小夥伴們好啊,今天咱們再來學習幾個常用函式公式的典型用法:
1、根據日期返回季度
如下圖所示,需要根據A列的日期,返回該日期所屬的季度。
B2單元格輸入以下公式,向下復制。
=MATCH(MONTH(A2),{0,4,7,10})
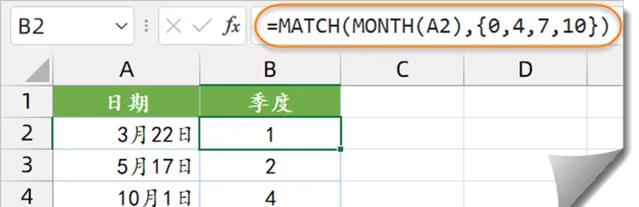
首先用MONTH函式計算出A2單元格所屬的月份,結果為3。
再使用MATCH函式,計算該月份在常量陣列{0,4,7,10}中所處的位置。{0,4,7,10},是各個季度的起始月份。
本例中MATCH函式省略了第三參數,其計算規則與使用參數1時相同,當尋找不到對應的內容時,會以小於尋找值的最接近的一個進行匹配,並返回對應的位置資訊。
MATCH函式在常量陣列{0,4,7,10}中找不到3,因此以小於3的最接近值0進行匹配,並返回0在常量陣列{0,4,7,10}中的位置,結果為1。
2、科目拆分
如下圖,需要按分隔符「/」,來拆分A列中的會計科目。
B2輸入以下公式,下拉即可。
=TEXTSPLIT(A2,"/")
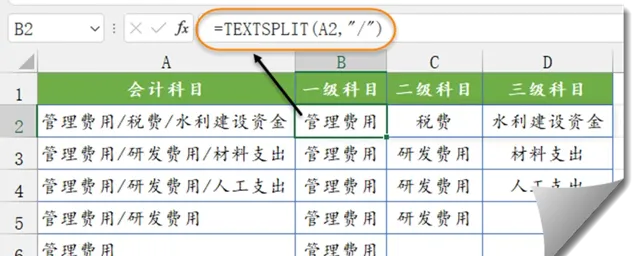
本例中,TEXTSPLIT的第二參數使用"/"作為列分隔符號,其他參數省略。
3、隨機不重復數
如下圖,要根據A列的姓名,生成隨機面試順序。
B2單元格輸入以下公式:
=SORTBY(SEQUENCE(9),RANDARRAY(9))
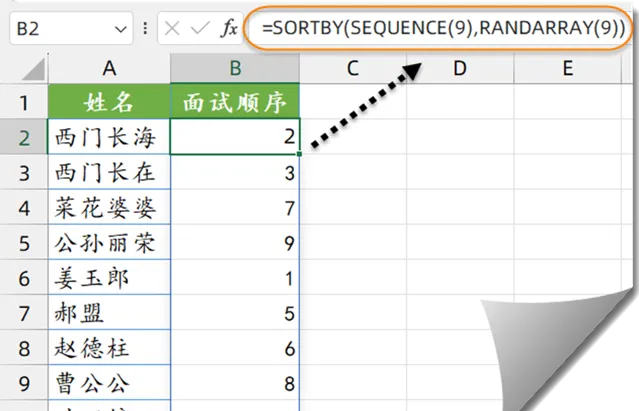
先使用SEQUENCE(9),生成1~9的連續序號。再使用RANDARRAY(9),生成9個隨機小數。最後使用SORTBY函式,以隨機小數為排序依據,對序號進行排序。
4、在不連續區域提取不重復值
如下圖所示,希望從左側值班表中提取出不重復的員工名單。
其中A列和C列為姓名,B列和D列為值班電話。
F2單元格輸入以下公式:
=UNIQUE(VSTACK(A2:A7,C2:C7))
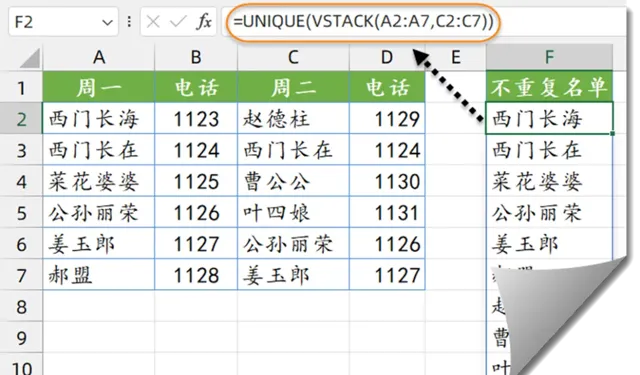
先使用VSTACK函式,把A2:A7和C2:C7兩個不相鄰的區域合並為一列,然後使用UNIQUE提取出不重復的記錄。
5、按自訂序列排序
如下圖,A~C列是一些員工資訊,希望按照E列指定的部門順序進行排序,同一部門的,再按年齡從大到小排序。
先將標題復制到右側的空白單元格內,然後在第一個標題下方輸入公式:
=SORTBY(A2:C21,MATCH(B2:B21,E2:E7,),1,C2:C21,-1)
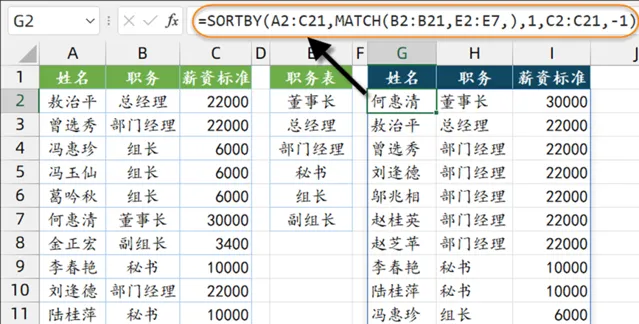
公式中的MATCH(B2:B21,E2:E7,)部份,分別查詢B列職務在E2:E7區域中的位置,結果是這樣的:
{2;3;5;5;5;1;6;4;3;4;5;6;5;5;3;6;5;6;3;3}
這一步的目的,實際上就是將B列的職務變成了E列的排列順序號。總經理成了2,部門經理變成了3……
接下來的過程就清晰了:
SORTBY的排序區域為C2:C21單元格中的數據,排序依據是優先對部門順序號升序排序,再對年齡執行升序排序。
好了,咱們今天就分享這些吧,祝各位一天好心情。
圖文制作:祝洪忠











