際需求的反饋。這就是可延伸的監督問題,它可能是訓練安全的、對齊的AI系統的核心問題。
Anthropic認為提供必要監督的唯一方法,是讓AI系統部份自我監督,或協助人類進行自我監督。Anthropic將少量高品質的人類反饋資訊,訓練出高品質的負責監督AI。這個想法目前已經透過RLHF和CAI等技術顯示出前景。
憲法AI(Constitutional AI,CAI)
CAI是Anthropic公司理念的產物,CAI透過使用AI反饋來評估模型輸出內容,以應對語言模型的缺點。CAI使用一套基本原則來判斷產出,因此被稱為「憲法」。
Anthropic目前的憲法原則借鑒了一系列來源,包括【聯合國人權宣言】、信任和安全最佳實踐、其他人工智慧研究實驗室提出的原則、捕捉非西方觀點的努力,以及他們透過早期研究發現的行之有效的原則。
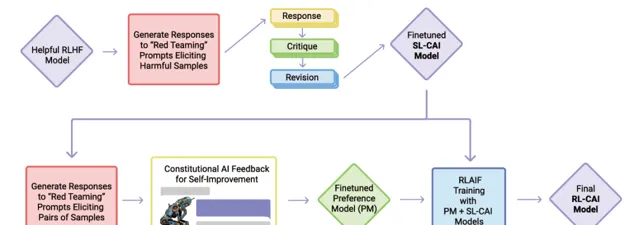
Anthropic用自己的憲法原則來訓練出CAI,再透過這個現成的語言模型來生成偏好標簽,對大模型進行監督反饋,代替傳統依賴人類反饋的方法。這種方法在文本摘要、有益對話生成和無害對話生成等任務上,已經顯示出與人類反饋訓練相當或更優的效能。
3、程序導向的學習
只要知道最終目的,反復試錯是學習新任務的一種好方法,可以不斷嘗試新的策略直到成功。Anthropic稱這種方法為「面向結果的學習」。在面向結果的學習中,智慧體的策略完全由期望的結果決定,並且智慧體將(在理想情況下)收斂於一些使其能夠實作這一目標的低成本策略。
4、理解泛化
大型語言模型已經展示了各種令人驚訝的湧現行為,從創造力到自我保護再到欺騙。當一個模型表現出令人擔憂的行為,例如扮演一個欺騙性對齊的AI角色,它只是對幾乎相同的訓練序列無害的機械重復?或者這種行為是否已經成為模型內核的一部份?Anthropic正在研究如何將模型的輸出追溯到訓練數據的技術,即模型是如何泛化的,以實作理解模型的行為表現。
5、檢測危險的失敗模式
高級AI可能會發展出有害的湧現行為,例如欺騙或戰略規劃能力,而這些行為在小模型中是不存在的。Anthropic致力於在此類問題成為直接威脅之前對其進行預測。目前,Anthropic主動將這些內容訓練成小型模型,以便隔離和研究這種危險AI的行為模式。
Anthropic的目標是定量分析建立這些趨勢如何隨規模而變化,使我們可以提前預測突然湧現的危險失敗模式。
6、社會影響和評估
Anthropic非常關註日益強大的AI系統的快速部署將如何在短期、中期和長期影響社會。目前正在開展各種計畫,以評估和減輕AI系統中潛在的有害行為,預測它們被使用的方式,並研究它們的經濟影響。這項研究也為Anthropic制定負責任的AI政策和治理的工作提供了資訊。
透過對當今AI的影響進行嚴格的研究,Anthropic旨在為政策制定者和研究人員提供他們所需的見解和工具,以幫助減輕這些潛在的重大社會危害,並確保AI的益處在整個社會中被廣泛而均勻地分配。
六、估值及融資情況
(一)估值及融資情況
Anthropic最新融資估值達184億美元,歷史融資合計超75億美元。
A輪融資:2021年5月,Anthropic 宣布完成了 A 輪融資,金額為 1.24 億美元。此輪融資由 Skype 聯合創始人 Jaan Tallinn 領投,其他支持者包括 Facebook 和 Asana 聯合創始人 Dustin Moskovitz、前谷歌執行長 Eric Schmidt。
B輪融資:2022年4月,Anthropic宣布完成了 B 輪融資,金額為 5.8 億美元。此輪融資由 FTX 執行長 Sam Bankman-Fried 領投。
戰略投資:2023年2月,谷歌向 Anthropic 投資了約 3 億美元,以換取該公司 10% 的股份,並要求 Anthropic 將谷歌雲作為其首選雲服務提供商。
C輪融資:2023年5月,Anthropic 宣布完成了 C 輪融資,金額為 4.5 億美元。領投方為 Spark Capital,參與方包括 Google、Salesforce 透過其子公司 Salesforce Ventures 以及 Zoom 透過 Zoom Ventures。此外,還有 Sound Ventures、Menlo Ventures 和其他未披露的投資方。
戰略投資:2023年8月,南韓最大的移動營運商之一 SK Telecom(SKT)宣布投資了 1 億美元。
戰略投資:2023年9月,亞馬遜宣布與 Anthropic 正式展開戰略合作,並承諾投資 40 億美元。Anthropic 將透過亞馬遜的雲端運算服務為其客戶提供生成式 AI 服務,並使用 AWS Trainium 和 Inferentia 芯片。
追加投資:2023年10月,谷歌同意對 Anthropic 追加最高 20 億美元的投資,其中包括 5 億美元的預付現金註入,剩余的 15 億美元將隨著時間的推移追加投資。Anthropic本輪估值達184億美元。
(二)財務情況
收入情況
由於Anthropic未上市,其財務情況主要透過訪談或者媒體新聞了解。
根據Anthropic和投資人洽談訊息,2023年年化收入實作 2 億美元(2023年10月預測數)。
據外媒The Information報道,Anthropic預測2024年底年化收入將超過8.5億美元。
毛利率情況
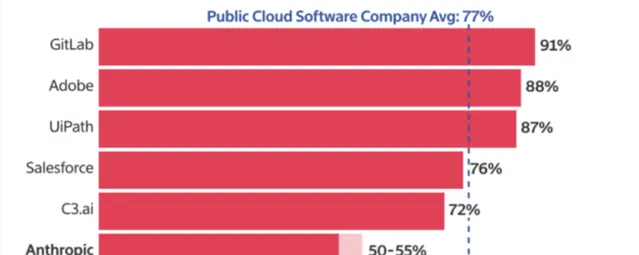
根據 Information 報道,在支付客戶支持和AI 伺服器成本後,2023年12月Anthropic的毛利率在50%—55%,根據Meritech Capital的數據,這遠低於雲軟體公司77%的平均毛利率。
還有一位重要股東預測,Anthropic長期毛利率將在60%左右,且該毛利率未反映訓練 AI 模型的伺服器成本,因為這些成本是被 Anthropic 納入其研發費用中。
小結
Anthropic 作為一家專註於AI安全性和負責任開發的公司,憑借其由GPT系列產品早期開發者組成的創始團隊,在AI領域展現出了強大的創新能力和深厚的技術積累。
公司推出的Claude系列模型在處理長文本和特定領域問題上取得了顯著進展,其「憲法式AI」等創新方法體現了對AI安全性和可控性的高度重視。此外,Anthropic在AI的社會影響評估和負責任的AI政策制定上也表現出了前瞻性,走出自身差異化優勢。
同時,我們也關註到,公司的大模型與同業之間差異化還不明顯,公司毛利率及盈利能力相對估值來說還有較大壓力。未來,Anthropic如何在保持技術領先優勢的同時,進一步實作商業化和社會責任的平衡,將是其持續發展的關鍵。
• END•
↓↓↓
我們也開始卷老板了~
更多AI幹貨,關註老胡看AI











